Et enkelt fejlpunkt (SPOF) er en almindelig årsag til, at organisationer arbejder på at distribuere tilstedeværelsen af deres databasemiljøer til et andet sted geografisk. Det er en del af de strategiske planer for Disaster Recovery og Business Continuity.
Disaster Recovery (DR) planlægning omfatter tekniske procedurer, som dækker forberedelsen til uforudsete problemer såsom naturkatastrofer, ulykker (såsom menneskelige fejl) eller hændelser (såsom kriminelle handlinger).
I det sidste årti har distribution af dit databasemiljø på tværs af flere geografiske placeringer været en ret almindelig opsætning, da offentlige skyer tilbyder mange måder at håndtere dette på. Udfordringen ligger i at opsætte databasemiljøer. Det skaber udfordringer, når du forsøger at administrere databasen/databaserne, flytte dine data til en anden geo-placering eller anvende sikkerhed med et højt niveau af observerbarhed.
I denne blog viser vi, hvordan du kan gøre dette ved hjælp af MySQL-replikering. Vi vil dække, hvordan du er i stand til at kopiere dine data til en anden databaseknude, der er placeret i et andet land fjernt fra MySQL-klyngens nuværende geografi. I dette eksempel er vores målregion baseret på os-øst, mens min on-prem er i Asien i Filippinerne.
Hvorfor har jeg brug for en Geo-Location Database Cluster?
Selv Amazon AWS, den førende offentlige cloud-udbyder, hævder, at de lider af nedetid eller utilsigtede udfald (som den, der skete i 2017). Lad os sige, at du bruger AWS som dit sekundære datacenter bortset fra dit on-prem. Du kan ikke have nogen intern adgang til dens underliggende hardware eller til de interne netværk, der administrerer dine computerknudepunkter. Disse er fuldt administrerede tjenester, som du har betalt for, men du kan ikke undgå, at det når som helst kan lide under en fejl. Hvis en sådan geografisk placering lider af et afbrydelse, kan du have en lang nedetid.
Denne type problemer skal forudses under din forretningskontinuitetsplanlægning. Det skal være analyseret og implementeret ud fra det definerede. Forretningskontinuitet for dine MySQL-databaser bør omfatte høj oppetid. Nogle miljøer laver benchmarks og sætter en høj bar af strenge tests inklusive den svage side for at afsløre enhver sårbarhed, hvor modstandsdygtig den kan være, og hvor skalerbar din teknologiarkitektur inklusive din databaseinfrastruktur. For virksomheder, især dem, der håndterer høje transaktioner, er det bydende nødvendigt at sikre, at produktionsdatabaser er tilgængelige for applikationerne hele tiden, selv når en katastrofe indtræffer. Ellers kan der opleves nedetid, og det kan koste dig mange penge.
Med disse identificerede scenarier begynder organisationer at udvide deres infrastruktur til forskellige cloud-udbydere og placere noder til forskellige geografiske placeringer for at få mere høj oppetid (hvis muligt på 99.99999999999), lavere RPO og har ingen SPOF.
For at sikre, at produktionsdatabaser overlever en katastrofe, skal et Disaster Recovery (DR) websted konfigureres. Produktions- og DR-sites skal være en del af to geografisk fjerntliggende datacentre. Det betyder, at der skal konfigureres en standby-database på DR-stedet for hver produktionsdatabase, således at de dataændringer, der sker på produktionsdatabasen, straks synkroniseres til standby-databasen via transaktionslogs. Nogle opsætninger bruger også deres DR-noder til at håndtere læsninger for at give belastningsbalancering mellem applikationen og datalaget.
Den ønskede arkitektoniske opsætning
I denne blog er den ønskede opsætning enkel og alligevel meget almindelig implementering i dag. Se nedenfor om den ønskede arkitektoniske opsætning for denne blog:
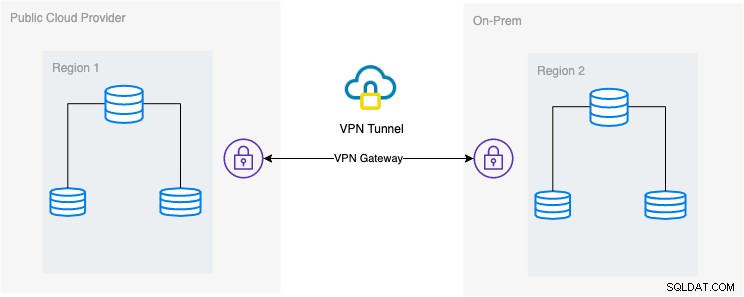
I denne blog vælger jeg Google Cloud Platform (GCP) som offentligheden cloud-udbyder og bruger mit lokale netværk som mit on-prem databasemiljø.
Det er et must, at når du bruger denne type design, har du altid brug for både miljø eller platform til at kommunikere på en meget sikker måde. Brug af VPN eller brug af alternativer såsom AWS Direct Connect. Selvom disse offentlige skyer i dag tilbyder administrerede VPN-tjenester, som du kan bruge. Men til denne opsætning vil vi bruge OpenVPN, da jeg ikke har brug for sofistikeret hardware eller service til denne blog.
Bedste og mest effektive måde
For MySQL/Percona/MariaDB-databasemiljøer er den bedste og effektive måde at tage en sikkerhedskopi af din database, sende til målknuden, der skal implementeres eller instansieres. Der er forskellige måder at bruge denne tilgang på, enten kan du bruge mysqldump, mydumper, rsync eller bruge Percona XtraBackup/Mariabackup og streame dataene til din målknude.
Brug af mysqldump
mysqldump opretter en logisk sikkerhedskopi af hele din database, eller du kan selektivt vælge en liste over databaser, tabeller eller endda specifikke poster, som du ønskede at dumpe.
En simpel kommando, som du kan bruge til at tage en fuld backup, kan være,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsMed denne enkle kommando vil den køre MySQL-sætningerne direkte til måldatabasenoden, for eksempel din måldatabaseknude på en Google Compute Engine. Dette kan være effektivt, når data er mindre, eller du har en hurtig båndbredde. Ellers kan det være din mulighed at pakke din database til en fil og derefter sende den til målnoden.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathKør derefter mysqldump til måldatabasenoden som sådan,
zcat mydata.db | mysqlUlempen ved at bruge logisk backup ved hjælp af mysqldump er, at den er langsommere og bruger diskplads. Den bruger også en enkelt tråd, så du kan ikke køre dette parallelt. Du kan eventuelt bruge mydumper, især når dine data er for store. mydumper kan køres parallelt, men den er ikke så fleksibel sammenlignet med mysqldump.
Brug af xtrabackup
xtrabackup er en fysisk backup, hvor du kan sende streams eller binær til målknuden. Dette er meget effektivt og bruges mest, når der streames en sikkerhedskopi over netværket, især når målknuden er af en anden geografi eller en anden region. ClusterControl bruger xtrabackup, når en ny slave klargøres eller instantieres, uanset hvor den er placeret, så længe adgang og tilladelse er blevet konfigureret før handlingen.
Hvis du bruger xtrabackup til at køre det manuelt, kan du køre kommandoen som sådan,
## Målknude
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Kildeknude
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999For at uddybe disse to kommandoer skal den første kommando udføres eller køres først på målknuden. Målknudekommandoen lytter på port 9999 og vil skrive enhver strøm, der modtages fra port 9999 i målknudepunktet. Det er afhængigt af kommandoerne socat og xbstream, hvilket betyder, at du skal sikre dig, at du har disse pakker installeret.
På kildenoden udfører den innobackupex perl-scriptet, som kalder xtrabackup i baggrunden og bruger xbstream til at streame de data, der sendes over netværket. Socat-kommandoen åbner porten 9999 og sender dens data til den ønskede vært, som er 192.168.10.70 i dette eksempel. Sørg stadig for, at du har socat og xbstream installeret, når du bruger denne kommando. Alternativ måde at bruge socat på er nc, men socat tilbyder mere avancerede funktioner sammenlignet med nc såsom serialisering, ligesom flere klienter kan lytte på en port.
ClusterControl bruger denne kommando, når man genopbygger en slave eller bygger en ny slave. Det er hurtigt og garanterer, at den nøjagtige kopi af dine kildedata vil blive kopieret til din målknude. Når du klargør en ny database til en separat geo-placering, giver brugen af denne tilgang mere effektivitet og giver dig mere hastighed til at afslutte jobbet. Selvom der kan være fordele og ulemper ved brug af logisk eller binær backup, når den streames gennem ledningen. Brug af denne metode er en meget almindelig tilgang, når du opsætter en ny geo-lokationsdatabaseklynge til en anden region og opretter en nøjagtig kopi af dit databasemiljø.
Effektivitet, observerbarhed og hastighed
Spørgsmål efterladt af de fleste mennesker, som ikke er bekendt med denne tilgang, dækker altid "HVORDAN, HVAD, HVOR"-problemerne. I dette afsnit vil vi dække, hvordan du effektivt kan opsætte din geo-placeringsdatabase med mindre arbejde at håndtere og med observerbarhed, hvorfor den fejler. Det er meget effektivt at bruge ClusterControl. I denne nuværende opsætning har jeg følgende miljø som oprindeligt implementeret:
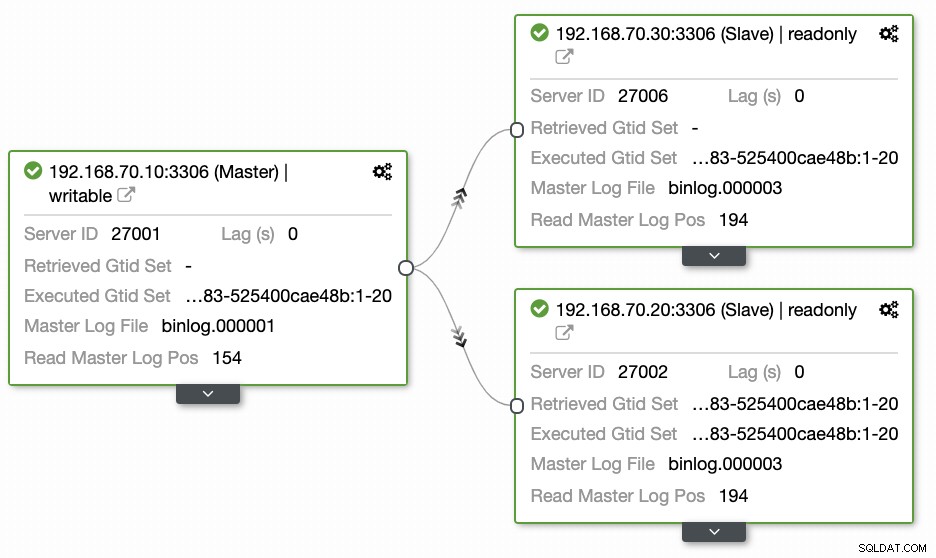
Udvidelse af node til GCP
Begynder at konfigurere din geo-placeringsdatabaseklynge, for at udvide din klynge og oprette en snapshot-kopi af din klynge, kan du tilføje en ny slave. Som tidligere nævnt vil ClusterControl bruge xtrabackup (mariabackup til MariaDB 10.2 og frem) og implementere en ny node i din klynge. Før du kan registrere dine GCP-beregningsknuder som dine målknuder, skal du først konfigurere den relevante systembruger på samme måde som den systembruger, du registrerede i ClusterControl. Du kan bekræfte dette i din /etc/cmon.d/cmon_X.cnf, hvor X er cluster_id. Se f.eks. nedenfor:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (i dette eksempel) skal være til stede i dine GCP-beregningsknuder. Brugeren i dine GCP-noder skal have sudo- eller superadministratorrettigheder. Det skal også konfigureres med en adgangskodefri SSH-adgang. Læs venligst vores dokumentation mere om systembrugeren og dens nødvendige privilegier.
Lad os få en eksempelliste over servere nedenfor (fra GCP-konsollen:Compute Engine-dashboard):
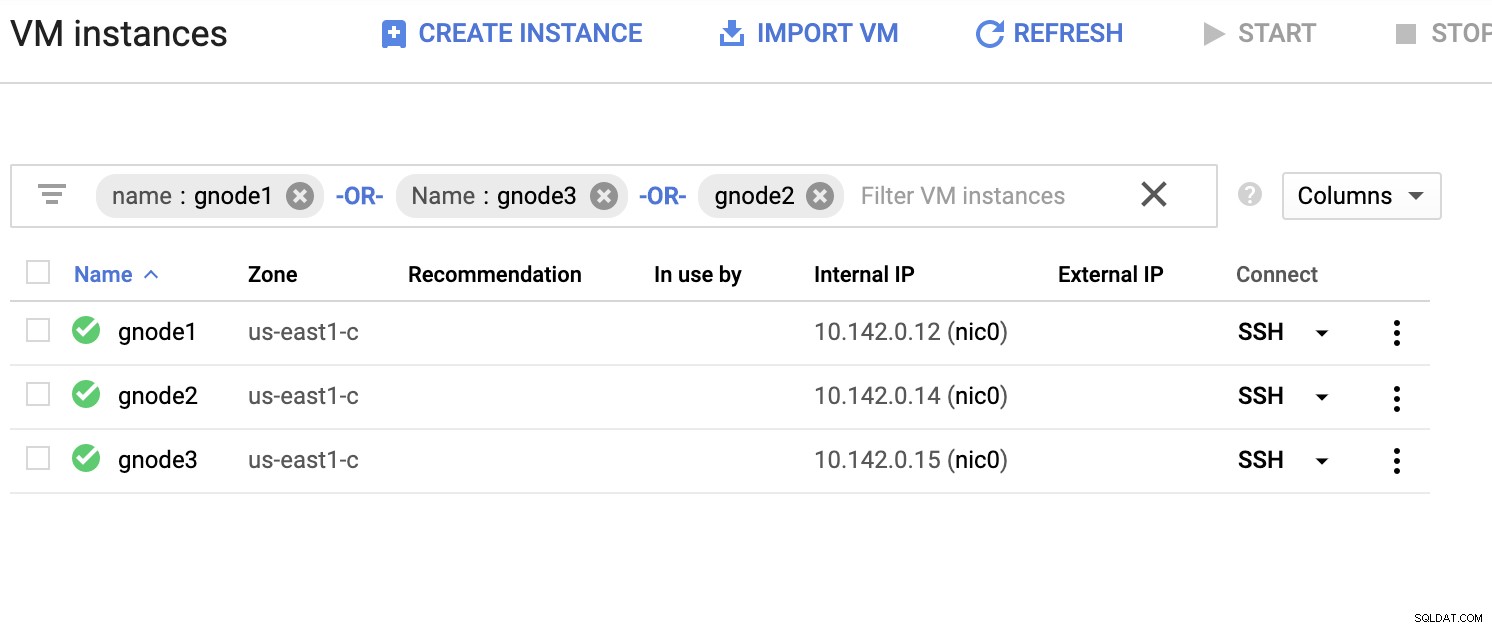
I skærmbilledet ovenfor er vores målregion baseret på os-øst område. Som nævnt tidligere er mit lokale netværk sat op over et sikkert lag, der går gennem GCP (omvendt) ved hjælp af OpenVPN. Så kommunikation fra GCP, der går til mit lokale netværk, er også indkapslet over VPN-tunnelen.
Tilføj en slavenode til GCP
Skærmbilledet nedenfor afslører, hvordan du kan gøre dette. Se billeder nedenfor:
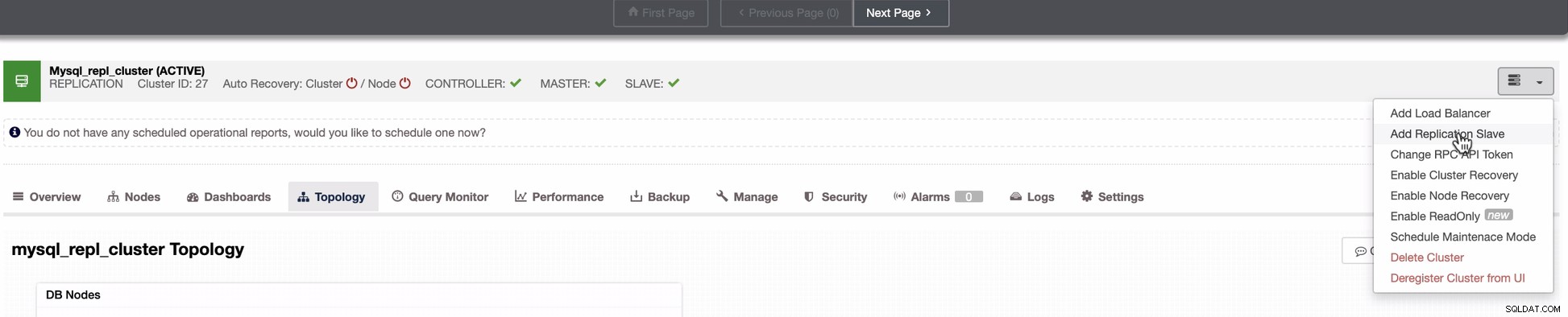
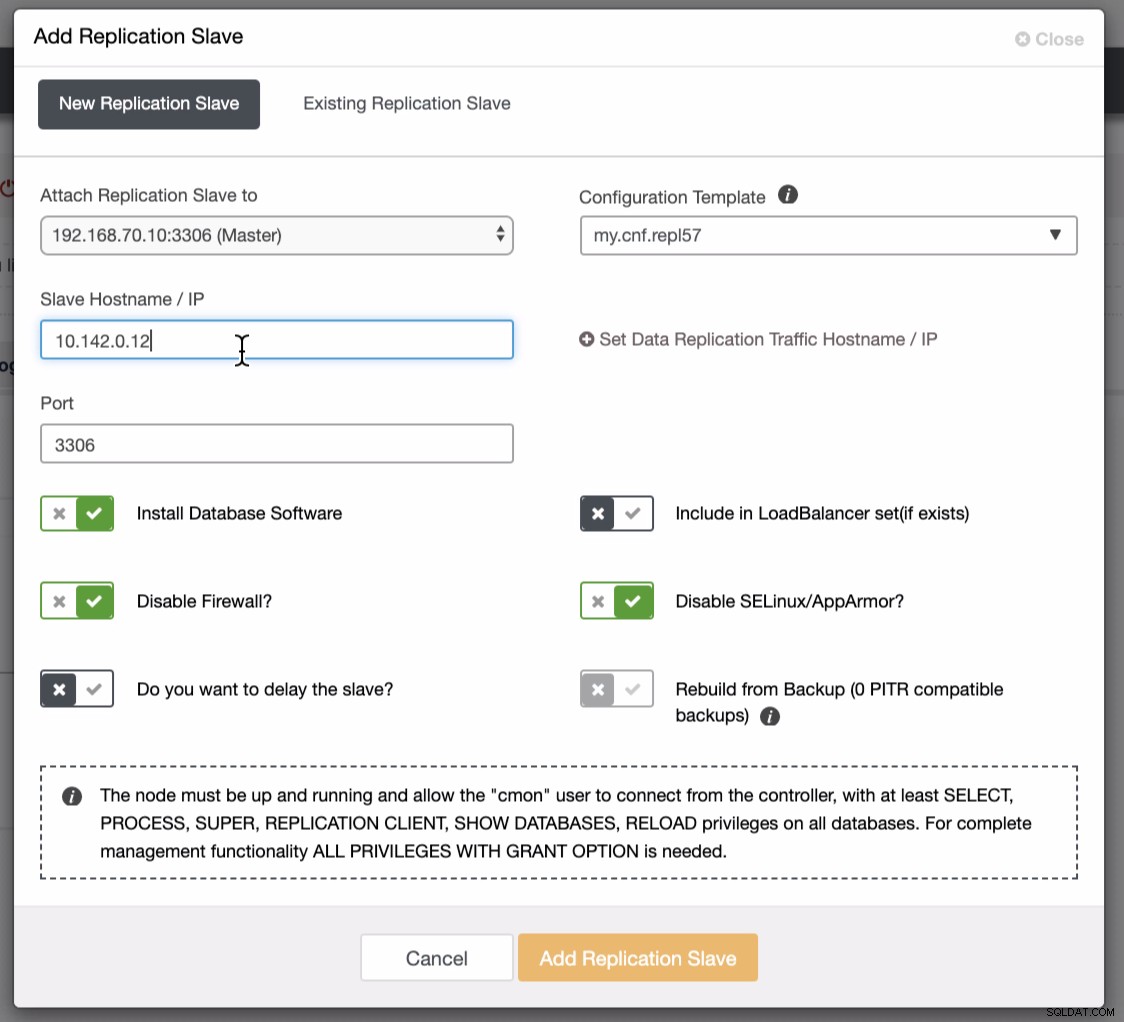
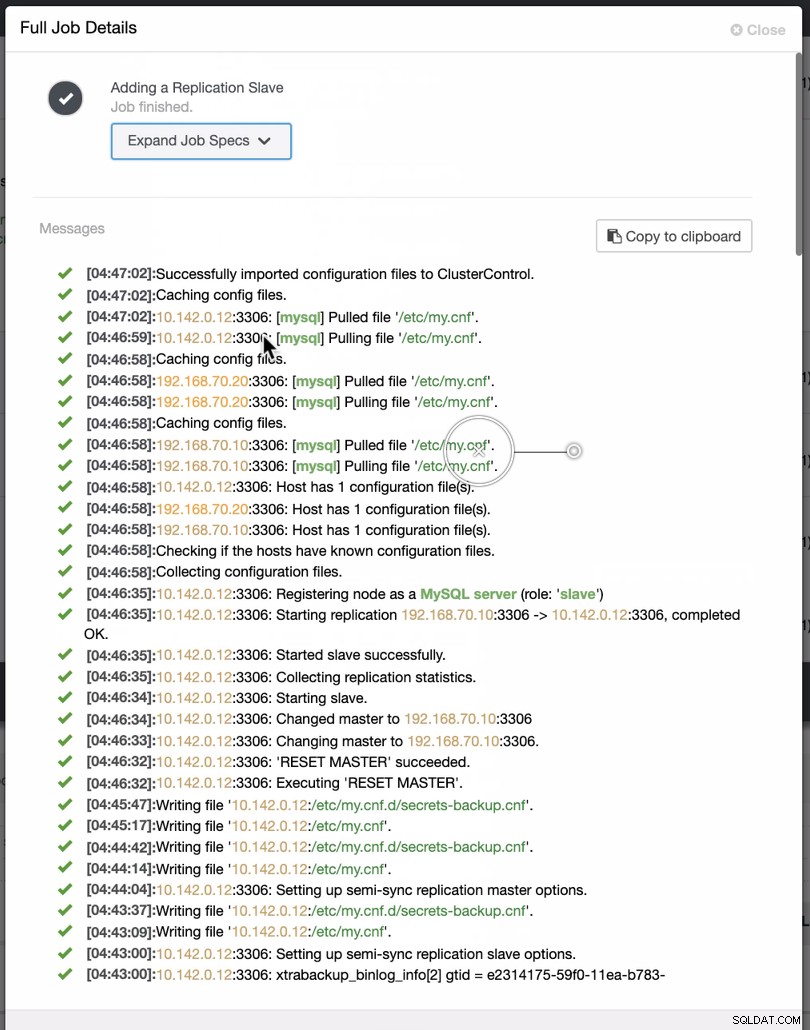
Som det fremgår af det andet skærmbillede, målretter vi mod node 10.142.0.12 og dens kildemester er 192.168.70.10. ClusterControl er smart nok til at bestemme firewalls, sikkerhedsmoduler, pakker, konfiguration og opsætning, der skal udføres. Se nedenfor et eksempel på jobaktivitetslog:
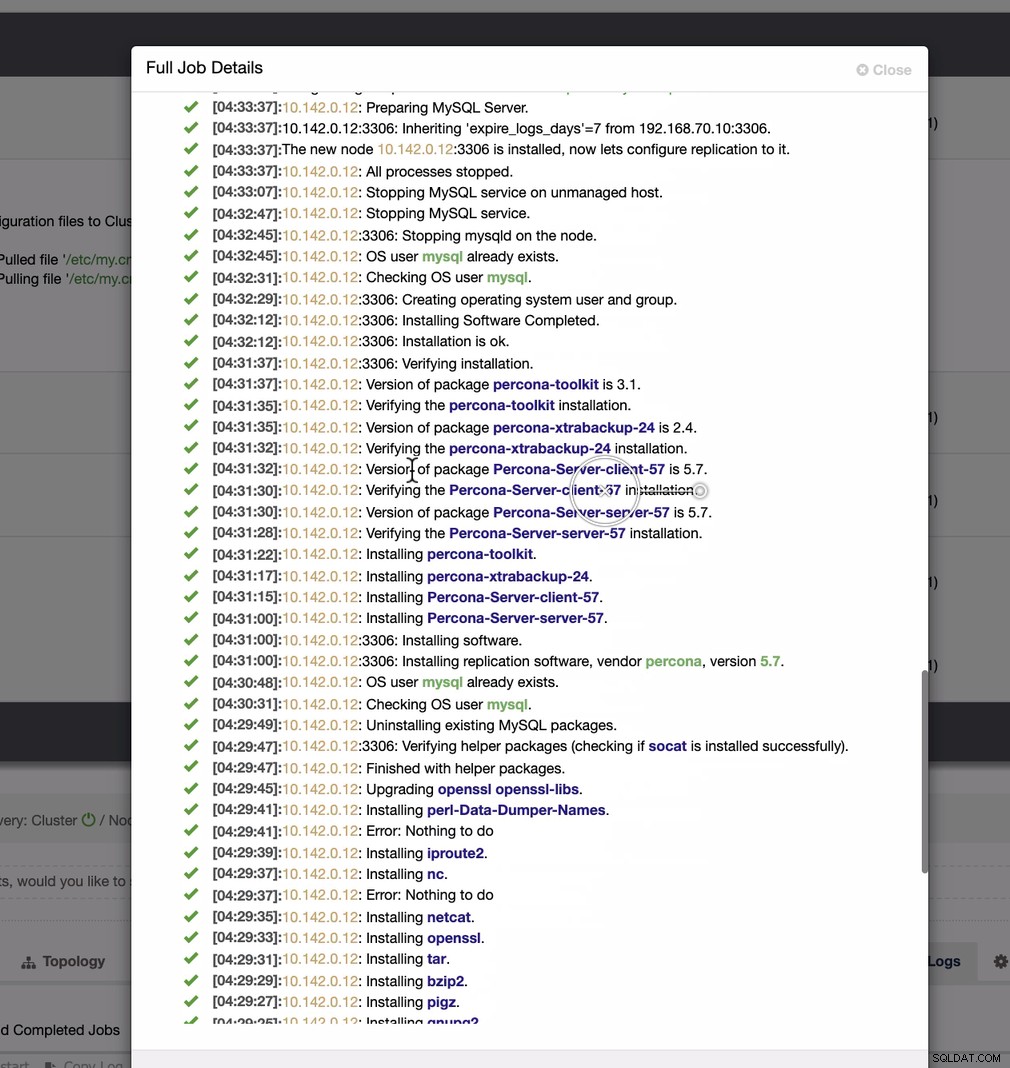
En ret simpel opgave, ikke?
Fuldfør GCP MySQL-klyngen
Vi er nødt til at tilføje to noder mere til GCP-klyngen for at have en balancetopologi, som vi havde i det lokale netværk. For den anden og tredje node skal du sikre dig, at masteren skal pege på din GCP-node. I dette eksempel er masteren 10.142.0.12. Se nedenfor, hvordan du gør dette,
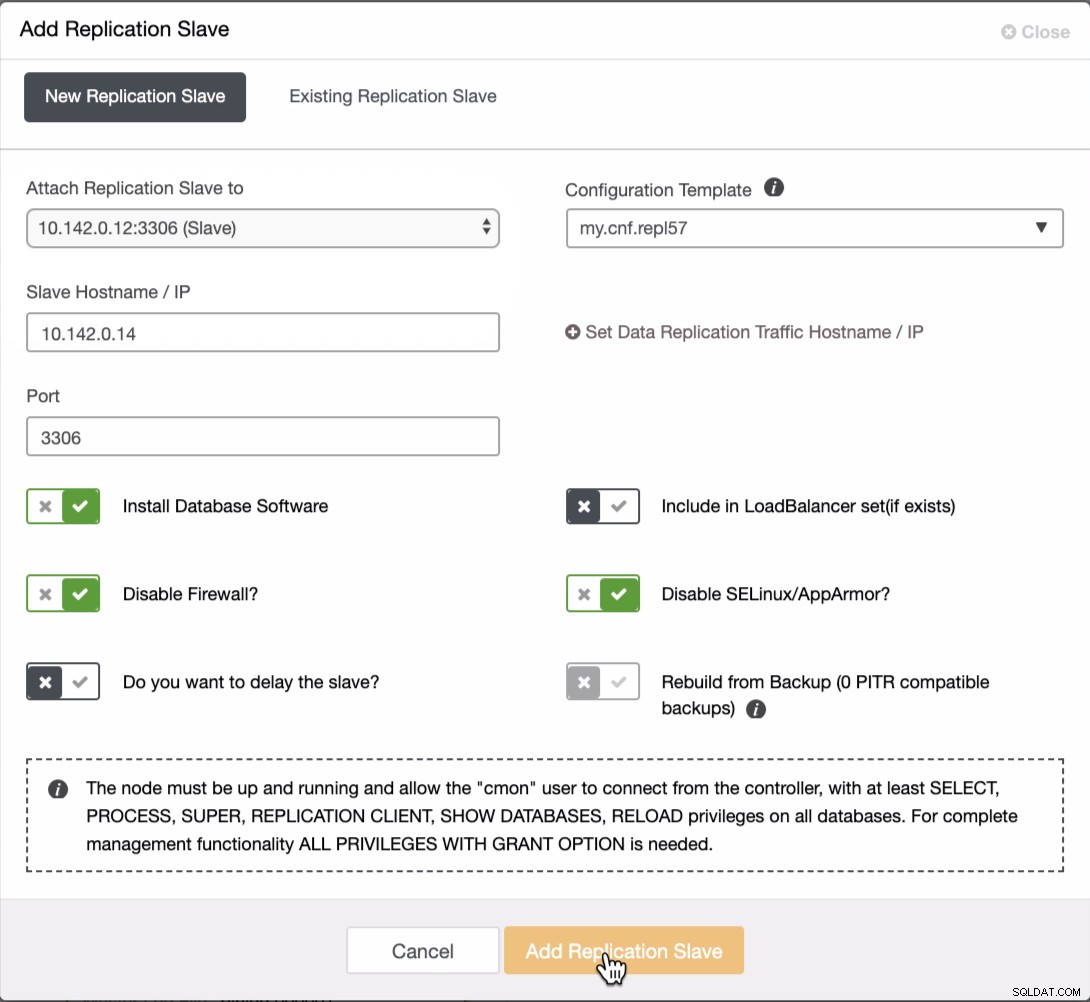
Som det ses på skærmbilledet ovenfor, valgte jeg 10.142.0.12 (slave) ), som er den første node, vi har tilføjet til klyngen. Det komplette resultat viser som følger,
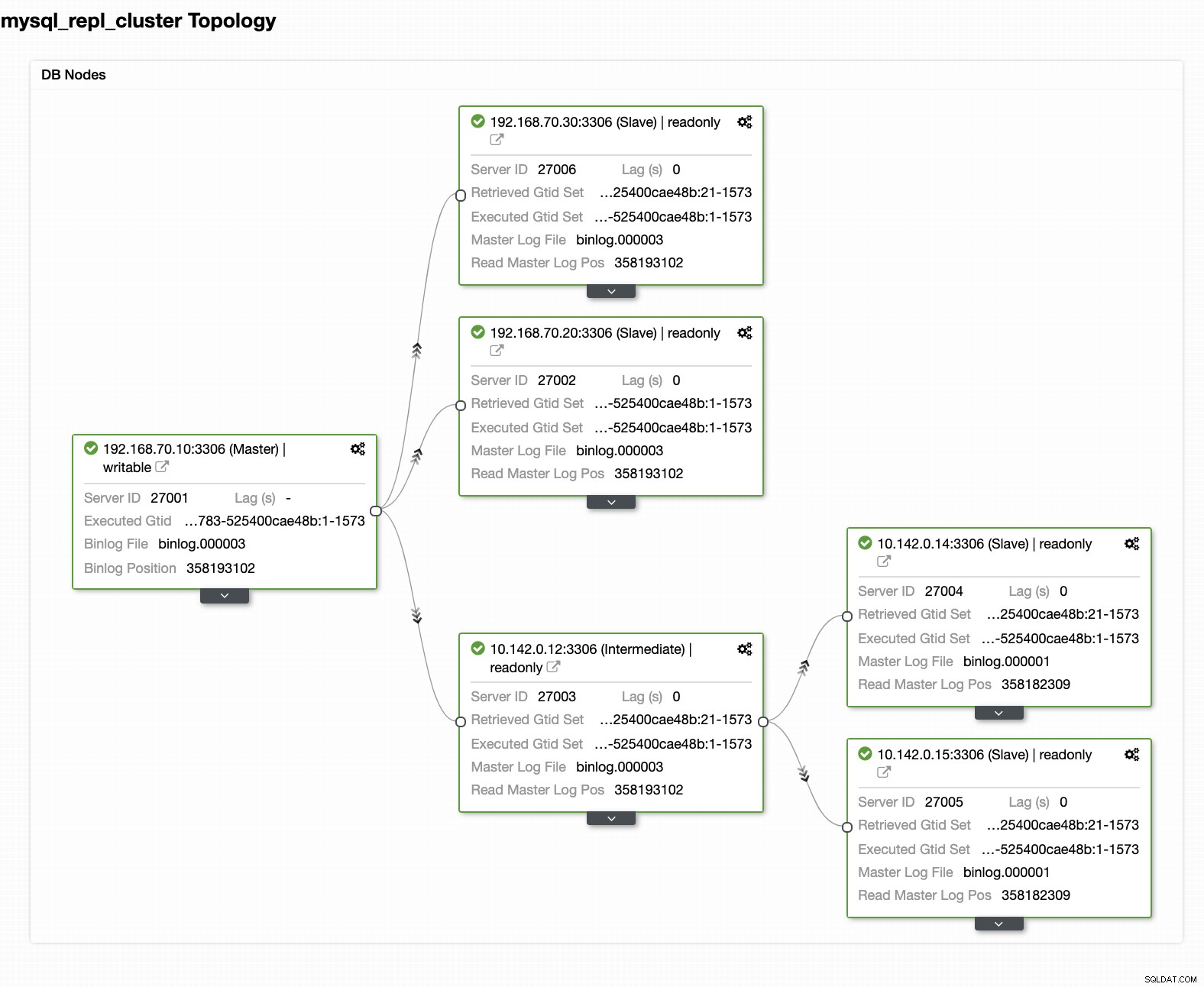
Din endelige opsætning af Geo-Location Database Cluster
Fra det sidste skærmbillede er denne form for topologi muligvis ikke din ideelle opsætning. For det meste skal det være en multi-master opsætning, hvor din DR-klynge fungerer som standby-klyngen, hvor din on-prem fungerer som den primære aktive klynge. For at gøre dette er det ganske enkelt i ClusterControl. Se følgende skærmbilleder for at nå dette mål.
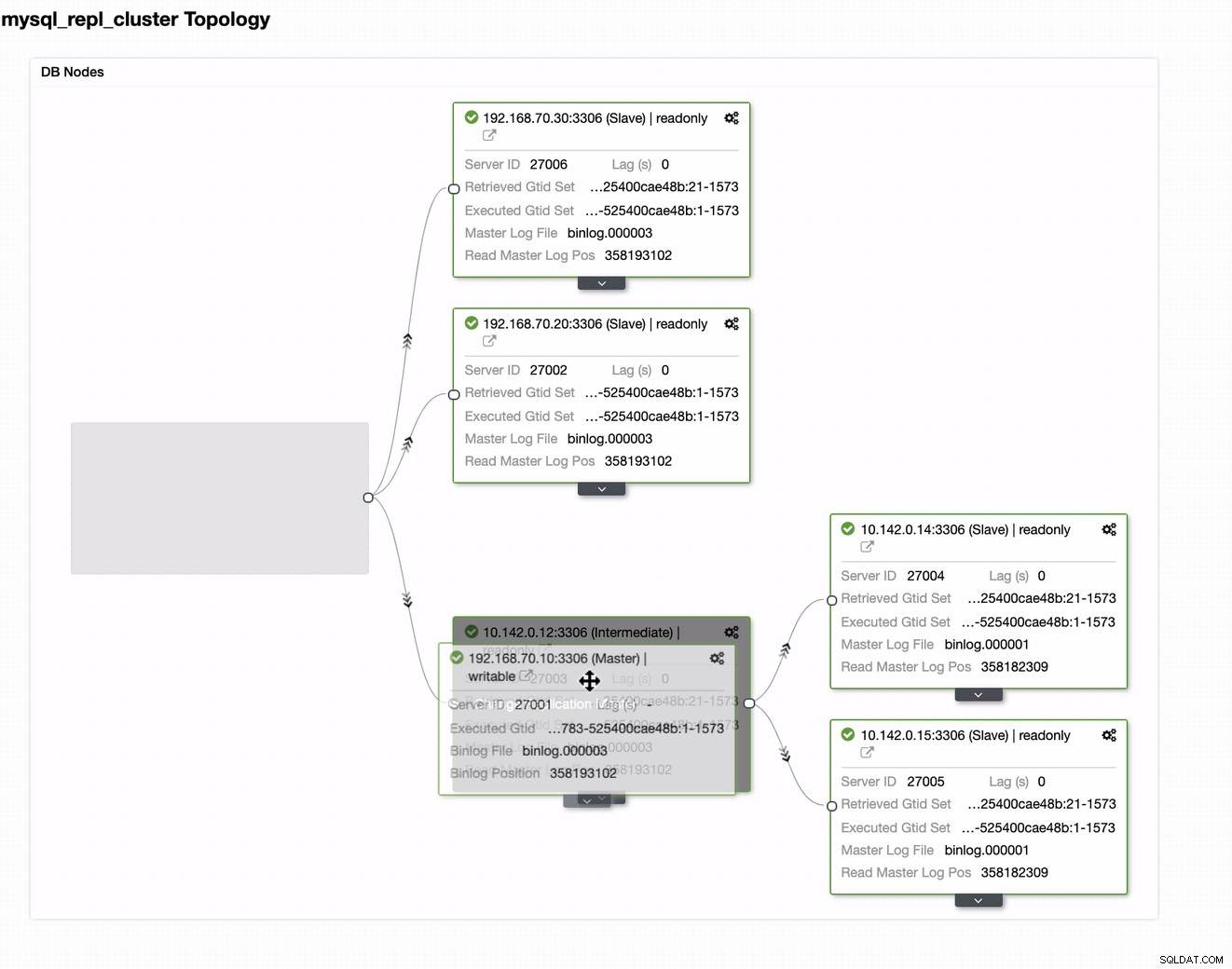
Du kan bare trække din nuværende master til målmasteren, der skal være opsætning som en primær standby-skribent, hvis din on-prem kommer til skade. I dette eksempel trækker vi målretningsvært 10.142.0.12 (GCP compute node). Slutresultatet er vist nedenfor:
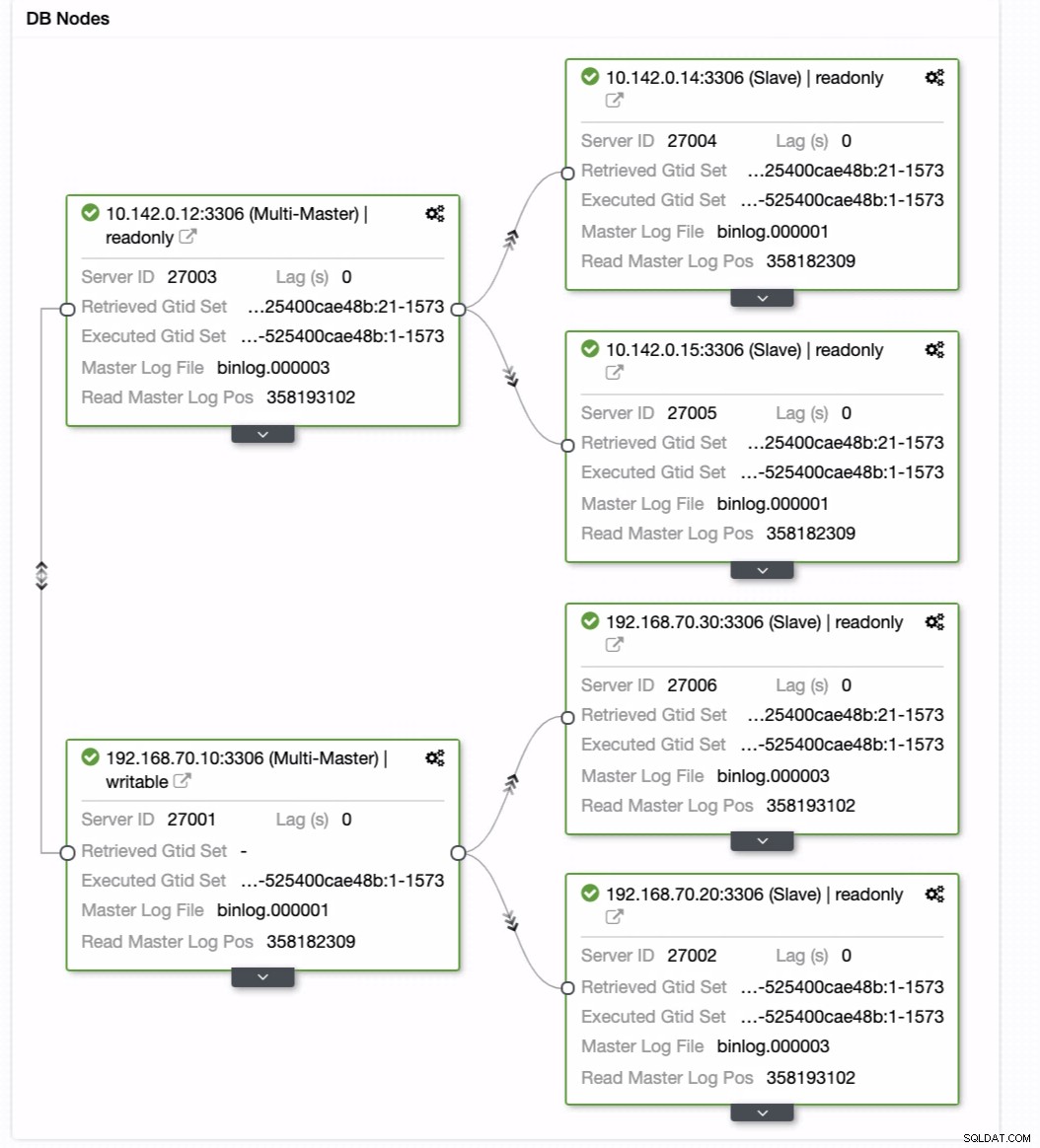
Så opnår den det ønskede resultat. Nemt og meget hurtigt at skabe din Geo-Location Database-klynge ved hjælp af MySQL-replikering.
Konklusion
At have en Geo-Location Database Cluster er ikke nyt. Det har været et ønsket setup for virksomheder og organisationer, der undgår SPOF, som ønsker robusthed og en lavere RPO.
De vigtigste takeaways for denne opsætning er sikkerhed, redundans og modstandsdygtighed. Det dækker også, hvor gennemførligt og effektivt du kan implementere din nye klynge til en anden geografisk region. Selvom ClusterControl kan tilbyde dette, kan du forvente, at vi kan få flere forbedringer på dette tidligere, hvor du kan oprette effektivt fra en backup og skabe din nye anderledes klynge i ClusterControl, så følg med.