Omkostninger til undertræer skal tages med et stort gran salt (og især når du har store kardinalitetsfejl). INDSTIL STATISTIK IO TIL; INDSTIL STATISTIK TID TIL; output er en bedre indikator for den faktiske ydeevne.
Nulrækkesorteringen tager ikke 87 % af ressourcerne. Dette problem i din plan er et statistisk estimering. Omkostningerne vist i den faktiske plan er stadig estimerede omkostninger. Det justerer dem ikke for at tage hensyn til, hvad der faktisk skete.
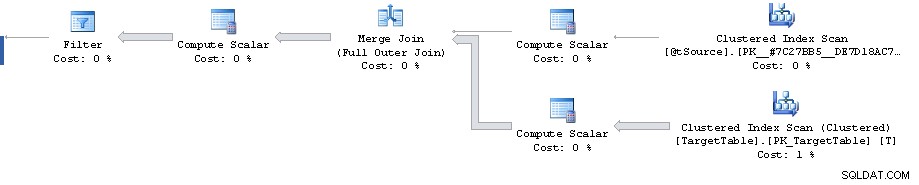
Der er et punkt i planen, hvor et filter reducerer 1.911.721 rækker til 0, men de anslåede rækker fremadrettet er 1.860.310. Derefter er alle omkostninger falske, hvilket kulminerer med de 87% omkostninger, der anslås til 3.348.560 rækker.
Kardinalitetsberegningsfejlen kan gengives uden for Merge erklæring ved at se på den estimerede plan for Fuld Outer Join med tilsvarende prædikater (giver samme estimat på 1.860.310 rækker).
VÆLG * FRA TargetTable TFULD YDRE JOIN @tSource S PÅ S.Key1 =T.Key1 og S.Key2 =T.Key2WHERE TILFÆLDE NÅR S.Key1 IKKE ER NULL /*Matched by Source*/ THEN CASE WHEN T.Key1 ER IKKE NULL /*Matched by Target*/ SÅ TILFÆLDE, NÅR [T].[Data1]<>S.[Data1] ELLER [T].[Data2]<>S.[Data2] ELLER [T]. [Data3]<>S.[Data3] THEN (1) SLUT /*Ikke matchet af mål*/ ELSE (4) SLUT /*Ikke matchet af kilde*/ ELSE CASE NÅR [T].[Key1]eksempel@sqldat.com
SÅ (3) ER END END IKKE NULL
Når det er sagt, ser planen op til selve filteret dog ganske suboptimal ud. Den laver en fuld klynget indeksscanning, når du måske vil have en plan med 2 grupperede indeksintervaller. Den ene for at hente den enkelte række, der matches af den primære nøgle fra join-on-kilden, og den anden for at hente T.Key1 =@id område (selvom det måske er for at undgå behovet for at sortere i grupperet nøglerækkefølge senere?)
Måske kunne du prøve denne omskrivning og se, om den virker bedre eller værre
;WITH FilteredTarget AS(SELECT T.*FROM TargetTable AS T WITH (FORCESEEK)JOIN @tSource S ON (T.Key1 =S.Key1 AND S.Key2 =T.Key2) OR T.Key1 =@id)MERGE FilteredTarget AS TUSING @tSource SON (T.Key1 =S.Key1 AND S.Key2 =T.Key2)-- Opdater kun, hvis datakolonnerne ikke matcherNÅR MATCHED OG S.Key1 =T.Key1 OG S. Nøgle2 =T.Key2 OG (T.Data1 <> S.Data1 ELLER T.Data2 <> S.Data2 ELLER T.Data3 <> S.Data3) SÅ OPDATERES SÆT T.Data1 =S.Data1, T.Data2 =S .Data2, T.Data3 =S.Data3-- Bemærkning fra original plakat:Denne ekstra "sikkerhedsklausul" viste sig ikke at-- påvirke adfærden eller udførelsesplanen, så jeg fjernede den, og den fungerer-- lige så godt uden , men hvis du befinder dig i en lignende situation-- vil du måske prøve det.-- NÅR MATCHED OG (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 =@id THEN-- DELETE-- Indsæt når m issing i målet, NÅR IKKE MATCHED AF MÅL SÅ INDSÆT (Nøgle1, Nøgle2, Data1, Data2, Data3) VÆRDIER (Nøgle1, Nøgle2, Data1, Data2, Data3)NÅR DE IKKE MATCHES AF KILDE OG T.Key1 =@id SLET SÅ;