Jeg formoder, at årsagen er, at de bare ikke har betragtet dette som en prioriteret funktion, der er værd at implementere. Det ser ud til, at Postgres gør understøtte begge dele
UNION og UNION ALL .
Hvis du har et stærkt argument for denne funktion, kan du give feedback på Forbind (eller hvad end URL'en til dens erstatning vil være).
Det kan være nyttigt at forhindre, at dubletter tilføjes, da en dubletrække, der tilføjes i et senere trin til en tidligere, næsten altid vil ende med at forårsage en uendelig løkke eller overskride den maksimale rekursionsgrænse.
Der er en del steder i SQL-standarderne
hvor kode bruges, der demonstrerer UNION såsom nedenfor
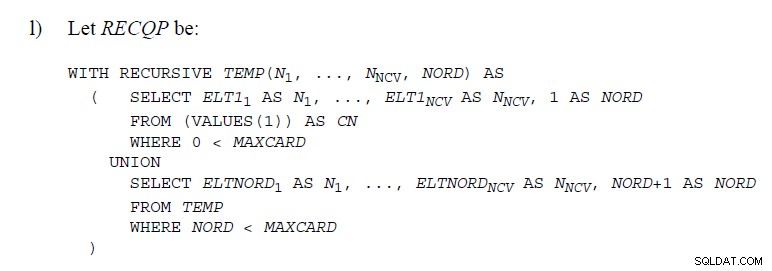
Denne artikel forklarer, hvordan de er implementeret i SQL Server . De laver ikke sådan noget "under hætten". Stakspolen sletter rækker, mens den går, så det ville ikke være muligt at vide, om en senere række er en duplikat af en slettet. Understøtter UNION ville have brug for en noget anden tilgang.
I mellemtiden kan du ganske nemt opnå det samme i en multi statement TVF.
For at tage et dumt eksempel nedenfor (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Ændring af UNION til UNION ALL og tilføje en DISTINCT i slutningen vil du ikke redde dig fra den uendelige rekursion.
Men du kan implementere dette som
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Ovenstående bruger IGNORE_DUP_KEY at kassere dubletter. Hvis kolonnelisten er for bred til at blive indekseret, skal du bruge DISTINCT og NOT EXISTS i stedet. Du vil sandsynligvis også have en parameter til at indstille det maksimale antal rekursioner og undgå uendelige loops.