
Begrænsninger i SQL Server er foruddefinerede regler, som du kan håndhæve på enkelte eller flere kolonner. Disse begrænsninger hjælper med at opretholde integriteten, pålideligheden og nøjagtigheden af værdier, der er gemt i disse kolonner. Du kan oprette begrænsninger ved at bruge CREATE TABLE eller ALTER Table-sætninger. Hvis du bruger ALTER TABLE-sætningen, vil SQL Server kontrollere de eksisterende kolonnedata, før begrænsningen oprettes.
Hvis du indsætter data i kolonnen, der opfylder begrænsningsregelkriterierne, indsætter SQL Server data med succes. Men hvis data overtræder begrænsningen, afbrydes insert-sætningen med en fejlmeddelelse.
Overvej for eksempel, at du har en [Medarbejder]-tabel, der gemmer din organisations medarbejderdata, inklusive deres løn. Der er et par tommelfingerregler, når det kommer til værdier i lønkolonnen.
- Kolonnen må ikke have negative værdier såsom -10.000 eller -15.000 USD.
- Du vil også angive den maksimale lønværdi. For eksempel bør den maksimale løn være mindre end 2.000.000 USD.
Hvis du indsætter en ny post med en begrænsning på plads, vil SQL Server validere værdien mod de definerede regler.
Indsat værdi:
Løn 80.000:Indsat med succes
Løn -50.000: Fejl
Vi vil undersøge følgende begrænsninger i SQL Server i denne artikel.
- IKKE NULL
- UNIKT
- TJEK
- PRIMÆR NØGLE
- UDLANDS NØGLE
- STANDARD
IKKE NULL-begrænsning
Som standard tillader SQL Server lagring af NULL-værdier i kolonner. Disse NULL-værdier repræsenterer ikke gyldige data.
For eksempel skal hver medarbejder i en organisation have et Emp ID, fornavn, køn og adresse. Derfor kan du angive en kolonne med IKKE NULL-begrænsninger for altid at sikre gyldige værdier.
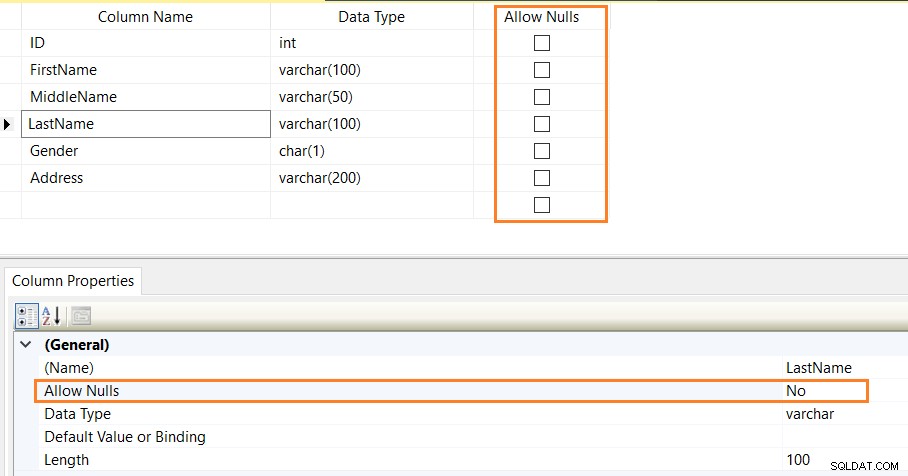
Nedenstående CREATE TABLE-script definerer NOT NULL-begrænsninger for kolonnerne [ID],[FirstName],[LastName],[Køn] og [Adresse].
CREATE TABLE Employees(ID INT NOT NULL,[FirstName] Varchar(100) NOT NULL,[MiddleName] Varchar(50) NULL,[Efternavn] Varchar(100) NOT NULL,[Køn] char(1) NOT NULL ,[Adresse] Varchar(200) NOT NULL)
For at validere NOT NULL-begrænsningerne, adfærd, bruger vi følgende INSERT-sætninger.
- Indsæt værdier for alle kolonner (NULL og IKKE NULL) – Indsættes korrekt
INSERT INTO Medarbejdere (ID,[FirstName],[Mellemnavn],[Efternavn],[køn],[Adresse]) VALUES(1,'Raj','','Gupta','M','Indien ')
- Indsæt værdier for kolonner med NOT NULL-egenskaben – Indsætter korrekt
INDSÆT I medarbejdere (ID,[Fornavn],[Efternavn],[køn],[Adresse]) VÆRDIER(2,'Shyam','Agarwal','M','UK')
- Spring over at indsætte værdier for kolonnen [Efternavn] med IKKE NULL-begrænsninger – Fails+
INSERT INTO Medarbejdere (ID,[FirstName],[køn],[Adresse]) VÆRDI(3,'Sneha','F','Indien')
Den sidste INSERT-sætning rejste fejlen – Kan ikke indsætte NULL-værdier i kolonnen .

Denne tabel har følgende værdier indsat i tabellen [Medarbejdere].
Antag, at vi ikke kræver NULL-værdier i kolonnen [MiddleName] i henhold til HR-kravene. Til dette formål kan du bruge ALTER TABLE-sætningen.
ALTER TABLE EmployeesALTER COLUMN [Mellenavn] VARCHAR(50) NOT NULL
Denne ALTER TABLE-sætning mislykkes på grund af de eksisterende værdier i kolonnen [MiddleName]. For at håndhæve begrænsningen skal du fjerne disse NULL-værdier og derefter køre ALTER-sætningen.
OPDATERING Medarbejdere SÆT [MiddleName]='' HVOR [MiddleName] ER NULLGoALTER TABLE EmployeesALTER COLUMN [MiddleName] VARCHAR(50) NOT NULL
Du kan også validere NOT NULL-begrænsningerne ved hjælp af SSMS-tabeldesigneren.
UNIQUE begrænsning
Den UNIKKE begrænsning i SQL Server sikrer, at du ikke har duplikerede værdier i en enkelt kolonne eller kombination af kolonner. Disse kolonner bør være en del af de UNIQUE begrænsninger. SQL Server opretter automatisk et indeks, når UNIQUE begrænsninger er defineret. Du kan kun have én unik værdi i kolonnen (inklusive NULL).
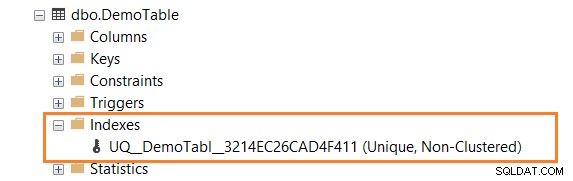
Opret f.eks. [DemoTabel] med kolonnen [ID] med UNIK begrænsning.
CREATE TABLE DemoTable([ID] INT UNIQUE NOT NULL,[EmpName] VARCHAR(50) NOT NULL)
Udvid derefter tabellen i SSMS, og du har et unikt indeks (Non-Clustered), som vist nedenfor.
Højreklik på indekset og generer dets script. Som vist nedenfor, bruger den ADD UNIQUE NOCLUSTERED nøgleordet til begrænsningen.

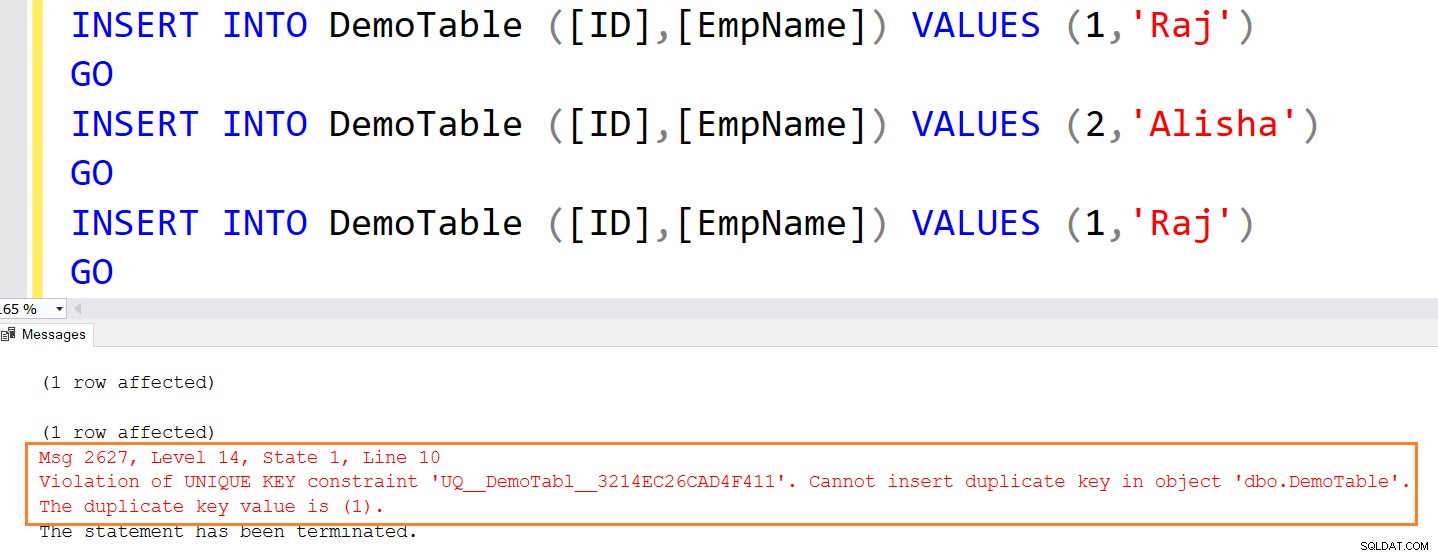
Følgende insert-sætning giver en fejl, fordi den forsøger at indsætte duplikerede værdier.
INSERT INTO DemoTable ([ID],[EmpName]) VALUES (1,'Raj')GOINSERT INTO DemoTable ([ID],[EmpName]) VALUES (2,'Alisha')GOINSERT INTO DemoTable ([ID] ,[EmpName]) VALUES (1,'Raj')GO
tjek begrænsning
CHECK-begrænsningen i SQL Server definerer et gyldigt interval af værdier, der kan indsættes i specificerede kolonner. Den evaluerer hver indsat eller ændret værdi, og hvis den er opfyldt, fuldføres SQL-sætningen.
Følgende SQL-script sætter en begrænsning for kolonnen [Alder]. Dens værdi bør være større end 18 år.
OPRET TABEL DemoCheckConstraint(ID INT PRIMARY KEY,[EmpName] VARCHAR(50) NULL,[Alder] INT CHECK (Alder>18))GO
Lad os indsætte to poster i denne tabel. Forespørgslen indsætter den første post med succes.
INSERT INTO DemoCheckConstraint (ID,[EmpName],[Age])VALUES (1,'Raj',20)GÅINDSÆT I DemoCheckConstraint (ID,[EmpName],[Alder])VALUES (2,'Sohan',17) )GO
Den anden INSERT-sætning mislykkes, fordi den ikke opfylder CHECK-betingelsen.
En anden brugssag for CHECK-begrænsningen er at gemme gyldige værdier af postnumre. I nedenstående script tilføjer vi en ny kolonne [ZipCode], og den bruger CHECK-begrænsningen til at validere værdierne.
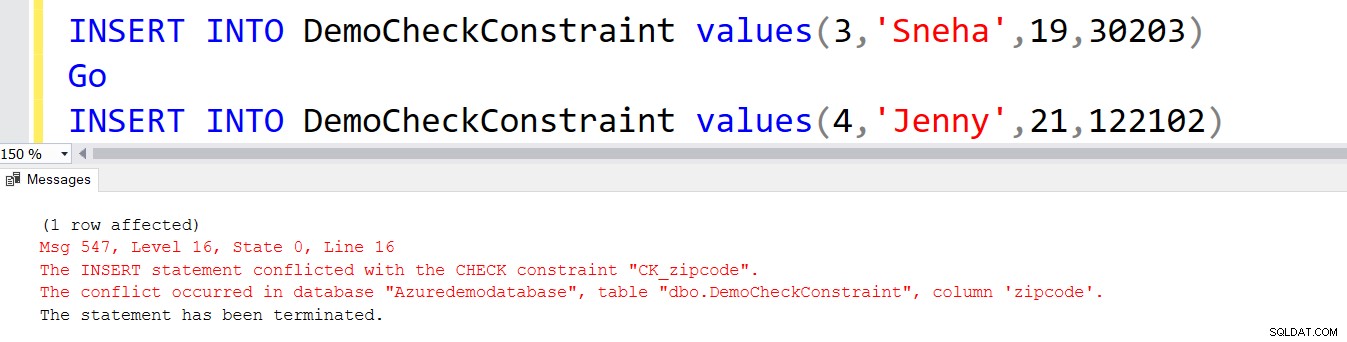
ÆNDRE TABEL DemoCheckConstraint TILFØJ postnummer intGOALTER TABEL DemoCheckConstraintADD BEGRÆNSNING CK_zipcode CHECK (postnummer LIKE REPLICATE ('[0-9]', 5)) Denne CHECK-begrænsning tillader ikke ugyldige postnumre. For eksempel genererer den anden INSERT-sætning en fejl.
INSERT INTO DemoCheckConstraint values(3,'Sneha',19,30203)GOINSERT INTO DemoCheckConstraint values(4,'Jenny',21,122102)
PRIMÆR NØGLE-begrænsning
PRIMARY KEY-begrænsningen i SQL Server er et populært valg blandt databaseprofessionelle til implementering af unikke værdier i en relationstabel. Den kombinerer UNIQUE og NOT NULL begrænsninger. SQL Server opretter automatisk et klynget indeks når vi definerer en PRIMÆR NØGLE-begrænsning. Du kan bruge en enkelt kolonne eller et sæt kombinationer til at definere unikke værdier i en række.
Dens primære formål er at håndhæve tabellens integritet ved hjælp af den unikke enheds- eller kolonneværdi.
Det ligner den UNIKKE begrænsning med følgende forskelle.
| PRIMÆR NØGLE | UNIK NØGLE |
| Den bruger en unik identifikator for hver række i en tabel. | Det definerer entydigt værdier i en tabelkolonne. |
| Du kan ikke indsætte NULL-værdier i kolonnen PRIMARY KEY. | Den kan acceptere én NULL-værdi i den unikke nøglekolonne. |
| En tabel kan kun have én PRIMÆR NØGLE-begrænsning. | Du kan oprette flere UNIQUE KEY-begrænsninger i SQL Server. |
| Som standard opretter den et klynget indeks for de PRIMÆRE NØGLE-kolonner. | Den UNIKKE NØGLE opretter et ikke-klynget indeks for de primære nøglekolonner. |
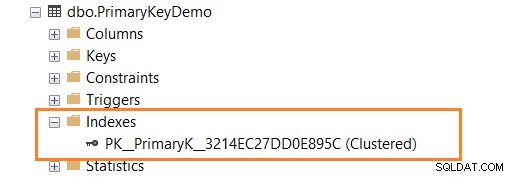
Følgende script definerer den PRIMÆRE NØGLE på ID-kolonnen.
OPRET TABEL PrimaryKeyDemo(ID INT PRIMARY KEY,[Navn] VARCHAR(100) NULL)
Som vist nedenfor har du et klynget nøgleindeks efter at have defineret den PRIMÆRE NØGLE i ID-kolonnen.
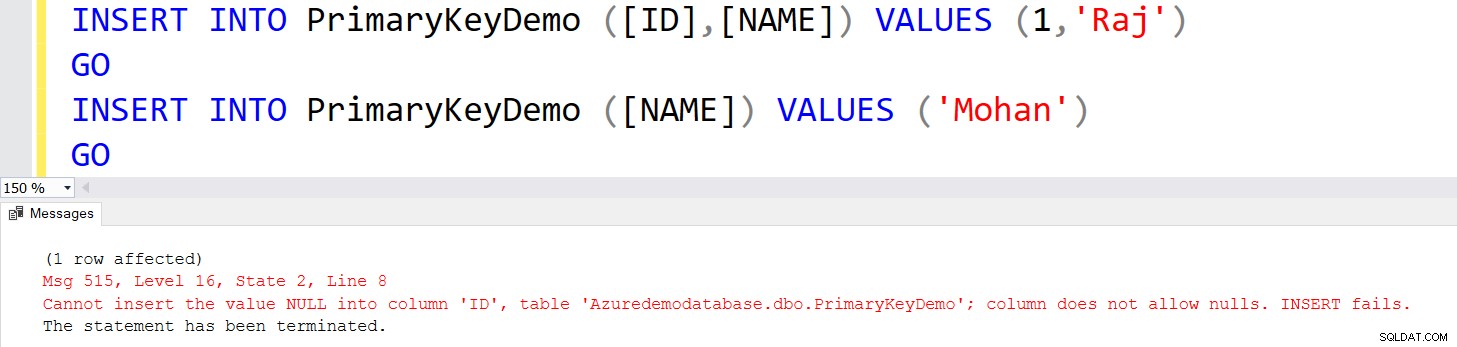
Lad os indsætte posterne i tabellen [PrimaryKeyDemo] med følgende INSERT-sætninger.
INDSÆT I PrimaryKeyDemo ([ID],[NAME]) VÆRDIER (1,'Raj')GOINDSÆT I PrimaryKeyDemo ([NAME]) VÆRDIER ('Mohan')GO Du får en fejl i den anden INSERT-sætning, fordi den forsøger at indsætte NULL-værdien.
På samme måde, hvis du forsøger at indsætte duplikerede værdier, får du følgende fejlmeddelelse.

FREIGN KEY-begrænsning
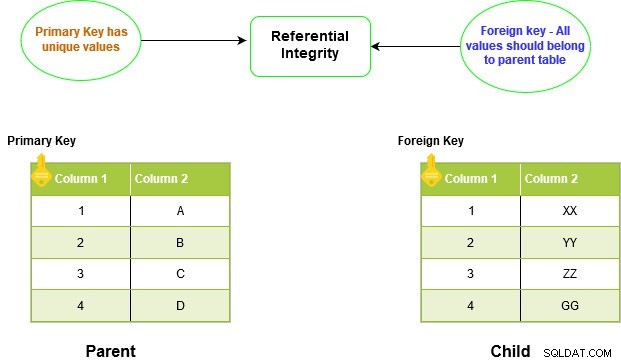
FOREIGN KEY-begrænsningen i SQL Server skaber relationer mellem to tabeller. Dette forhold er kendt som forældre-barn-forholdet. Det håndhæver referentiel integritet i SQL Server.
Den underordnede tabels fremmednøgle skal have en tilsvarende indgang i den overordnede primærnøglekolonne. Du kan ikke indsætte værdier i den underordnede tabel uden først at indsætte den i den overordnede tabel. På samme måde skal vi først fjerne værdien fra den underordnede tabel, før den kan slettes fra den overordnede tabel.
Da vi ikke kan have duplikerede værdier i PRIMARY KEY-begrænsningen, tillader den ikke duplikering eller NULL i den underordnede tabel.
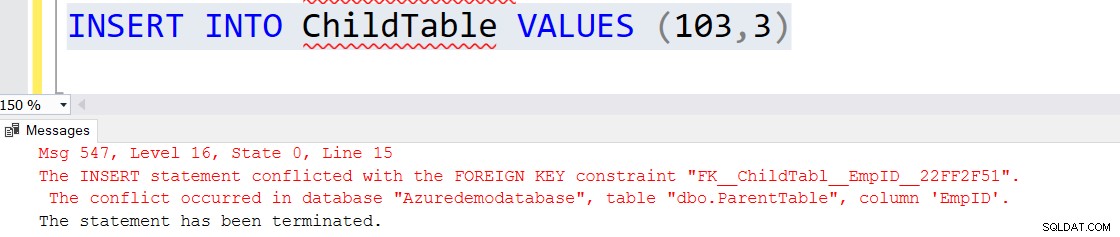
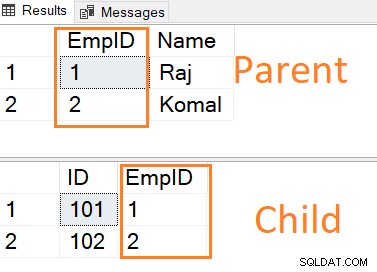
Følgende SQL-script opretter en overordnet tabel med en primær nøgle og en undertabel med en primær og fremmed nøglereference til den overordnede tabel [EmpID] kolonne.
CREATE TABLE ParentTable([EmpID] INT PRIMARY KEY,[Name] VARCHAR(50) NULL)GOCREATE TABLE ChildTable([ID] INT PRIMARY KEY,[EmpID] INT UDENLANDSKE NØGLEREFERENCER ParentTable(EmpID))Indsæt poster i begge tabeller. Bemærk, at den underordnede tabels fremmednøgleværdi har en indgang i den overordnede tabel.
INSERT INTO ParentTable VALUES (1,'Raj'),(2,'Komal')INSERT INTO ChildTable VALUES (101,1),(102,2)
Hvis du forsøger at indsætte en post direkte i den underordnede tabel, som ikke refererer til den overordnede tabels primære nøgle, får du følgende fejlmeddelelse.
STANDARD-begrænsning
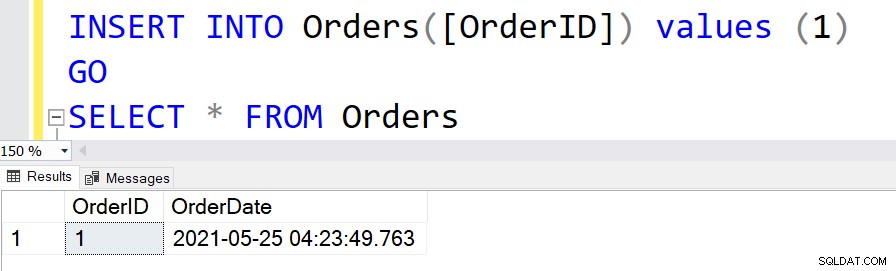
DEFAULT-begrænsningen i SQL Server giver standardværdien for en kolonne. Hvis vi ikke angiver en værdi i INSERT-sætningen for kolonnen med DEFAULT-begrænsningen, bruger SQL Server dens standard tildelte værdi. Antag for eksempel, at en ordretabel har poster for alle kundeordrer. Du kan bruge funktionen GETDATE() til at fange ordredatoen uden at angive nogen eksplicit værdi.
OPRET TABEL Ordrer([OrdreID] INT PRIMÆR NØGLE,[Ordredato] DATETIME IKKE NULL STANDARD GETDATE())GOFor at indsætte posterne i denne tabel kan vi springe over at tildele værdier til kolonnen [OrderDate].
INSERT INTO Orders([OrderID]) værdier (1)GOVÆLG * FRA Ordrer
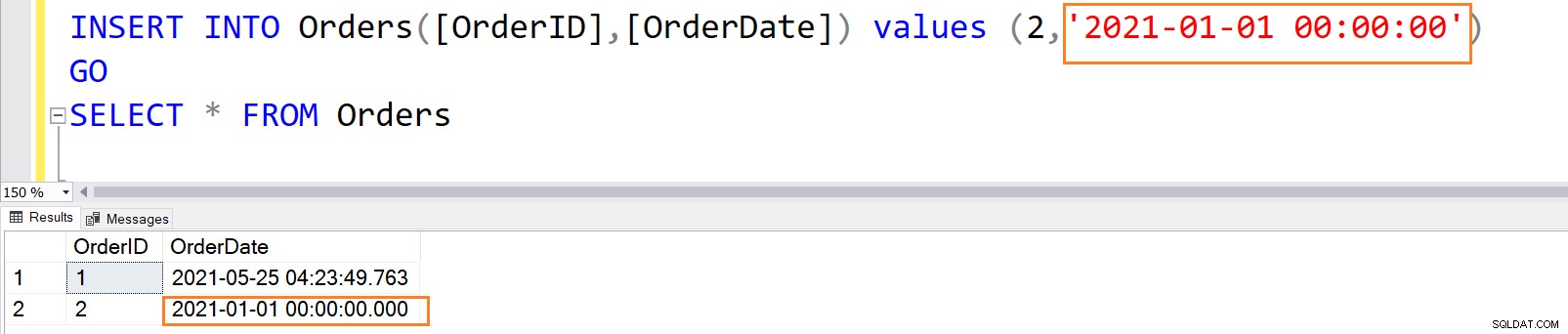
Når kolonnen DEFAULT-begrænsning angiver en eksplicit værdi, gemmer SQL Server denne eksplicitte værdi i stedet for standardværdien.
Begrænsningsfordele
Begrænsningerne i SQL Server kan være fordelagtige i følgende tilfælde:
- Håndhævelse af forretningslogik
- Håndhævelse af referenceintegritet
- Forebyggelse af lagring af ukorrekte data i SQL Server-tabeller
- Håndhævelse af unikhed for kolonnedata
- Forbedring af forespørgselsydeevne, da forespørgselsoptimeringsværktøjet er opmærksom på unikke data og validerer værdisæt
- Forhindrer lagring af NULL-værdier i SQL-tabeller
- Skriv koder for at undgå NULL, mens data vises i applikationen