Demonstration af mulig forklaring.
Opret tabelscript
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
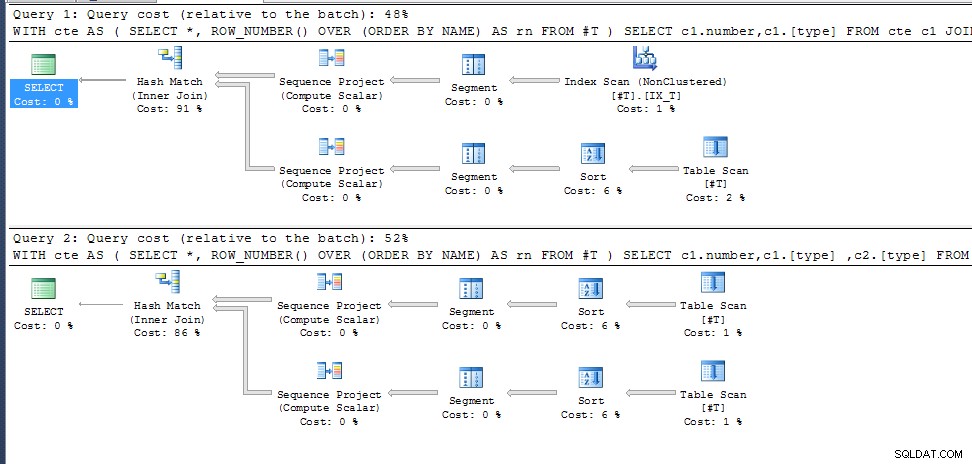
Forespørgsel 1 (Giver 35 resultater)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Forespørgsel 2 (Samme som før, men tilføjelse af c2.[type] til den valgte liste giver 0 resultater);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Hvorfor?
row_number() for duplikerede NAVNE er ikke angivet, så den vælger bare den, der passer ind i den bedste udførelsesplan for de påkrævede outputkolonner. I den anden forespørgsel er dette det samme for begge cte-ankaldelser, i den første vælger den en anden adgangssti med resulterende forskellig rækkenummerering.
Foreslået løsning
Du melder dig selv til CTE på ROW_NUMBER() over (order by t.[Date])
I modsætning til hvad der kunne have været forventet, vil CTE sandsynligvis ikke realiseres
hvilket ville have sikret ensartethed for selvforeningen og dermed antager du en korrelation mellem ROW_NUMBER() på begge sider, der muligvis ikke eksisterer for poster, hvor en dublet [Date] findes i dataene.
Hvad hvis du prøver ROW_NUMBER() over (order by t.[Date], t.[id]) for at sikre, at i tilfælde af uafgjorte datoer, er rækkenummereringen i en garanteret ensartet rækkefølge. (Eller en anden kolonne/kombination af kolonner, der kan differentiere poster, hvis id ikke vil gøre det)