Der er ingen relevant hårdkodet grænse (65.536 * Netværkspakkestørrelse på 4KB er 268 MB, og din scriptlængde er ikke i nærheden af det), selvom det ikke er tilrådeligt at bruge denne metode til et stort antal rækker.
Den fejl, du ser, er smidt af klientværktøjerne ikke SQL Server. Hvis du konstruerer SQL-strengen i dynamisk SQL-kompilering, kan den i det mindste starte med succes
DECLARE @SQL NVARCHAR(MAX) = '(100,200,300),
';
SELECT @SQL = 'SELECT * FROM (VALUES ' + REPLICATE(@SQL, 1000000) + '
(100,200,300)) tc (proj_d, period_sid, val)';
SELECT @SQL AS [processing-instruction(x)]
FOR XML PATH('')
SELECT DATALENGTH(@SQL) / 1048576.0 AS [Length in MB] --30.517705917
EXEC(@SQL);
Selvom jeg dræbte ovenstående efter ~30 minutters kompileringstid, og det stadig ikke havde produceret en række. De bogstavelige værdier skal gemmes inde i selve planen som en tabel med konstanter, og SQL Server bruger meget tid forsøger også at udlede egenskaber om dem.
SSMS er et 32 bit program og sender en std::bad_alloc undtagelse under parsing af batchen
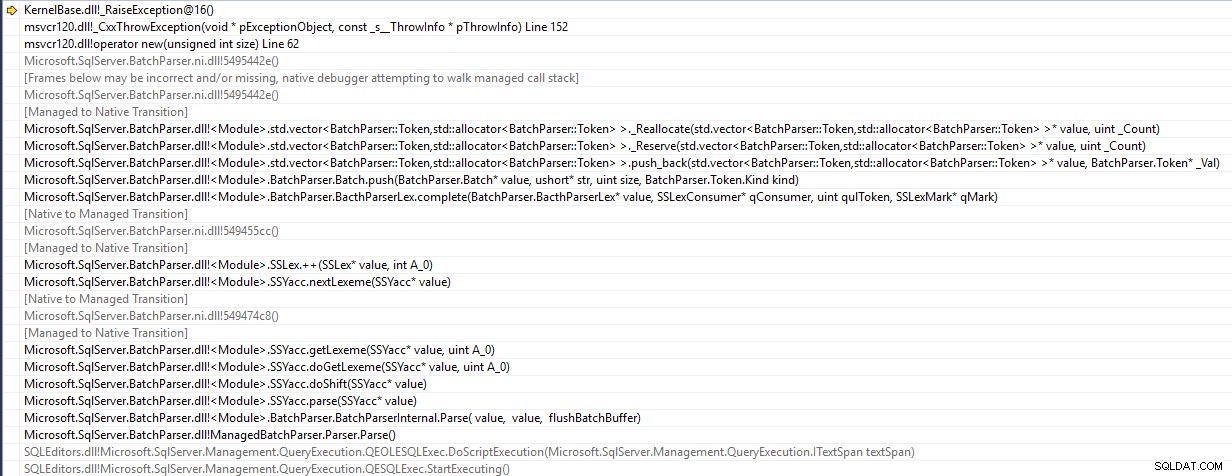
Den forsøger at skubbe et element ind på en vektor af Token, der har nået kapacitet, og dens forsøg på at ændre størrelse mislykkes på grund af utilgængelighed af et stort nok sammenhængende hukommelsesområde. Så erklæringen når aldrig engang så langt som serveren.
Vektorkapaciteten vokser med 50 % hver gang (dvs. at følge sekvensen her ). Kapaciteten som vektoren skal vokse til afhænger af hvordan koden er lagt ud.
Følgende skal vokse fra en kapacitet på 19 til 28.
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
og det følgende behøver kun en størrelse på 2
SELECT * FROM (VALUES (100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300),(100,200,300)) tc (proj_d, period_sid, val)
Følgende skal have en kapacitet på> 63 og <=94.
SELECT *
FROM (VALUES
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300),
(100,
200,
300)
) tc (proj_d, period_sid, val)
For en million rækker udlagt som i tilfælde 1 skal vektorkapaciteten vokse til 3.543.306.
Du vil muligvis opdage, at et af følgende vil tillade, at parsing på klientsiden lykkes.
- Reducer antallet af linjeskift.
- Genstarter SSMS i håb om, at anmodningen om stor sammenhængende hukommelse lykkes, når der er mindre fragmentering af adressepladsen.
Men selvom du sender det til serveren med succes, vil det kun ende med at dræbe serveren under generering af eksekveringsplaner, som diskuteret ovenfor.
Du vil være meget bedre stillet ved at bruge importeksportguiden til at indlæse tabellen. Hvis du skal gøre det i TSQL, vil du opdage, at opdeling af det i mindre batches og/eller at bruge en anden metode, såsom makulering af XML, vil fungere bedre end Table Valued Constructors. Følgende udføres på 13 sekunder på min maskine for eksempel (men hvis du bruger SSMS, vil du sandsynligvis stadig være nødt til at dele op i flere batches i stedet for at indsætte en massiv XML-streng bogstaveligt).
DECLARE @S NVARCHAR(MAX) = '<x proj_d="100" period_sid="200" val="300" />
' ;
DECLARE @Xml XML = REPLICATE(@S,1000000);
SELECT
x.value('@proj_d','int'),
x.value('@period_sid','int'),
x.value('@val','int')
FROM @Xml.nodes('/x') c(x)