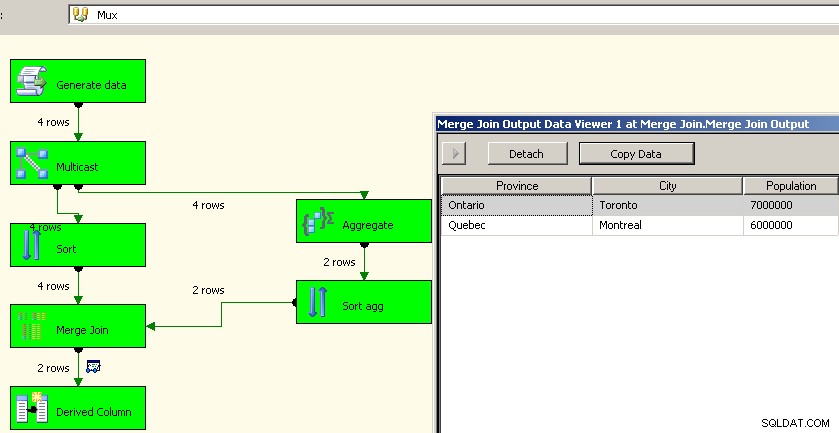
Fuldstændig enig med @PaulStock i, at aggregater bedst overlades til kildesystemer. Et aggregat i SSIS er en fuldt blokerende komponent, der ligner en slags, og jeg har har allerede fremsat mit argument på det punkt .
Men der er tidspunkter, hvor det at udføre disse operationer i kildesystemet bare ikke vil fungere. Det bedste, jeg har kunnet komme frem til, er stort set at fordoble dataene. Ja, ick, men jeg var aldrig i stand til at finde en måde at passere en kolonne upåvirket igennem. For Min/Max-scenarier vil jeg gerne have det som en mulighed, men noget som en sum ville naturligvis gøre det svært for komponenten at vide, hvilken "kilde"-rækken den vil knytte til.
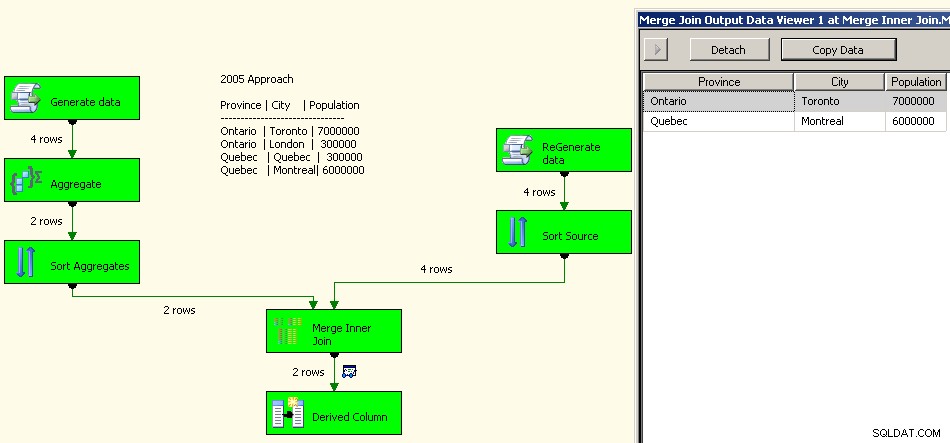
2005
En implementering i 2005 ville se sådan ud. Din præstation bliver ikke god, faktisk et par størrelsesordener fra god, da du vil have alle disse blokerende transformationer derinde ud over at skulle genbehandle dine kildedata.
Sammenflet deltagelse 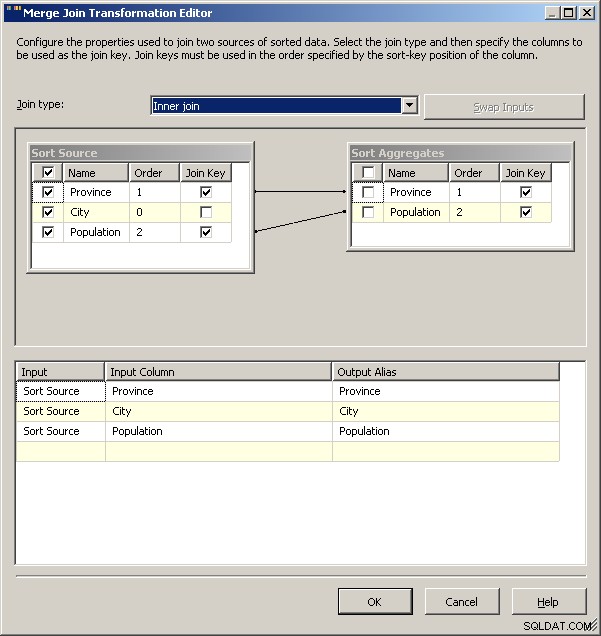
2008
I 2008 har du mulighed for at bruge Cache Connection Manager hvilket ville hjælpe med at eliminere de blokerende transformationer, i det mindste hvor det betyder noget, men du kommer stadig til at betale omkostningerne ved at dobbeltbehandle dine kildedata.
Træk to datastrømme ind på lærredet. Den første vil udfylde cacheforbindelsesadministratoren og bør være der, hvor sammenlægningen finder sted.
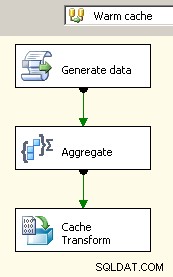
Nu hvor cachen har de aggregerede data derinde, skal du slippe en opslagsopgave i dit primære dataflow og udføre et opslag mod cachen.
Fanen Generelt opslag
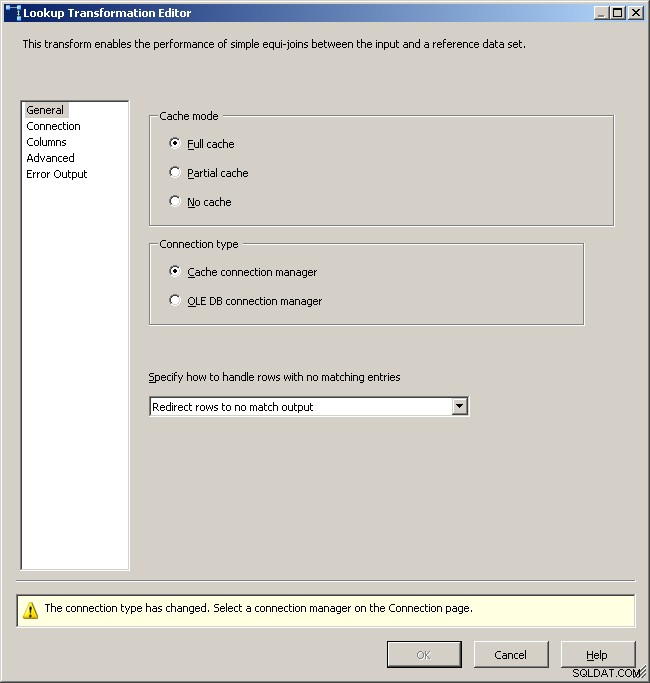
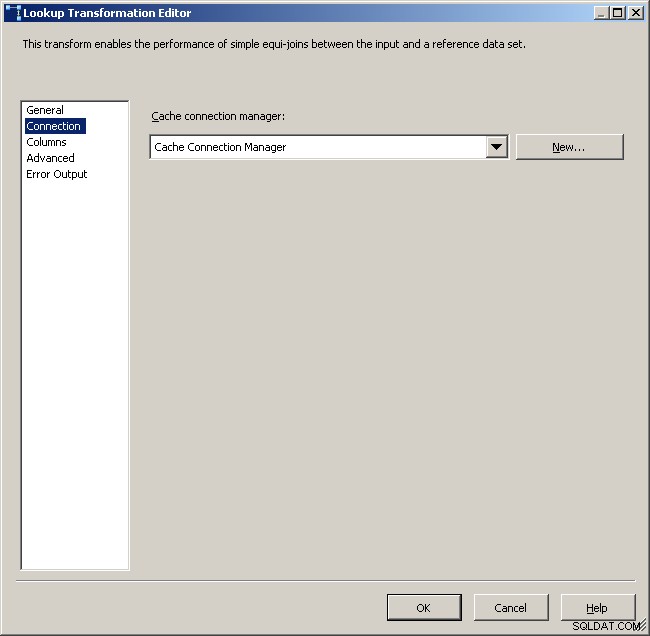
Vælg cacheforbindelsesadministratoren
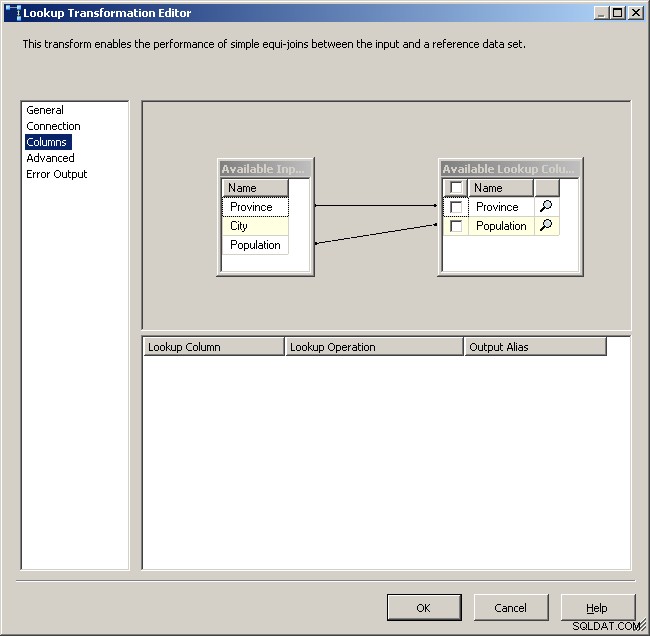
Kortlæg de relevante kolonner
Stor succes 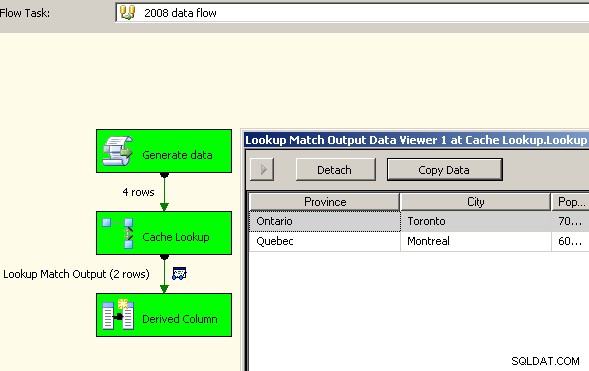
Scriptopgave
Den tredje tilgang, jeg kan komme i tanke om, 2005 eller 2008, er at skrive det selv. Som en generel regel forsøger jeg at undgå scriptopgaverne, men dette er et tilfælde, hvor det sandsynligvis giver mening. Du skal gøre det til en asynkron scripttransformation men bare håndtere dine sammenlægninger derinde. Mere kode at vedligeholde, men du kan spare dig selv for besværet med at genbehandle dine kildedata.
Til sidst, som en generel advarsel, vil jeg undersøge, hvad virkningen af bånd vil gøre for din løsning. For dette datasæt ville jeg forvente, at noget som Guelph pludselig ville svulme og binde Toronto, men hvis det gjorde, hvad skulle pakken så gøre? Lige nu vil begge dele resultere i 2 rækker for Ontario, men er det den tilsigtede adfærd? Script giver dig selvfølgelig mulighed for at definere, hvad der sker i tilfælde af bånd. Du kunne sandsynligvis stå 2008-løsningen på hovedet ved at cache de "normale" data og bruge dem som din opslagstilstand og bruge aggregaterne til at trække blot et af båndene tilbage. 2005 kan formentlig gøre det samme bare ved at sætte aggregatet som venstre kilde for flettesammenføjningen
Redigeringer
Jason Horner havde en god idé i sin kommentar. En anden tilgang ville være at bruge en multicast-transformation og udføre aggregeringen i én strøm og bringe den sammen igen. Jeg kunne ikke finde ud af, hvordan jeg skulle få det til at fungere med en fagforening, men vi kunne bruge sorteringer og fusionere, ligesom i ovenstående. Dette er sandsynligvis en bedre tilgang, da det sparer os for besværet med at genbehandle kildedataene.