Disse tests (database AdventureWorks2008R2) viser, hvad der sker:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Resultater:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Resultaterne fra SET STATISTICS IO viser, at LIO er de samme .Men udførelsesplanerne er helt anderledes: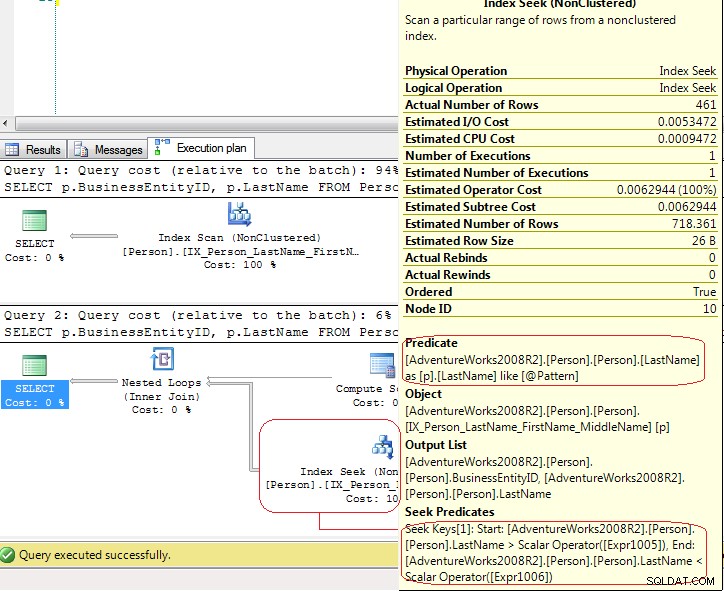
I den første test bruger SQL Server en Index Scan eksplicit, men i den anden test bruger SQL Server en Index Seek som er en Index Seek - range scan . I det sidste tilfælde bruger SQL Server en Compute Scalar operatør til at generere disse værdier
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
og Index Seek operatør bruge et Seek Predicate (optimeret) til en range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) plus endnu et uoptimeret Predicate (LastName LIKE @pattern ).
Mit svar:det er ikke en "rigtig" Index Seek . Det er en Index Seek - range scan som i dette tilfælde har samme ydeevne som Index Scan .
Se venligst også forskellen mellem Index Seek og Index Scan (lignende debat):Så...er det en søgning eller en scanning?
.
Rediger 1: Udførelsesplanen for OPTION(RECOMPILE) (se venligst Aarons anbefaling) viser også en Index Scan (i stedet for Index Seek ):