I kommentarfeltet på en af vores blogs spurgte en læser om virkningen af wsrep_slave_threads på Galera Clusters I/O-ydeevne og skalerbarhed. På det tidspunkt kunne vi ikke nemt besvare det spørgsmål og sikkerhedskopiere det med flere data, men til sidst lykkedes det os at konfigurere miljøet og køre nogle tests.
Vores læser pegede på benchmarks, der viste, at forøgelse af wsrep_slave_threads ikke havde nogen indflydelse på Galera-klyngens ydeevne.
For at forklare, hvad virkningen af denne indstilling er, opsætter vi en lille klynge af tre noder (m5d.xlarge). Dette gjorde det muligt for os at bruge direkte vedhæftede nvme SSD til MySQL-datamappen. Ved at gøre dette minimerede vi chancen for, at opbevaring bliver flaskehalsen i vores opsætning.
Vi sætter InnoDB-bufferpuljen op til 8 GB og gentager logfiler til to filer, 1 GB hver. Vi øgede også innodb_io_capacity til 2000 og innodb_io_capacity_max til 10000. Dette var også beregnet til at sikre, at ingen af disse indstillinger ville påvirke vores ydeevne.
Hele problemet med sådanne benchmarks er, at der er så mange flaskehalse, at du er nødt til at fjerne dem én efter én. Først efter at have foretaget nogle konfigurationsjusteringer og efter at have sikret sig, at hardwaren ikke vil være et problem, kan man have håb om, at nogle mere subtile grænser vil dukke op.
Vi genererede ~90 GB data ved hjælp af sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareSå blev benchmark eksekveret. Vi testede to indstillinger:wsrep_slave_threads=1 og wsrep_slave_threads=16. Hardwaren var ikke kraftig nok til at drage fordel af at øge denne variabel endnu mere. Husk også, at vi ikke lavede en detaljeret benchmarking for at afgøre, om wsrep_slave_threads skal indstilles til 16, 8 eller måske 4 for den bedste ydeevne. Vi var interesserede i at se, om vi kan vise en indvirkning på klyngen. Og ja, virkningen var tydeligt synlig. Til at begynde med, nogle flowkontrolgrafer.
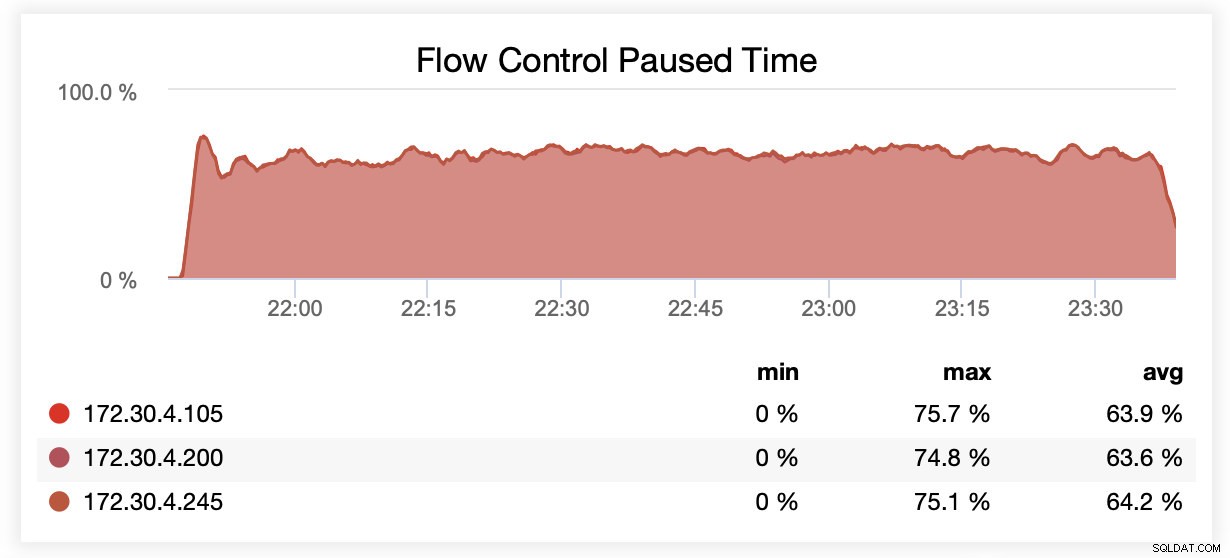
Mens du kørte med wsrep_slave_threads=1, blev noder i gennemsnit sat på pause på grund af flowkontrol ~64 % af tiden.
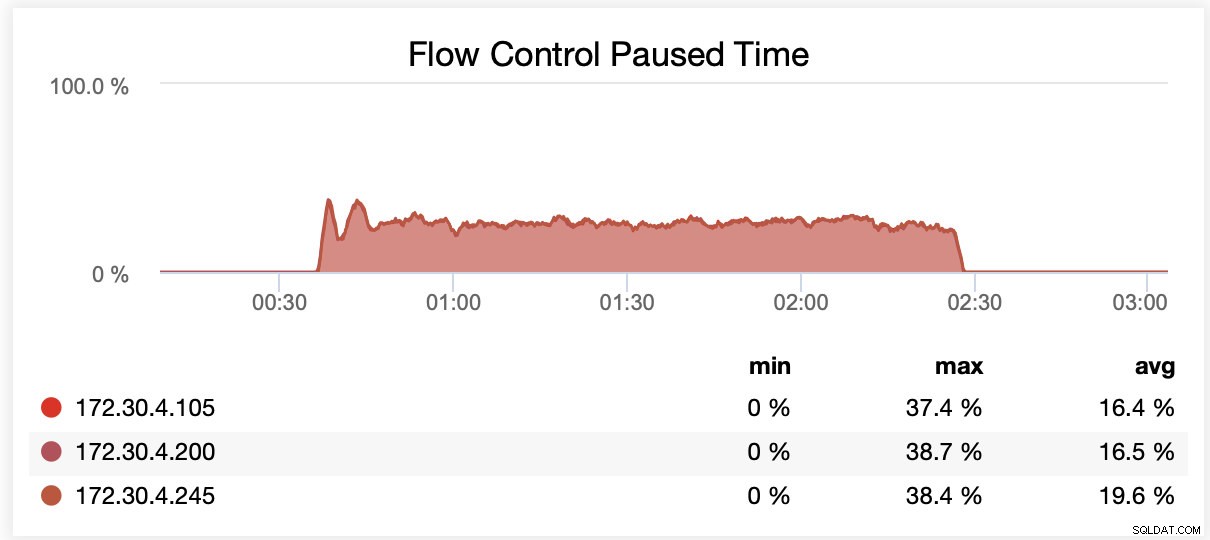
Mens du kørte med wsrep_slave_threads=16, blev noder i gennemsnit sat på pause på grund af flowkontrol ~20 % af tiden.
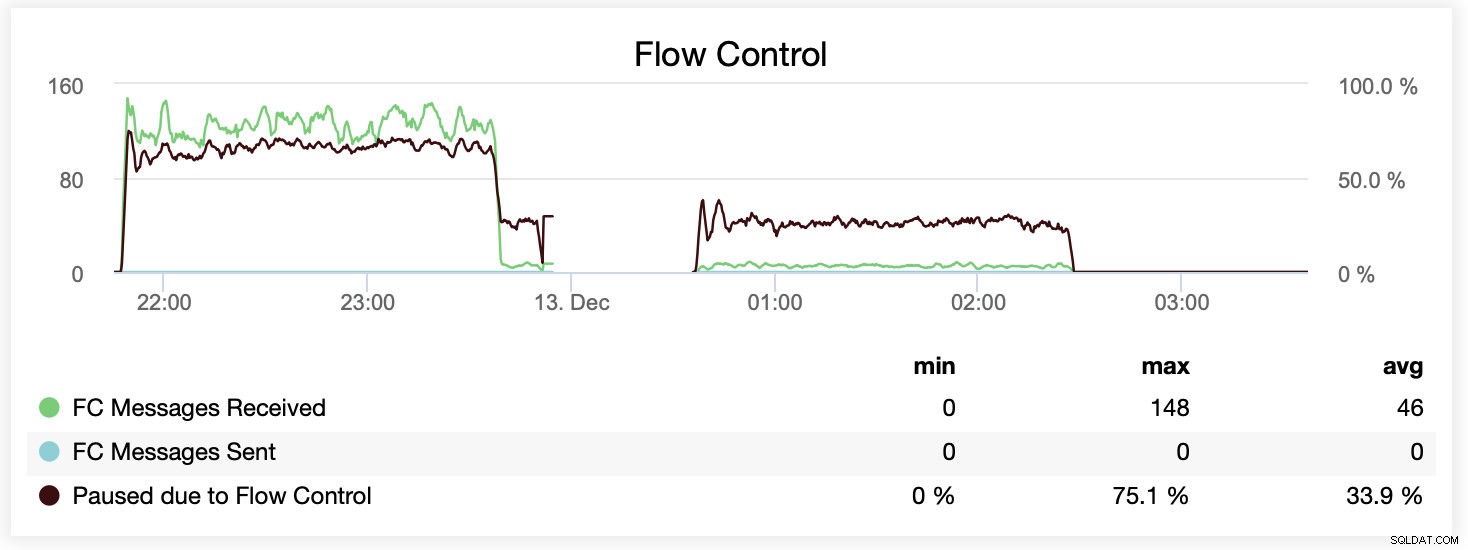
Du kan også sammenligne forskellen på en enkelt graf. Faldet i slutningen af den første del er det første forsøg på at køre med wsrep_slave_threads=16. Servere løb tør for diskplads til binære logfiler, og vi var nødt til at køre det benchmark igen på et senere tidspunkt.
Hvordan blev dette oversat til ydeevne? Forskellen er synlig, men bestemt ikke så spektakulær.
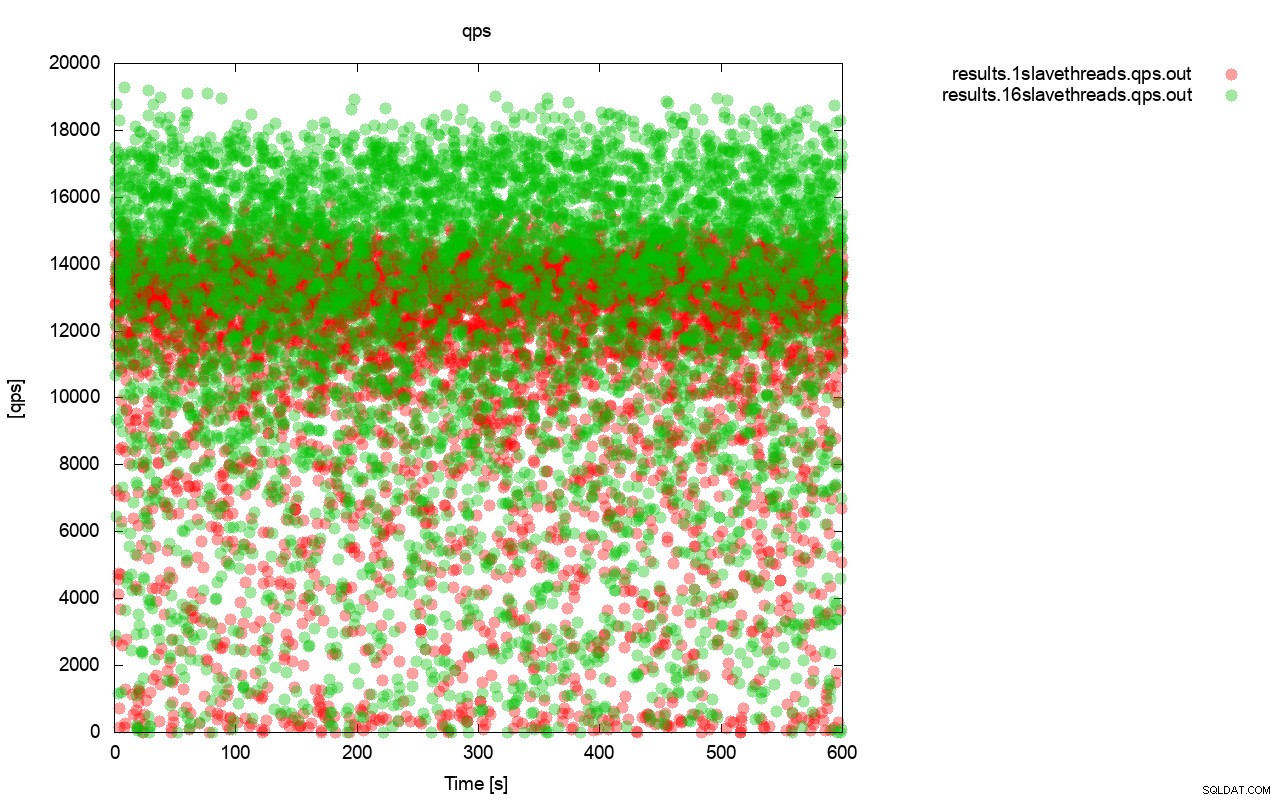
Først forespørgslen pr. sekund grafen. Først og fremmest kan du bemærke, at resultaterne i begge tilfælde er overalt. Dette er for det meste relateret til den ustabile ydeevne af I/O-lageret og flowkontrollen, der tilfældigt starter. Du kan stadig se, at ydeevnen af det "røde" resultat (wsrep_slave_threads=1) er ret lavere end det "grønne" ( wsrep_slave_threads=16).
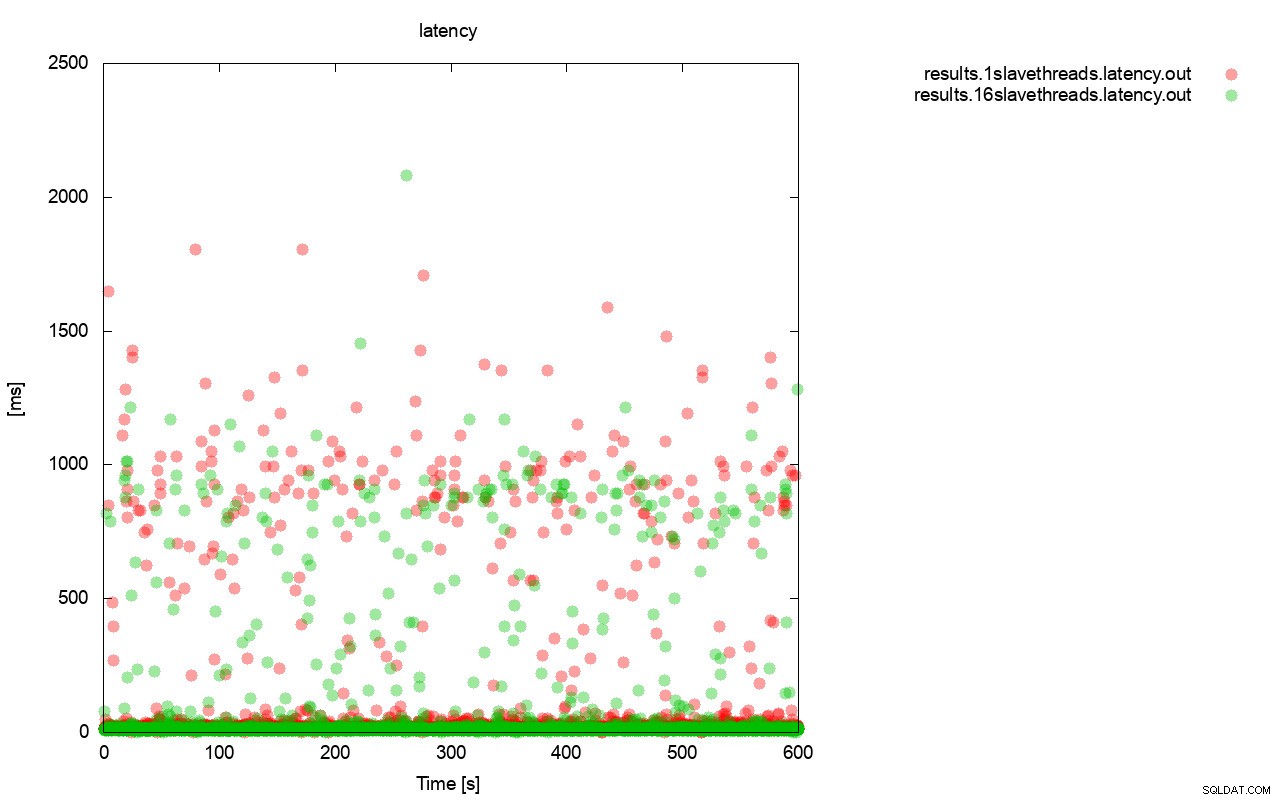
Et ganske lignende billede er, når vi ser på latensen. Du kan se flere (og typisk dybere) båse til løbeturen med wsrep_slave_thread=1.
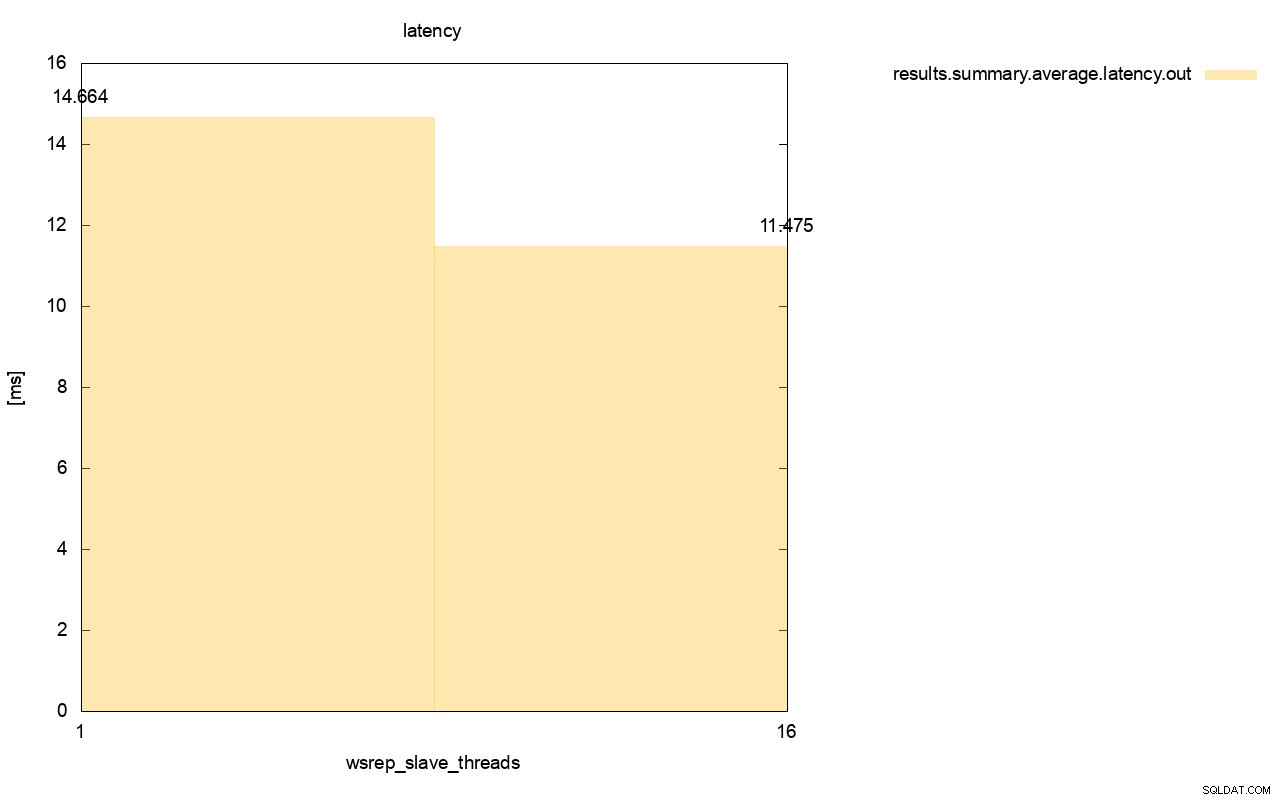
Forskellen er endnu mere synlig, når vi beregnede gennemsnitlig latens på tværs af alle kørsler, og du kan se, at latensen af wsrep_slave_thread=1 er 27 % højere af latensen med 16 slavetråde, hvilket åbenbart ikke er godt, da vi ønsker at latensen skal være lavere , ikke højere.
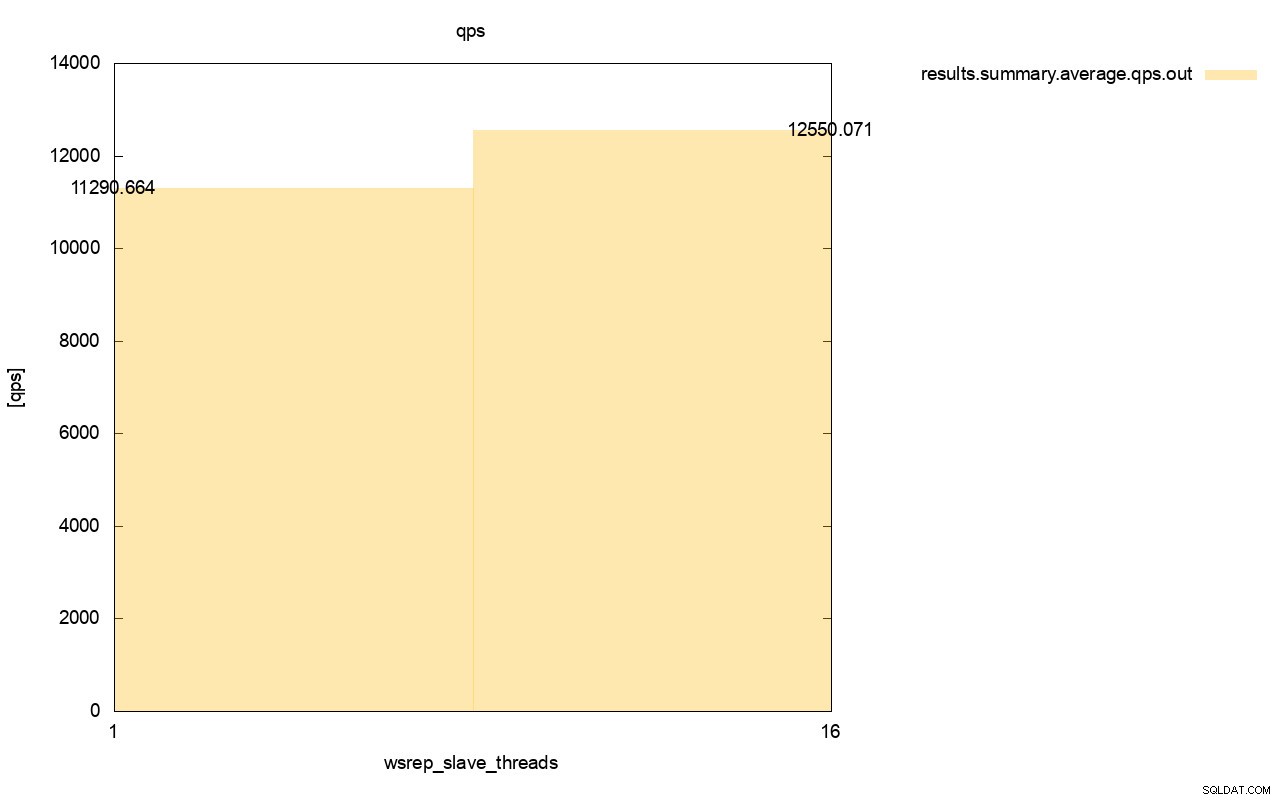
Forskellen i gennemløb er også synlig, omkring 11 % af forbedringen, da vi tilføjede flere wsrep_slave_threads.
Som du kan se, er virkningen der. Det er på ingen måde 16x (selvom det var sådan, vi øgede antallet af slavetråde i Galera), men det er bestemt fremtrædende nok til, at vi ikke kun kan klassificere det som en statistisk anomali.
Husk, at vi i vores tilfælde brugte ret små noder. Forskellen skulle være endnu mere væsentlig, hvis vi taler om store forekomster, der kører på EBS-volumener med tusindvis af klargjorte IOPS.
Så ville vi være i stand til at køre sysbench endnu mere aggressivt med et højere antal samtidige operationer. Dette skulle forbedre paralleliseringen af skrivesættene og forbedre gevinsten fra multithreading yderligere. Hurtigere hardware betyder også, at Galera vil være i stand til at bruge disse 16 tråde på en mere effektiv måde.
Når du kører test som denne, skal du huske på, at du skal presse dit opsætning næsten til dets grænser. Enkeltrådsreplikering kan håndtere en del belastning, og du skal køre tung trafik for faktisk at gøre den ikke effektiv nok til at håndtere opgaven.
Vi håber, at dette blogindlæg giver dig mere indsigt i Galera Clusters evner til at anvende skrivesæt parallelt og de begrænsende faktorer omkring det.