SQL Server optimizer indeholder logik til at fjerne redundante joins, men der er begrænsninger, og joins skal være viselig overflødig . For at opsummere kan en joinforbindelse have fire effekter:
- Den kan tilføje ekstra kolonner (fra den samlede tabel)
- Den kan tilføje ekstra rækker (den sammenføjede tabel kan matche en kilderække mere end én gang)
- Den kan fjerne rækker (den sammenføjede tabel har muligvis ikke et match)
- Det kan introducere
NULLs (for enHØJRE ellerFULD JOIN)
For at kunne fjerne en redundant joinforbindelse skal forespørgslen (eller visningen) tage højde for alle fire muligheder. Når dette er gjort korrekt, kan effekten være forbløffende. For eksempel:
BRUG AdventureWorks2012;GOCREATE VIS dbo.ComplexViewAS SELECT pc.ProductCategoryID, pc.Name AS CatName, ps.ProductSubcategoryID, ps.Name AS SubCatName, p.ProductID, p.Name AS ProductName, p.Color, p. .ListPrice, p.ReorderPoint, pm.Name AS ModelName, pm.ModifiedDate FROM Production.ProductCategory AS pc FULD JOIN Production.ProductSubcategory AS ps ON ps.ProductCategoryID =pc.ProductCategoryID FULD JOIN Production.Product.Product pS .ProductSubcategoryID FULD JOIN Production.ProductModel AS pm ON pm.ProductModelID =p.ProductModelID Optimeringsværktøjet kan med succes forenkle følgende forespørgsel:
VÆLG c.ProductID, c.ProductNameFROM dbo.ComplexView AS cWHERE c.ProductName LIKE N'G%'; Til:

Rob Farley skrev om disse ideer i dybden i den originale MVP Deep Dives-bog , og der er en optagelse af ham, der præsenterer om emnet på SQLBits.
De vigtigste begrænsninger er, at udenlandske nøglerelationer skal være baseret på en enkelt nøgle at bidrage til forenklingsprocessen, og kompileringstiden for forespørgslerne mod en sådan visning kan blive ret lang, især når antallet af joinforbindelser stiger. Det kunne være noget af en udfordring at skrive en 100-tabell visning, der får al semantikken nøjagtigt korrekt. Jeg ville være tilbøjelig til at finde en alternativ løsning, måske ved at bruge dynamisk SQL .
Når det er sagt, kan de særlige kvaliteter af din denormaliserede tabel betyde, at visningen er ret enkel at samle, og den kræver kun håndhævede UDLANDSKE NØGLER ikke-NULL kan refererede kolonner og passende UNIQUE begrænsninger for at få denne løsning til at fungere, som du ville håbe, uden overhead på 100 fysiske deltagere i planen.
Eksempel
Brug af ti tabeller i stedet for hundrede:
-- Refererede tabellerCREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);OPRET TABEL dbo.Ref03 (col03 tinyint PRIMÆR NØGLE, item varchar(50) IKKE NULL UNIK);OPRET TABEL dbo.Ref04 (col04 tinyint PRIMÆR NØGLE, item varchar(50) IKKE NULL UNIK);OPRET TABEL dbo.Ref05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) ) NOT NULL UNIQUE);CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); Den overordnede tabeldefinition (med sidekomprimering):
OPRET TABEL dbo.Normalized( pk heltal IDENTITET IKKE NULL, col01 tinyint IKKE NULL REFERENCER dbo.Ref01, col02 tinyint IKKE NULL REFERENCER dbo.Ref02, col03 tinyint IKKE NULL REFERENCER dbo.Referencer tiny3, colNULL tiny3 dbo.Ref04, col05 tinyint IKKE NULL REFERENCER dbo.Ref05, col06 tinyint NOT NULL REFERENCER dbo.Ref06, col07 tinyint NOT NULL REFERENCER dbo.Ref07, col08 tinyint NOT NULL REFERENCER dbo.Ref.09 dbo.Ref. tinyint IKKE NULL REFERENCER dbo.Ref10, BEGRÆNSNING PK_Normaliseret PRIMÆR NØGLE KLUSTERET (pk) MED (DATA_KOMPRESSION =SIDE)); Udsigten:
OPRET VISNING dbo.DenormalizedWITH SCHEMABINDING ASSELECT item01 =r01.item, item02 =r02.item, item03 =r03.item, item04 =r04.item, item05 =r05.item, item06 =r07item. =r07.item, item08 =r08.item, item09 =r09.item, item10 =r10.itemFROM dbo.Normalized AS nJOIN dbo.Ref01 AS r01 ON r01.col01 =n.col01JOIN dbo.r0202 ON AS r0202 n.col02JOIN dbo.Ref03 AS r03 ON r03.col03 =n.col03JOIN dbo.Ref04 AS r04 ON r04.col04 =n.col04JOIN dbo.Ref05 AS r05 ON r05.col03JOIN .6Re .0IN . col06 =n.col06JOIN dbo.Ref07 AS r07 ON r07.col07 =n.col07JOIN dbo.Ref08 AS r08 ON r08.col08 =n.col08JOIN dbo.Ref09 AS r09 ON r09IN0ON.col09 =ReJ0IN0ON. r10.col10 =n.col10; Hack statistikkerne for at få optimizeren til at synes, at tabellen er meget stor:
OPDATERING STATISTIK dbo.Normaliseret MED ROWCOUNT =100000000, PAGECOUNT =5000000; Eksempel på brugerforespørgsel:
VÆLG d.item06, d.item07FROM dbo.Denormalized AS dWHERE d.item08 ='Banan' OG d.item01 ='Grøn'; Giver os denne udførelsesplan:
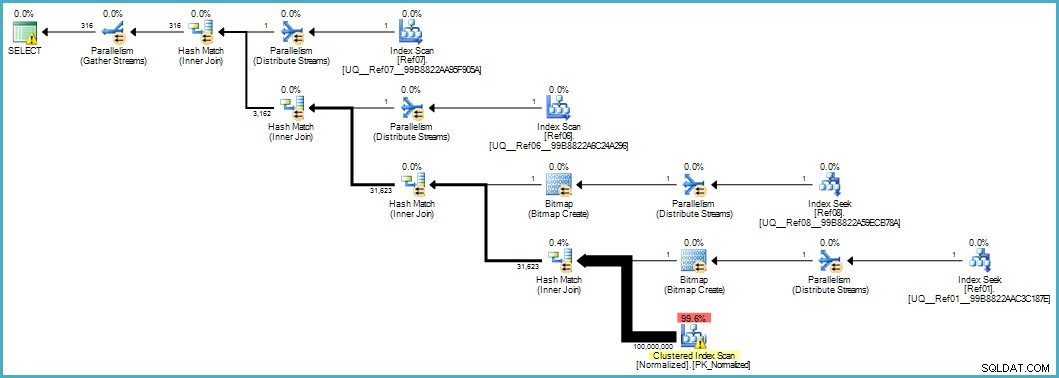
Scanningen af den normaliserede tabel ser dårlig ud, men begge Bloom-filter bitmaps anvendes under scanningen af lagermotoren (så rækker, der ikke kan matche, ikke engang dukker op så langt som forespørgselsprocessoren). Dette kan være nok til at give acceptabel ydeevne i dit tilfælde, og bestemt bedre end at scanne den originale tabel med dens overfyldte kolonner.
Hvis du er i stand til at opgradere til SQL Server 2012 Enterprise på et tidspunkt, har du en anden mulighed:oprette et kolonnelagerindeks på den normaliserede tabel:
OPRET IKKE KLUSTERET KOLUMNEBUTIKINDEKS cs PÅ dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10); Udførelsesplanen er:
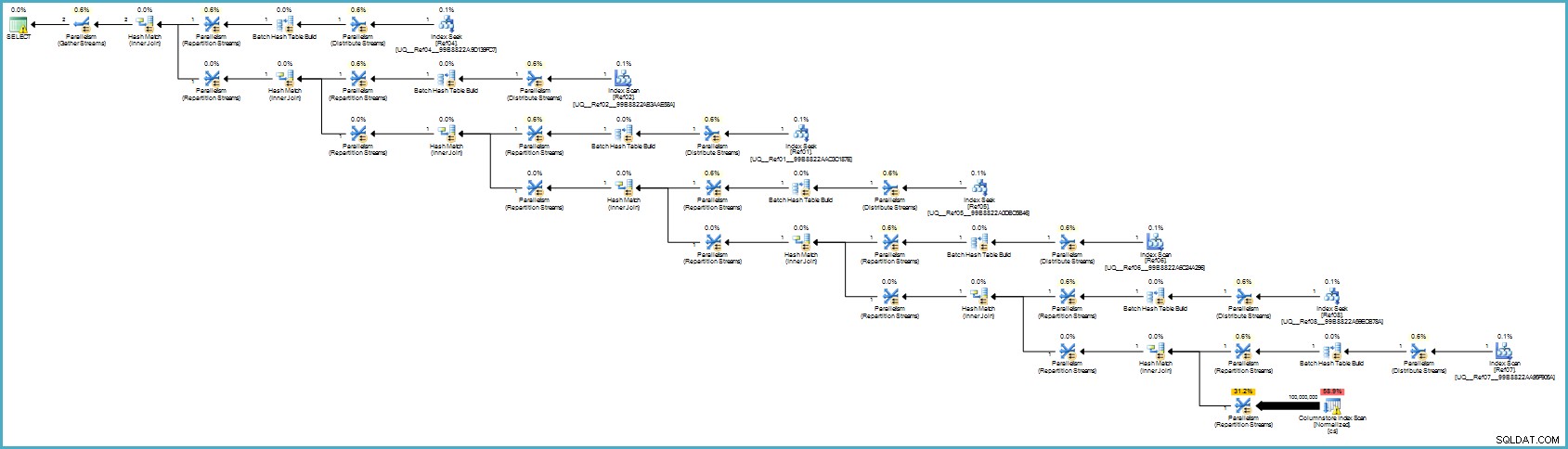
Det ser nok værre ud for dig, men kolonnelagring giver exceptionel komprimering, og hele udførelsesplanen kører i Batch Mode med filtre for alle de bidragende kolonner. Hvis serveren har tilstrækkelige tråde og hukommelse til rådighed, kan dette alternativ virkelig flyve.
I sidste ende er jeg ikke sikker på, at denne normalisering er den korrekte tilgang i betragtning af antallet af tabeller og chancerne for at få en dårlig eksekveringsplan eller kræve overdreven kompileringstid. Jeg ville nok rette skemaet for den denormaliserede tabel først (korrekte datatyper og så videre), muligvis anvende datakomprimering...de sædvanlige ting.
Hvis dataene virkelig hører hjemme i et stjerneskema, kræver det sandsynligvis mere designarbejde end blot at opdele gentagne dataelementer i separate tabeller.