Hej
Jeg vil fortsætte med at forklare databasesnapshots i SQL Server i denne artikel.
Læs tidligere artikler før dette indlæg.
SQL Server Database Snapshots -1
SQL Server Database Snapshots -2
SQL Server Database Snapshots -3
Denne fejl er meget skræmmende og økonomisk tab for produktionsdatabasen.
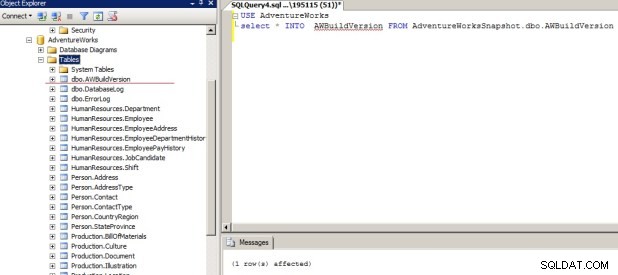
Vi vil bruge Snapshot-databasen til at vende tilbage fra denne fejl. Vi bruger AWBuildVersion-tabellen i Snapshot-databasen til at oprette AWBuildVersion-tabellen i AdventureWorks-databasen. Vi vil bruge Vælg * i kommandoen til dette. Skærmbilledet efter at have kørt scriptet er som følger. Som angivet med den røde linje, returneres Dropped Table til kildedatabasen med dens data.
Lad os gøre et andet lignende eksempel med hensyn til at være mere forståelig. Lad os slette dataene i enhver tabel og returnere dem fra Snapshot-databasen igen. Som beskrevet i billede 1.1 nedenfor slettes BillOfMaterials-tabellen nederst i ProductionWorks-databasen fra AdventureWorks-databasen. Når vi vælger tælleren Vælg samtidig, bliver 0-posten forespurgt som vist på billedet nedenfor.
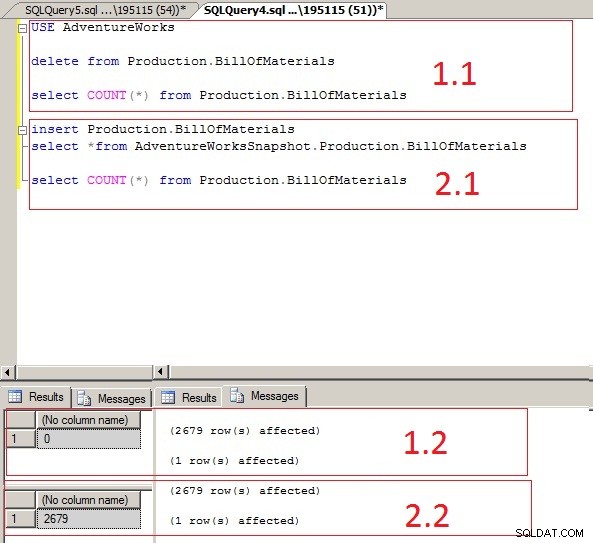
Vi bruger Snapshot-databasen igen for at vende tilbage fra denne fejl. Som i 2.1 ovenfor, indsætter vi det samme skema og tabel i Snapshot-databasen i den tilsvarende tabel i kildedatabasen. På samme måde indsættes det samme antal linjeposter som vist i billede 2.2, da vi forespurgte Select Count.
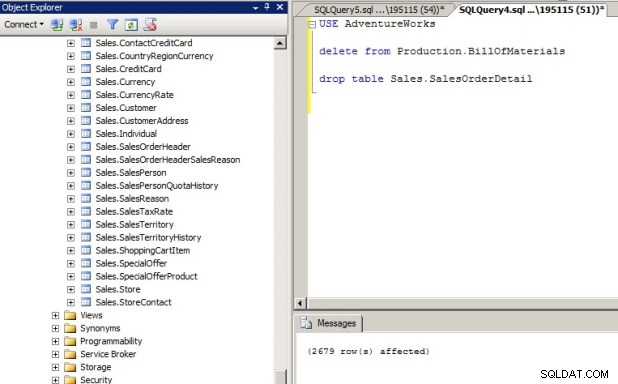
Lad os endelig lave en administratorfejl fra Snapshot-databasen, og denne gang vil vi gendanne kildedatabasen fra Snaphot-databasen. Således vender AdventureWorks-database-øjebliksbilledet tilbage til den oprindelige tilstand. Jeg sletter dataene i BillOfMaterials-tabellen fra produktionsskemaet, og samtidig droppede jeg SalesOrderDetail-tabellen under Sales-skemaet. Skærmbilledet er som følger. Da dataene i BillOfMaterials-tabellen i bunden af produktionsskemaet er blevet slettet, vises SalesOrderDetail-tabellen ikke, fordi den er slettet.
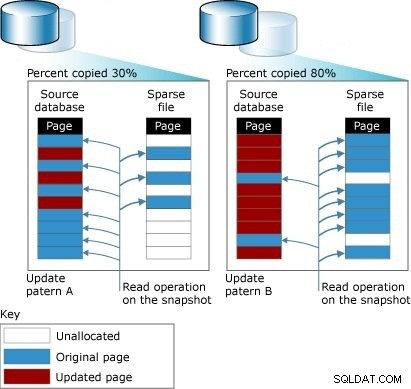
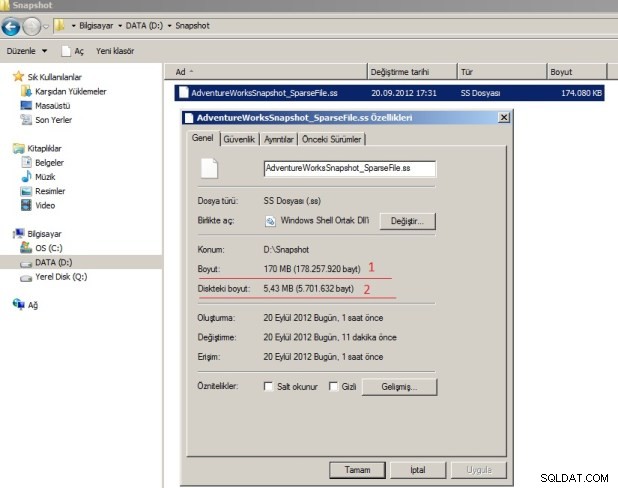
Vi lavede mange ændringer i kildedatabasen, vi har sagt, at disse ændringer altid skrives til Sparse File. Følgende billede viser den endelige version af Sparse-filen. Mens den originale størrelse 1 ikke er ændret, er den originale Sparse-fil nummer 2 øget. Grunden til dette er som sagt, at alle ændringer foretaget i Kildedatabasen er skrevet her. Så når brugeren læser ændrede data, læser den fra Sparse File. Hvis brugeren forespørger om uændrede data, vil de blive læst fra kildedatabasen.
Lad os nu vende tilbage til Snapshot.
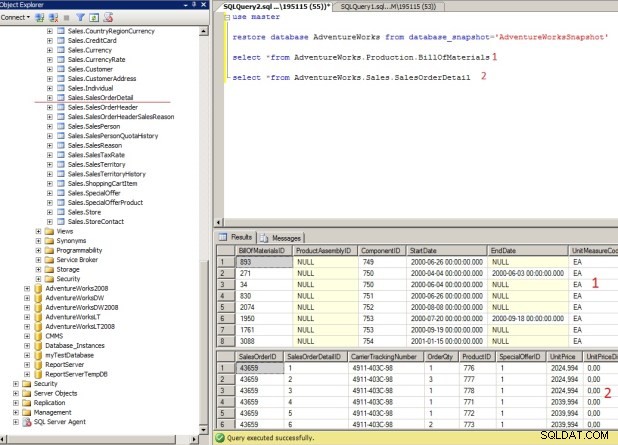
SQL Server 2017 Database Snaphot Restore coderestoredatabaseAdventureWorksfromdatabase_snapshot='AdventureWorksSnaphot'
Vi kan forespørge på alle tabte og slettede tabeller efter gendannelse af Snapshot som vist ovenfor.