Returnerende kombinationer
Brug en taltabel eller talgenererende CTE til at vælge 0 til 2^n - 1. Brug bitpositionerne, der indeholder 1'ere i disse tal til at angive tilstedeværelsen eller fraværet af de relative medlemmer i kombinationen, og eliminere dem, der ikke har det korrekte antal værdier, bør du være i stand til at returnere et resultatsæt med alle de kombinationer, du ønsker.
MED Nums (Num) AS ( SELECT Num FROM Numbers WHERE Num MELLEM 0 OG POWER(2, @n) - 1), BaseSet AS ( SELECT ind =Power(2, Row_Number() OVER (ORDER BY Værdi) - 1), * FRA @sæt), Combos AS ( SELECT ComboID =N.Num, S.Value, Cnt =Count(*) OVER (OPDELING AF N.Num) FRA Nums N INNER JOIN BaseSet S ON N. Num &S.ind <> 0)VÆLG ComboID, ValueFROM CombosWHERE Cnt =@kORDER BY ComboID, Value; Denne forespørgsel fungerer ret godt, men jeg tænkte på en måde at optimere den på ved at hente fra Fin Parallel Bit Count for først at få taget det rigtige antal genstande ad gangen. Dette udfører 3 til 3,5 gange hurtigere (både CPU og tid):
MED Nums AS ( SELECT Num, P1 =(Num &0x55555555) + ((Num / 2) &0x55555555) FROM dbo.Numbers WHERE Num BETWEEN 0 AND POWER(2, @n) - 1), Nums2 AS ( VÆLG Num, P2 =(P1 &0x33333333) + ((P1 / 4) &0x33333333) FRA Nums), Nums3 AS ( SELECT Num, P3 =(P2 &0x0f0f0f0f) + ((P2 / 0x0f)f0 &0x0f)f0 FROM Nums2), BaseSet AS ( SELECT ind =Power(2, Row_Number() OVER (ORDER BY Value) - 1), * FROM @set)SELECT ComboID =N.Num, S.ValueFROM Nums3 N INNER JOIN BaseSet S ON N .Num &S.ind <> 0WHERE P3 % 255 =@kORDER BY ComboID, Value; Jeg gik og læste bittællingssiden og tænkte, at dette kunne fungere bedre, hvis jeg ikke laver % 255, men går hele vejen med bitregning. Når jeg får en chance, vil jeg prøve det og se, hvordan det hænger sammen.
Mine præstationskrav er baseret på de forespørgsler, der køres uden ORDER BY-klausulen. For klarhedens skyld, hvad denne kode gør, er at tælle antallet af sæt 1-bits i Num fra Numre bord. Det skyldes, at tallet bliver brugt som en slags indekser til at vælge, hvilke elementer af sættet der er i den aktuelle kombination, så antallet af 1-bit vil være det samme.
Jeg håber, du kan lide det!
For god ordens skyld er denne teknik med at bruge bitmønsteret af heltal til at vælge medlemmer af et sæt, hvad jeg har opfundet "Vertical Cross Join". Det resulterer effektivt i krydssammenføjning af flere sæt data, hvor antallet af sæt og krydssammenføjninger er vilkårligt. Her er antallet af sæt antallet af genstande, der tages ad gangen.
Faktisk vil krydssammenføjning i den sædvanlige horisontale betydning (at tilføje flere kolonner til den eksisterende liste over kolonner med hver sammenføjning) se sådan ud:
SELECT A.Value, B.Value, C.ValueFROM @Set A CROSS JOIN @Set B CROSS JOIN @Set CWHERE A.Value ='A' AND B.Value ='B' AND C.Value ='C' Mine forespørgsler ovenfor "cross join" effektivt så mange gange som nødvendigt med kun én join. Resultaterne er upivoterede i forhold til faktiske krydsforbindelser, selvfølgelig, men det er en mindre sag.
Kritik af din kode
Først må jeg foreslå denne ændring til din faktorielle UDF:
ALTER FUNCTION dbo.Factorial ( @x bigint)RETURNER bigintASBEGIN IF @x <=1 RETURN 1 RETURN @x * dbo.Factorial(@x - 1)END
Nu kan du beregne meget større sæt af kombinationer, plus det er mere effektivt. Du kan endda overveje at bruge decimal(38, 0) for at tillade større mellemregninger i dine kombinationsberegninger.
For det andet returnerer din givne forespørgsel ikke de korrekte resultater. For eksempel, ved at bruge mine testdata fra ydeevnetestningen nedenfor, er sæt 1 det samme som sæt 18. Det ser ud til, at din forespørgsel tager en glidende stribe, der går rundt:hvert sæt er altid 5 tilstødende medlemmer, der ser sådan ud (jeg drejede for at gøre det nemmere at se):
1 ABCDE 2 ABCD Q 3 ABC PQ 4 AB OPQ 5 A NOPQ 6 MNOPQ 7 LMNOP 8 KLMNO 9 JKLMN 10 IJKLM 11 HIJKL 12 GHIJK 13 FGHIJ 14 EFGHI 15 DEFFGH 18 BCDDE 18 BCDDE 18 /kode>
Sammenlign mønsteret fra mine forespørgsler:
31 ABCDE 47 ABCD F 55 ABC EF 59 AB DEF 61 A CDEF 62 BCDEF 79 ABCD G 87 ABC E G 91 AB DE G 93 A CDE G 94 BCDE G103 ABC FG107 AB D FG109 A BCD FG1105 EFG117 A C EFG118 BC EFG121 A DEFG...
Bare for at køre bit-mønsteret -> indeks af kombination ting hjem for alle interesserede, bemærk at 31 i binær =11111 og mønsteret er ABCDE. 121 i binær er 1111001, og mønsteret er A__DEFG (baglæns kortlagt).
Ydeevneresultater med en tabel med reelle tal
Jeg kørte nogle præstationstest med store sæt på min anden forespørgsel ovenfor. Jeg har på nuværende tidspunkt ikke en registrering af den anvendte serverversion. Her er mine testdata:
DECLARE @k int, @n int;DECLARE @set TABLE (værdi varchar(24));INSERT @set VALUES ('A'),('B'),('C'),( 'D'),('E'),('F'),('G'),('H'),('I'),('J'),('K'),('L '),('M'),('N'),('O'),('P'),('Q');SET @n =@@RowCount;SET @k =5;DECLARE @kombinationer bigint =dbo.Factorial(@n) / (dbo.Factorial(@k) * dbo.Factorial(@n - @k));SELECT CAST(@combinations as varchar(max)) + 'kombinationer', MaxNumUsedFromNumbersTable =POWER (2, @n);
Peter viste, at denne "lodrette krydsforbindelse" ikke fungerer så godt som blot at skrive dynamisk SQL for rent faktisk at udføre de CROSS JOINs, den undgår. Til de trivielle omkostninger ved et par læsninger har hans løsning målinger mellem 10 og 17 gange bedre. Ydeevnen af hans forespørgsel falder hurtigere end min, efterhånden som mængden af arbejde øges, men ikke hurtigt nok til at stoppe nogen fra at bruge den.
Det andet sæt tal nedenfor er faktoren divideret med den første række i tabellen, bare for at vise, hvordan den skaleres.
Erik
Elementer CPU-skriver Læsetid | CPU Skriver Læsning Varighed----- ------ ------ ------- -------- | ----- ------ ------ --------17•5 7344 0 3861 8531 |18•9 17141 0 7748 18536 | 2,3 2,0 2,220•10 76657 0 34078 84614 | 10,4 8,8 9,921•11 163859 0 73426 176969 | 22,3 19,0 20,721•20 142172 0 71198 154441 | 19,4 18,4 18,1
Peter
Elementer CPU-skriver Læsetid | CPU Skriver Læsning Varighed----- ------ ------ ------- -------- | ----- ------ ------ --------17•5 422 70 10263 794 | 18•9 6046 980 219180 11148 | 14,3 14,0 21,4 14,020•10 24422 4126 901172 46106 | 57,9 58,9 87,8 58,121•11 58266 8560 2295116 104210 | 138,1 122,3 223,6 131,321•20 51391 5 6291273 55169 | 121,8 0,1 613,0 69,5
Hvis man ekstrapolerer, vil min forespørgsel i sidste ende være billigere (selvom det er fra starten i læsninger), men ikke i lang tid. For at bruge 21 elementer i sættet kræver det allerede en taltabel, der går op til 2097152...
Her er en kommentar, som jeg oprindeligt lavede, før jeg indså, at min løsning ville fungere drastisk bedre med en taltabel, der er på farten:
Ydeevneresultater med en On-The-Fly-taltabel
Da jeg oprindeligt skrev dette svar, sagde jeg:
Nå, jeg prøvede det, og resultaterne var, at det fungerede meget bedre! Her er den forespørgsel, jeg brugte:
DECLARE @N int =16, @K int =12;CREATE TABLE #Set (Værdi char(1) PRIMARY KEY CLUSTERED);CREATE TABLE #Items (Num int);INSERT #Items VALUES (@K) );INSERT #Set SELECT TOP (@N) VFROM (VÆRDIER ('A'),('B'),('C'),('D'),('E'),('F'), ('G'),('H'),('I'),('J'),('K'),('L'),('M'),('N'),(' O'),('P'),('Q'),('R'),('S'),('T'),('U'),('V'),('W' ),('X'),('Y'),('Z')) X (V);GODECLARE @N int =(SELECT Count(*) FROM #Set), @K int =(SELECT TOP 1 Num FROM #Items);DECLARE @combination int, @value char(1);WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),L1 AS (SELECT 1 N FROM L0, L0 B),L2 AS (SELECT 1 N FROM L1, L1 B), L3 AS (VÆLG 1 N FRA L2, L2 B), L4 AS (VÆLG 1 N FRA L3, L3 B), L5 AS (VÆLG 1 N FRA L4, L4 B), Tal AS (SELECT Row_Number () OVER(ORDER BY (SELECT 1)) Num FRA L5),Nums1 AS ( SELECT Num, P1 =(Num &0x55555555) + ((Num / 2) &0x55555555) FROM Nums WHERE Num MELLEM 0 OG Power(2, @N) - 1), Nums2 AS ( SELECT Num, P2 =(P1 &0x33333333) + ((P1 / 4) &0x33333333) FRA Nums1), Nums3 AS ( SELECT Num, P3 =(P2 &0x0F0F0F0F) + ((P2 / 16) &0x0F0F0F0F) FROM Nums2), BaseSet AS ( SELECT Ind =Power(2, Row_Number() OVER (ORDER BY Value) - 1), * FROM #Set)SELECT @Combination =N.Num, @Value =S.ValueFROM Nums3 N INNER JOIN BaseSet S ON N.Num &S.Ind <> 0WHERE P3 % 255 =@K;
Bemærk, at jeg valgte værdierne i variabler for at reducere den tid og den nødvendige hukommelse til at teste alt. Serveren udfører stadig det samme arbejde. Jeg modificerede Peters version til at være ens, og fjernede unødvendigt ekstraudstyr, så de begge var så slanke som muligt. Serverversionen, der bruges til disse tests, er Microsoft SQL Server 2008 (RTM) - 10.0.1600.22 (Intel X86) Standard Edition på Windows NT 5.2 (Build 3790:Service Pack 2) (VM) kører på en VM.
Nedenfor er diagrammer, der viser ydeevnekurverne for værdier af N og K op til 21. Basisdata for dem er i et andet svar på denne side
. Værdierne er resultatet af 5 kørsler af hver forespørgsel ved hver K- og N-værdi, efterfulgt af at smide de bedste og dårligste værdier ud for hver metrik og gennemsnittet af de resterende 3.
Grundlæggende har min version en "skulder" (i det venstre hjørne af diagrammet) ved høje værdier af N og lave værdier af K, der gør, at den klarer sig dårligere der end den dynamiske SQL-version. Dette forbliver dog ret lavt og konstant, og den centrale top omkring N =21 og K =11 er meget lavere for Duration, CPU og Reads end den dynamiske SQL-version.
Jeg inkluderede et diagram over antallet af rækker, hver vare forventes at returnere, så du kan se, hvordan forespørgslen klarer sig i forhold til, hvor stort et job det skal udføre.
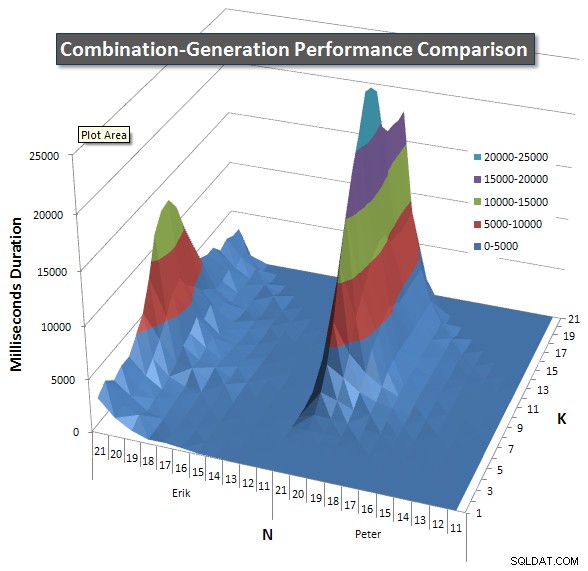
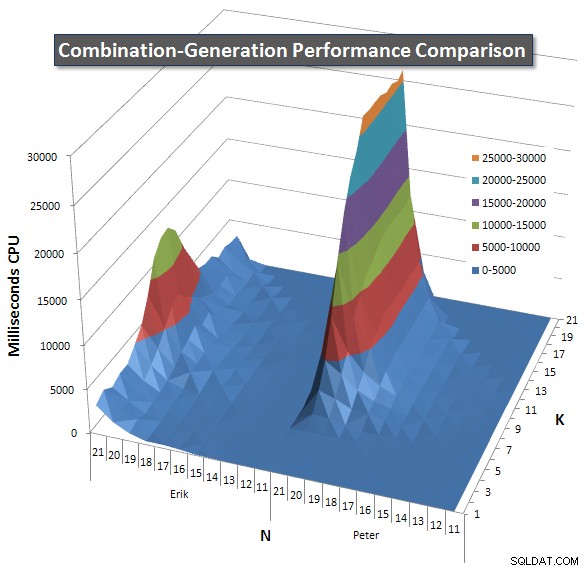
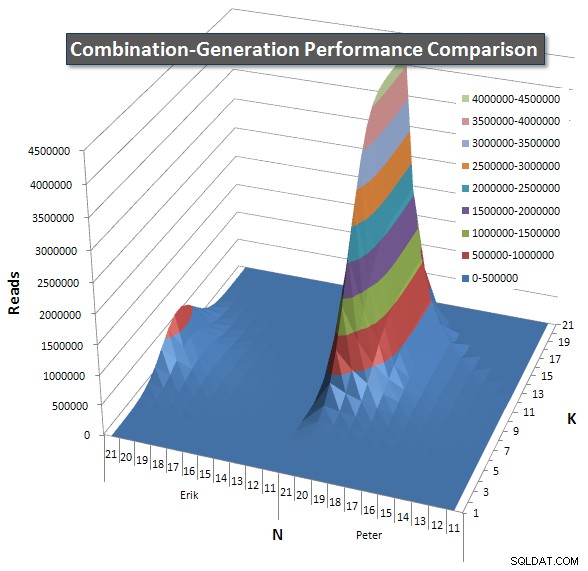
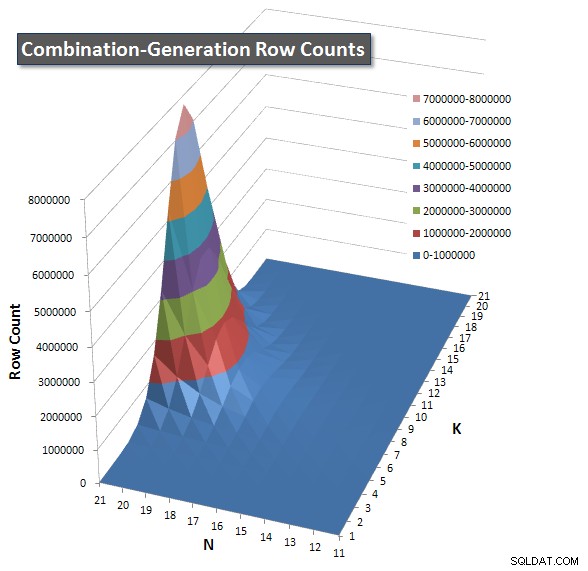
Se venligst mit yderligere svar på denne side
for de komplette præstationsresultater. Jeg ramte grænsen for posttegn og kunne ikke inkludere det her. (Enhver idé, hvor man ellers skal placere den?) For at sætte tingene i perspektiv i forhold til min første versions præstationsresultater, er her det samme format som før:
Erik
Elementer CPU-varighed Læser Skriver | CPU-varighed læser ----- ----- -------- ------- ------ | ------------- -------17•5 354 378 12382 0 |18•9 1849 1893 97246 0 | 5,2 5,0 7,920•10 7119 7357 369518 0 | 20,1 19,5 29,821•11 13531 13807 705438 0 | 38,2 36,5 57,021•20 3234 3295 48 0 | 9,1 8,7 0,0
Peter
Elementer CPU-varighed Læser Skriver | CPU-varighed læser ----- ----- -------- ------- ------ | ------------- -------17•5 41 45 6433 0 | 18•9 2051 1522 214021 0 | 50,0 33,8 33,320•10 8271 6685 864455 0 | 201,7 148,6 134,421•11 18823 15502 2097909 0 | 459,1 344,5 326,121•20 25688 17653 4195863 0 | 626,5 392,3 652,2
Konklusioner
- On-the-fly taltabeller er bedre end en rigtig tabel, der indeholder rækker, da læsning af en ved store rækkeantal kræver en masse I/O. Det er bedre at bruge lidt CPU.
- Mine indledende tests var ikke brede nok til virkelig at vise ydeevneegenskaberne for de to versioner.
- Peters version kunne forbedres ved at få hvert JOIN til ikke kun at være større end det foregående element, men også begrænse den maksimale værdi baseret på, hvor mange flere elementer der skal passes ind i sættet. For eksempel, ved 21 elementer taget 21 ad gangen, er der kun ét svar på 21 rækker (alle 21 elementer, én gang), men de mellemliggende rækkesæt i den dynamiske SQL-version, tidligt i udførelsesplanen, indeholder kombinationer som " AU" på trin 2, selvom dette vil blive kasseret ved næste joinforbindelse, da der ikke er nogen værdi højere end "U" tilgængelig. På samme måde vil et mellemrækkesæt i trin 5 indeholde "ARSTU", men den eneste gyldige kombination på dette tidspunkt er "ABCDE". Denne forbedrede version ville ikke have en lavere top i midten, så den muligvis ikke forbedres nok til at blive den klare vinder, men den ville i det mindste blive symmetrisk, så søkortene ikke ville forblive maksimalt forbi midten af regionen, men ville falde tilbage til tæt på 0, som min version gør (se det øverste hjørne af toppene for hver forespørgsel).
Varighedsanalyse
- Der er ingen virkelig signifikant forskel mellem versionerne i varighed (>100 ms) indtil 14 elementer taget 12 ad gangen. Indtil nu vinder min version 30 gange, og den dynamiske SQL-version vinder 43 gange.
- Startende ved 14•12 var min version hurtigere 65 gange (59>100ms), den dynamiske SQL-version 64 gange (60>100ms). Men alle de gange min version var hurtigere, sparede den en samlet gennemsnitlig varighed på 256,5 sekunder, og når den dynamiske SQL-version var hurtigere, sparede den 80,2 sekunder.
- Den samlede gennemsnitlige varighed for alle forsøg var Erik 270,3 sekunder, Peter 446,2 sekunder.
- Hvis der blev oprettet en opslagstabel for at bestemme, hvilken version der skal bruges (ved at vælge den hurtigste til input), kunne alle resultater udføres på 188,7 sekunder. At bruge den langsomste hver gang ville tage 527,7 sekunder.
Læsningsanalyse
Varighedsanalysen viste, at min forespørgsel vandt med betydeligt, men ikke alt for stort beløb. Når metrikken skiftes til læsninger, tegner der sig et meget andet billede - min forespørgsel bruger i gennemsnit 1/10 af læsningerne.
- Der er ingen virkelig signifikant forskel mellem versionerne i læsninger (>1000) indtil 9 elementer er taget 9 ad gangen. Indtil nu vinder min version 30 gange, og den dynamiske SQL-version vinder 17 gange.
- Startende ved 9•9 brugte min version færre læsninger 118 gange (113>1000), den dynamiske SQL-version 69 gange (31>1000). Men alle de gange, min version brugte færre læsninger, sparede den i gennemsnit 75,9 mio. læsninger, og når den dynamiske SQL-version var hurtigere, sparede den 380.000 læsninger.
- Den samlede gennemsnitlige læsning for alle forsøg var Erik 8,4 mio., Peter 84 mio.
- Hvis der blev oprettet en opslagstabel for at bestemme, hvilken version der skal bruges (valg af den bedste til input), kunne alle resultater udføres i 8M læsninger. At bruge den dårligste hver gang ville tage 84,3 mio. læsninger.
Jeg ville være meget interesseret i at se resultaterne af en opdateret dynamisk SQL-version, der sætter den ekstra øvre grænse for de elementer, der vælges ved hvert trin, som jeg har beskrevet ovenfor.
Tillæg
Den følgende version af min forespørgsel opnår en forbedring på omkring 2,25 % i forhold til de præstationsresultater, der er anført ovenfor. Jeg brugte MIT's HAKMEM bit-tællemetode og tilføjede en Convert(int) på resultatet af row_number() da det giver en bigint. Selvfølgelig ville jeg ønske, at dette var den version, jeg havde brugt med til al ydeevnetestning og diagrammer og data ovenfor, men det er usandsynligt, at jeg nogensinde vil lave det om, da det var arbejdskrævende.
MED L0 AS (VÆLG 1 N UNION ALLE VÆLG 1),L1 AS (VÆLG 1 N FRA L0, L0 B),L2 AS (VÆLG 1 N FRA L1, L1 B),L3 AS (VÆLG 1 N FRA L2, L2 B), L4 AS (VÆLG 1 N FRA L3, L3 B), L5 AS (VÆLG 1 N FRA L4, L4 B), Tal AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Num FRA L5),Nums1 AS ( VÆLG Konverter(int, Num) Num FRA Nums WHERE Num MELLEM 1 OG Potens(2, @N) - 1), Nums2 AS ( SELECT Num, P1 =Num - ((Num / 2) &0xDB6DB6DB) - ((Num / 4) &0x49249249) FRA Nums1),Nums3 AS (SELECT Num, Bits =((P1 + P1 / 8) &0xC71C71C7) % 63 FROM Nums2),BaseSet AS (SELECT Ind =Power 2, Row_Number() OVER (ORDER BY Value) - 1), * FROM #Set)SELECT N.Num, S.ValueFROM Nums3 N INNER JOIN BaseSet S ON N.Num &S.Ind <> 0WHERE Bits =@K
Og jeg kunne ikke lade være med at vise en version mere, der foretager et opslag for at få antallet af bits. Det kan endda være hurtigere end andre versioner:
DECLARE @BitCounts binary(255) =0x01010201020203010202030203030401020203020303040203030403040405 + 0x0102020302030304020303040304040502030304030404050304040504050506 + 0x0102020302030304020303040304040502030304030404050304040504050506 + 0x0203030403040405030404050405050603040405040505060405050605060607 + 0x0102020302030304020303040304040502030304030404050304040504050506 + 0x0203030403040405030404050405050603040405040505060405050605060607 + 0x0203030403040405030404050405050603040405040505060405050605060607 + 0x0304040504050506040505060506060704050506050606070506060706070708;WITH L0 AS (SELECT 1 N UNION ALL SELECT 1),L1 AS (SELECT 1 N FROM L0, L0 B), L2 AS (VÆLG 1 N FRA L1, L1 B), L3 AS (VÆLG 1 N FRA L2, L2 B), L4 AS (VÆLG 1 N FRA L3, L3 B), L5 AS (VÆLG 1 N FRA L4, L4 B),Nums AS (SELECT Row_Number() OVER(ORDER BY (SELECT 1)) Antal FRA L5),Nums1 AS (SELECT Konverter(int, Num) Antal FRA Nums WHERE Num MELLEM 1 OG Potens(2) , @N) - 1),BaseSet AS (SELECT Ind =Power(2, Row_Number() OVER (ORDER BY Value) - 1), * FROM ComboSet)SELECT @Combination =N.Num, @Value =S.ValueFROM Nums1 N INNER JOIN BaseSet S ON N.Num &S.Ind <> 0WHERE @K =Convert(int, Substring(@BitCounts, N.Num &0xFF, 1)) + Convert(int, Substring(@BitCounts, N.Num / 256 &0xFF, 1)) + Convert(int, Substring (@BitCounts, N.Num / 65536 &0xFF, 1)) + Convert(int, Substring(@BitCounts, N.Num / 16777216, 1))