De primære ændringer, der er foretaget i Cardinality Estimation, der starter med SQL Server 2014-udgivelsen, er beskrevet i Microsoft White Paper Optimizing Your Query Plans with SQL Server 2014 Cardinality Estimator af Joe Sack, Yi Fang og Vassilis Papadimos.
En af disse ændringer vedrører estimeringen af simple joins med et enkelt ligheds- eller ulighedsprædikat ved hjælp af statistiske histogrammer. I afsnittet med overskriften "Deltag ændringer af estimatalgoritme", introducerede papiret konceptet "grovjustering" ved brug af minimum og maksimum histogramgrænser:
For joinforbindelser med et enkelt ligheds- eller ulighedsprædikat forbinder det gamle CE histogrammerne på joinkolonnerne ved at justere de to histogrammer trin-for-trin ved hjælp af lineær interpolation. Denne metode kan resultere i inkonsistente kardinalitetsestimater. Derfor bruger den nye CE nu en enklere join-estimatalgoritme, der justerer histogrammer ved kun at bruge minimum og maksimum histogramgrænser.Selvom det er potentielt mindre konsistent, kan det gamle CE producere lidt bedre simple-sammenføjningstilstandsestimater på grund af trin-for-trin histogramjusteringen. Den nye CE bruger en grov linjeføring. Forskellen i estimater kan dog være lille nok til, at det er mindre sandsynligt, at det forårsager et problem med plankvaliteten.
Som en af de tekniske anmeldere af papiret følte jeg, at lidt flere detaljer omkring denne ændring ville have været nyttige, men det kom ikke med i den endelige version. Denne artikel tilføjer nogle af disse detaljer.
Eksempel på grov histogramjustering
grovjusteringen eksempel i hvidbogen bruger Data Warehouse-versionen af AdventureWorks-eksempeldatabasen. Trods navnet er databasen ret lille; backup er kun 22,3 MB og udvides til omkring 200 MB. Den kan downloades via links på AdventureWorks installations- og konfigurationsdokumentationsside.
Den forespørgsel, vi er interesseret i, slutter sig til FactResellerSales og FactCurrencyRate tabeller.
SELECT
FRS.ProductKey,
FRS.OrderDateKey,
FRS.DueDateKey,
FRS.ShipDateKey,
FCR.DateKey,
FCR.AverageRate,
FCR.EndOfDayRate,
FCR.[Date]
FROM dbo.FactResellerSales AS FRS
JOIN dbo.FactCurrencyRate AS FCR
ON FCR.CurrencyKey = FRS.CurrencyKey; Dette er en simpel equijoin på en enkelt kolonne så den kvalificerer sig til sammenføjningskardinalitet og selektivitetsestimering ved hjælp af histogram grovjustering.
Histogrammer
De histogrammer, vi skal bruge, er knyttet til CurrencyKey kolonne på hver sammenføjet tabel. På en ny kopi af AdventureWorksDW-databasen, den allerede eksisterende statistik for de større FactResellerSales tabellen er baseret på en prøve. For at maksimere reproducerbarheden og gøre de detaljerede beregninger så enkle som muligt at følge (undgå skalering), er det første, vi vil gøre, at opdatere statistikken ved hjælp af en fuld scanning:
UPDATE STATISTICS dbo.FactCurrencyRate WITH FULLSCAN; UPDATE STATISTICS dbo.FactResellerSales WITH FULLSCAN;
Disse tabeller har den demovenlige fordel at skabe små og enkle maxdiff histogrammer:
DBCC SHOW_STATISTICS
(FactResellerSales, CurrencyKey)
WITH HISTOGRAM;
DBCC SHOW_STATISTICS
(FactCurrencyRate, [PK_FactCurrencyRate_CurrencyKey_DateKey])
WITH HISTOGRAM;
Kombinering af minimum matchende histogramtrin
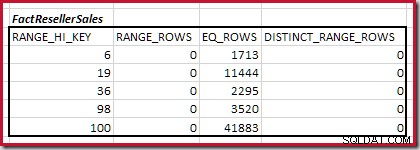
Det første trin i grovjusteringen beregningen er at finde bidraget til sammenslutningskardinaliteten, som det laveste matchende histogramtrin giver. For vores eksempelhistogrammer er den mindste matchende trinværdi på RANGE_HI_KEY = 6 :
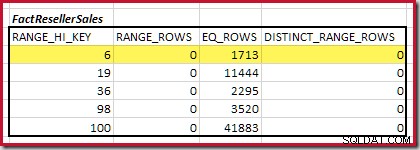
Den estimerede equijoin-kardinalitet for netop dette fremhævede trin er 1.713 * 1.158 =1.983.654 rækker .
Resterende matchede trin
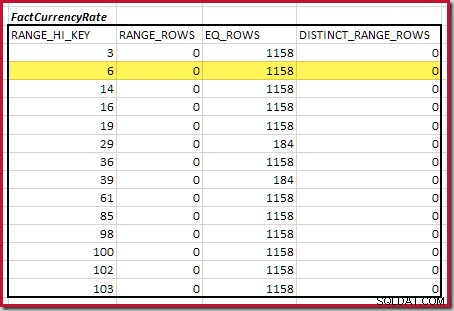
Dernæst skal vi identificere området for histogrammet RANGE_HI_KEY trin op til det maksimale for mulige equijoin-matches. Dette involverer at bevæge sig fremad fra det tidligere fundne minimum, indtil et af histograminputtet løber tør for rækker. De matchende equijoin-intervaller for det aktuelle eksempel er fremhævet nedenfor:
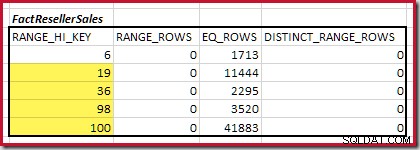
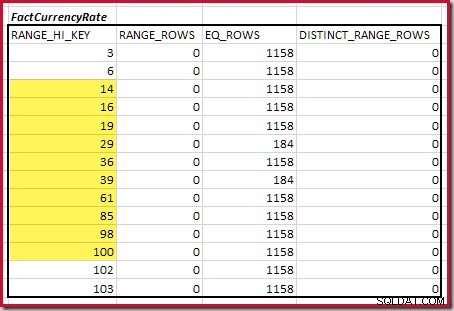
Disse to områder repræsenterer de resterende rækker, der kan forventes at bidrage til equijoin-kardinalitet.
Grov frekvensbaseret estimering
Spørgsmålet er nu, hvordan man udfører en grov estimering af equijoin-kardinaliteten af de fremhævede trin ved hjælp af den tilgængelige information.
Den oprindelige kardinalitetsestimator ville have udført en finkornet trin-for-trin histogramjustering ved brug af lineær interpolation, vurderet sammenføjningsbidraget for hvert trin (meget som vi gjorde for minimumstrinværdien før) og summeret hvert trinbidrag for at opnå en fuld tilslutningsvurdering. Selvom denne procedure giver meget intuitiv mening, var den praktiske erfaring, at denne finkornede tilgang tilføjede beregningsmæssig overhead og kunne producere resultater af variabel kvalitet.
Den oprindelige estimator havde en anden måde at estimere joinkardinalitet, når histograminformation enten ikke var tilgængelig eller heuristisk vurderet til at være ringere. Dette er kendt som en frekvensbaseret estimering og bruger følgende definitioner:
- C – kardinaliteten (antal rækker)
- D – antallet af distinkte værdier
- F – frekvensen (antal rækker) for hver enkelt værdi
- Bemærk C =D * F per definition
Effekten af en ækvijoin af relationerne R1 og R2 på hver af disse egenskaber er som vist nedenfor:
- F' =F1 * F2
- D' =MIN(D1; D2) – forudsat indeslutning
- C' =D' * F' (igen, per definition)
Vi er efter C', kardinaliteten af equijoin. Substituerer D' og F' i formlen og udvider:
- C' =D' * F'
- C' =MIN(D1; D2) * F1 * F2
- C' =MIN(D1 * F1 * F2; D2 * F1 * F2)
- nu, da C1 =D1 * F1 og C2 =D2 * F2:
- C' =MIN(C1 * F2, C2 * F1)
- endelig, da F =C/D (også per definition):
- C' =MIN(C1 * C2 / D2; C2 * C1 / D1)
Når man bemærker, at C1 * C2 er produktet af de to inputkardinaliteter (Cartesian join), er det klart, at minimum af disse udtryk vil være det med det højeste antal distinkte værdier:
- C' =(C1 * C2) / MAX(D1; D2)
I tilfælde af at alt virker lidt abstrakt, er en intuitiv måde at tænke på frekvensbaseret equijoin-estimering på at overveje, at hver særskilt værdi fra en relation vil forbindes med et antal rækker (gennemsnitsfrekvensen) i den anden relation. Hvis vi har 5 distinkte værdier på den ene side, og hver distinkte værdi på den anden side vises 3 gange i gennemsnit, er et fornuftigt (men groft) equijoin-estimat 5 * 3 =15.
Dette er ikke helt så bred en børste, som det kan se ud. Husk at kardinalitets- og distinkte værdier ovenfor ikke kommer fra hele relationen, men kun fra matchende trin over minimum. Derfor grov estimering mellem minimum og maksimum værdier.
Frekvensberegning
Vi kan få hver af disse parametre fra de fremhævede histogramtrin.
- Kardinaliteten C er summen af
EQ_ROWSogRANGE_ROWS. - Antallet af distinkte værdier D er summen af
DISTINCT_RANGE_ROWSplus én for hvert trin.
Kardinalitet C1 for matchende FactResellerSales trin er summen af de fremhævede celler:
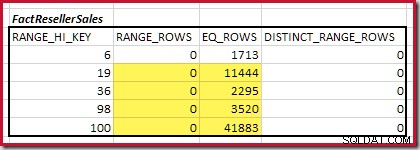
Dette giver C1 =59.142 rækker.
Der er ingen distinkte rækker, så de eneste distinkte værdier kommer fra selve de fire tringrænser, hvilket giver D1 =4 .
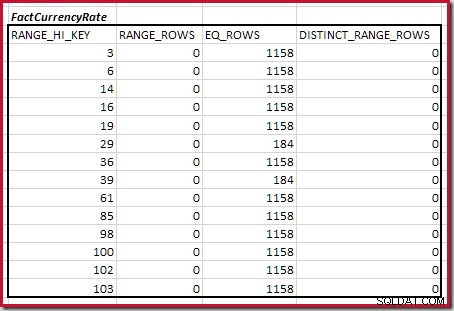
For det andet bord:
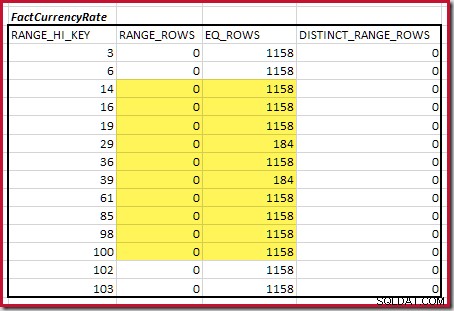
Dette giver C2 =9.632 . Igen er der ingen distinkte rækker, så de distinkte værdier kommer fra de ti trins grænser, D2 =10.
Udførelse af Equijoin-estimatet
Vi har nu alle de tal, vi skal bruge til equijoin-formlen:
- C' =(C1 * C2) / MAX(D1; D2)
- C' =(59142 * 9632) / MAX(4; 10)
- C' =569655744 / 10
- C' =56.965.574,4
Husk, at dette er bidraget fra histogramtrinene over den minimale matchede grænse. For at fuldføre estimeringen af joinkardinalitet skal vi tilføje bidraget fra de mindste matchende trinværdier, som var 1.713 * 1.158 =1.983.654 rækker.
Det endelige equijoin-estimat er derfor 56.965.574,4 + 1.983.654 =58.949.228,4 rækker eller 58.949.200 til seks væsentlige cifre.
Dette resultat bekræftes i den estimerede udførelsesplan for kildeforespørgslen:
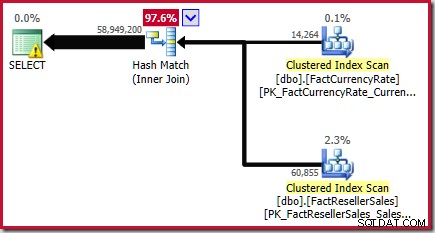
Som nævnt i hvidbogen er dette ikke et godt skøn. Det faktiske antal rækker, der returneres af denne forespørgsel, er 70.470.090 . Estimatet produceret af den oprindelige ("legacy") kardinalitetsestimator – ved hjælp af trin-for-trin histogramjustering – er 70.470.100 rækker.
Bedre resultater er ofte muligt med den finere metode, men kun hvis statistikken er en meget god repræsentation af den underliggende datafordeling. Dette er ikke blot et spørgsmål om at holde statistikken opdateret eller bruge fuld scanningspopulation. Algoritmen, der bruges til at pakke information i maksimalt 201 histogramtrin, er ikke perfekt, og under alle omstændigheder er mange datadistributioner i den virkelige verden simpelthen ikke i stand til en sådan histogramtroskab. I gennemsnit burde folk opleve, at den grovere metode giver helt passende skøn og større stabilitet med det nye CE.
Andet eksempel
Dette bygger lidt på det forrige eksempel og kræver ikke en prøvedatabasedownload.
DROP TABLE IF EXISTS
dbo.R1,
dbo.R2;
CREATE TABLE dbo.R1 (n integer NOT NULL);
CREATE TABLE dbo.R2 (n integer NOT NULL);
INSERT dbo.R1
(n)
VALUES
(1), (2), (3), (4), (5), (6), (7), (8), (9), (10),
(6), (6), (6), (6), (6), (6), (6), (6), (6), (6),
(6), (6), (6), (6), (6), (6), (6), (6), (6);
INSERT dbo.R2
(n)
VALUES
(5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15),
(10), (10);
CREATE STATISTICS stats_n ON dbo.R1 (n) WITH FULLSCAN;
CREATE STATISTICS stats_n ON dbo.R2 (n) WITH FULLSCAN; Histogrammerne, der viser matchede minimumstrin, er:
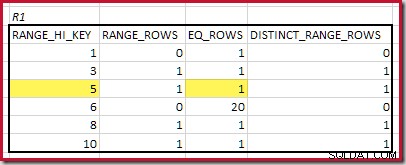
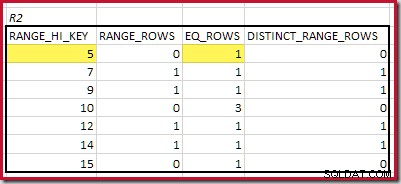
Den laveste RANGE_HI_KEY der matcher er 5. Værdien af EQ_ROWS er 1 i begge, så den estimerede equijoin-kardinalitet er 1 * 1 =1 række .
Den højeste matchende RANGE_HI_KEY er 10. Fremhævelse af R1-histogramrækkerne for grov frekvensbaseret estimering:
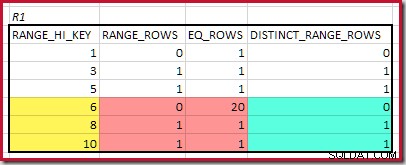
Opsummering af EQ_ROWS og RANGE_ROWS giver C1 =24 . Antallet af adskilte rækker er 2 DISTINCT_RANGE_ROWS (særlige værdier mellem trin) plus 3 for de forskellige værdier, der er knyttet til hver tringrænse, hvilket giver D1 =5 .
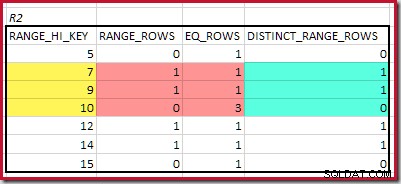
For R2 summeres EQ_ROWS og RANGE_ROWS giver C2 =7 . Antallet af adskilte rækker er 2 DISTINCT_RANGE_ROWS (adskilte værdier mellem trin) plus 3 for de forskellige værdier, der er knyttet til hver tringrænse, hvilket giver D2 =5 .
Equijoin-estimatet C' er:
- C' =(C1 * C2) / MAX(D1; D2)
- C' =(24 * 7) / 5
- C' =33,6
Tilføjelse i 1 række fra minimumstrin matchet giver et samlet estimat på 34,6 rækker for equijoin:
SELECT
R1.n,
R2.n
FROM dbo.R1 AS R1
JOIN dbo.R2 AS R2
ON R2.n = R1.n; Den estimerede udførelsesplan viser et estimat, der matcher vores beregning:

Dette er ikke helt rigtigt, men den "legacy" kardinalitetsestimator gør det ikke bedre, idet den estimerer 15,25 rækker versus 27 faktiske:

For en komplet behandling skal vi også tilføje et sidste bidrag fra matchende histogram nul-trin, men dette er ualmindeligt for equijoins (som typisk er skrevet for at afvise nuller) og en forholdsvis ligetil udvidelse for den interesserede læser.
Sidste tanker
Forhåbentlig vil detaljerne i artiklen udfylde et par huller for alle, der nogensinde har undret sig over "grov justering." Bemærk, at dette kun er en lille komponent i kardinalitetsberegningen. Der er adskillige andre vigtige koncepter og algoritmer, der bruges til join-estimering, især måden, som ikke-join-prædikater vurderes, og hvordan mere komplekse joins håndteres. Mange af de virkelig vigtige ting er ret godt dækket i hvidbogen.