Benjamin Nevarez er en uafhængig konsulent baseret i Los Angeles, Californien, som har specialiseret sig i tuning og optimering af SQL Server-forespørgsler. Han er forfatter til "SQL Server 2014 Query Tuning &Optimization" og "Inside the SQL Server Query Optimizer" og medforfatter til "SQL Server 2012 Internals". Med mere end 20 års erfaring i relationelle databaser har Benjamin også været foredragsholder ved mange SQL Server-konferencer, herunder PASS Summit, SQL Server Connections og SQLBits. Benjamins blog kan findes på https://www.benjaminnevarez.com, og han kan også nås via e-mail på admin på benjaminnevarez dot com og på twitter på @BenjaminNevarez.
Mens de fleste oplysninger, blogs og dokumentation om SQL Server 2014 har fokuseret på Hekaton og andre nye funktioner, er der ikke givet mange detaljer om den nye kardinalitetsberegning. I øjeblikket taler BOL kun indirekte om det i afsnittet Hvad er nyt (databasemotor) og siger, at SQL Server 2014 "inkluderer væsentlige forbedringer af den komponent, der opretter og optimerer forespørgselsplaner," og ALTER DATABASE erklæring viser, hvordan man aktiverer eller deaktiverer dens adfærd. Heldigvis kan vi få nogle yderligere oplysninger ved at læse forskningspapiret Testing Cardinality Estimation Models in SQL Server af Campbell Fraser et al. Selvom fokus for papiret er kvalitetssikringsprocessen for den nye estimeringsmodel, tilbyder den også en grundlæggende introduktion til den nye kardinalitetsestimator og motivationen for dens redesign.
Så hvad er en kardinalitetsberegning? En kardinalitetsestimator er den komponent i forespørgselsprocessoren, hvis opgave er at estimere antallet af rækker, der returneres af relationelle operationer i en forespørgsel. Disse oplysninger, sammen med nogle andre data, bruges af forespørgselsoptimeringsværktøjet til at vælge en effektiv eksekveringsplan. Kardinalitetsestimering er i sagens natur upræcis, da det er en matematisk model, der er afhængig af statistisk information. Den er også baseret på flere antagelser, som, selvom de ikke er dokumenterede, har været kendt gennem årene - nogle af dem omfatter ensartethed, uafhængighed, indeslutning og inklusion. En kort beskrivelse af disse antagelser følger.
- Ensartethed . Bruges, når fordelingen for en attribut er ukendt, f.eks. inden for rækker i rækker i et histogramtrin, eller når et histogram ikke er tilgængeligt.
- Uafhængighed . Bruges, når attributterne i en relation er uafhængige, medmindre en sammenhæng mellem dem er kendt.
- Indeslutning . Brugt, når to attributter kan være ens, antages de at være ens.
- Inkludering . Brugt når man sammenligner en attribut med en konstant, antages det, at der altid er et match.
Det er interessant, at jeg for nylig talte om nogle af begrænsningerne ved disse antagelser ved min sidste tale på PASS-topmødet, kaldet Bekæmpelse af begrænsningerne af forespørgselsoptimeringsværktøjet. Alligevel blev jeg overrasket over at læse i avisen, at forfatterne indrømmer, at disse antagelser ifølge deres erfaring i praksis er "ofte forkerte."
Den nuværende kardinalitetsestimator blev skrevet sammen med hele forespørgselsprocessoren til SQL Server 7.0, som blev frigivet tilbage i december 1998. Denne komponent har naturligvis været udsat for adskillige ændringer i løbet af flere år og flere udgivelser af SQL Server, inklusive rettelser, justeringer og udvidelser til imødekomme kardinalitetsestimat for nye T-SQL-funktioner. Så du tænker måske, hvorfor udskifte en komponent, som har været brugt med succes i omkring 15 år?
Hvorfor en ny kardinalitetsvurdering
Papiret forklarer nogle af årsagerne til redesignet, herunder:
- For at tilpasse kardinalitetsberegningen til nye arbejdsbelastningsmønstre.
- Ændringer foretaget i kardinalitetsberegningen gennem årene gjorde komponenten svær at "fejle, forudsige og forstå."
- At forsøge at forbedre den nuværende model var svært ved at bruge den nuværende arkitektur, så et nyt design blev oprettet, fokuseret på adskillelsen af opgaverne med (a) at beslutte, hvordan man beregner et bestemt estimat, og (b) faktisk at udføre beregningen .
Jeg er ikke sikker på, om flere detaljer om den nye kardinalitetsestimator vil blive udgivet af Microsoft. Der blev trods alt aldrig publiceret så mange detaljer om den gamle kardinalitetsberegning i 15 år; for eksempel hvordan en specifik kardinalitetsestimat beregnes. På den anden side er der nye udvidede hændelser, som vi kan bruge til at fejlfinde problemer med kardinalitetsestimering, eller bare til at udforske, hvordan det fungerer. Disse hændelser inkluderer query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors og query_rpc_set_cardinality .
Planlæg regression
En stor bekymring, der kommer til at tænke på med sådan en enorm ændring i forespørgselsoptimeringsværktøjet, er planregression. Frygten for planregression er blevet betragtet som den største hindring for forbedringer af forespørgselsoptimering. Regressioner er problemer, der introduceres, efter at en rettelse er blevet anvendt på forespørgselsoptimeringsværktøjet og nogle gange omtales som det klassiske "to forkerte gør en ret." Dette kan ske, når to dårlige estimeringer, for eksempel den ene overvurderer en værdi og den anden, der undervurderer den, ophæver hinanden, hvilket heldigvis giver et godt estimat. Korrigering af kun én af disse værdier kan nu føre til et dårligt estimat, som kan have en negativ indvirkning på valget af planvalg og forårsage en regression.
For at hjælpe med at undgå regressioner relateret til den nye kardinalitetsberegning giver SQL Server en måde at aktivere eller deaktivere den på, da det afhænger af databasekompatibilitetsniveauet. Dette kan ændres ved hjælp af ALTER DATABASE erklæring, som tidligere nævnt. Indstilling af en database til kompatibilitetsniveau 120 vil bruge den nye kardinalitetsestimator, mens et kompatibilitetsniveau mindre end 120 vil bruge den gamle kardinalitetsestimator. Derudover, når du først bruger en specifik kardinalitetsberegning, er der to sporingsflag, du kan bruge til at skifte til den anden. Selvom jeg i øjeblikket ikke kan se sporingsflaggene dokumenteret nogen steder, er de nævnt som en del af beskrivelsen af query_optimizer_force_both_cardinality_estimation_behaviors udvidet arrangement. Sporingsflag 2312 kan bruges til at aktivere den nye kardinalitetsestimator, mens sporingsflag 9481 kan bruges til at deaktivere det. Du kan endda bruge sporingsflaggene til en specifik forespørgsel ved hjælp af QUERYTRACEON tip (selvom det endnu ikke er dokumenteret, om dette heller vil blive understøttet).
Eksempler
Endelig nævner papiret også nogle testede scenarier som den overbefolkede primærnøgle, simple join eller det stigende nøgleproblem. Det viser også, hvordan forfatterne eksperimenterede med flere scenarier (eller modelvariationer) og i nogle tilfælde "slappede af" nogle af antagelserne fra kardinalitetsestimatoren, for eksempel i tilfælde af uafhængighedsantagelsen, fra fuldstændig uafhængighed til fuldstændig korrelation. og noget midt imellem, indtil der blev fundet gode resultater.
Selvom der ikke er angivet nogen detaljer på papiret, beslutter jeg mig for at begynde at teste nogle af disse scenarier for at prøve at forstå, hvordan den nye kardinalitetsestimator fungerer. For nu vil jeg vise dig et eksempel ved at bruge uafhængighedsantagelsen og stigende nøgler. Jeg testede også ensartethedsantagelsen, men indtil videre har jeg ikke kunnet finde nogen forskel på estimering.
Lad os starte med eksemplet med uafhængighedsantagelse. Lad os først se den aktuelle adfærd. Til det skal du sikre dig, at du bruger den gamle kardinalitetsestimator ved at køre følgende erklæring på AdventureWorks2012-databasen:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Kør derefter:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Vi får anslået 196 poster som vist næste:

På lignende måde vil følgende udsagn blive anslået til 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Hvis vi bruger begge prædikater, har vi følgende forespørgsel, som vil have et estimeret antal rækker på 1,93862 (rundet op til 2 rækker, hvis du bruger SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Denne værdi beregnes under forudsætning af total uafhængighed af begge prædikater, som bruger formlen (196 * 194) / 19614.0 (hvor 19614 er det samlede antal rækker i tabellen). Brug af en samlet korrelation burde give os et estimat på 194, da alle posterne med postnummer 91502 tilhører Burbank. Den nye kardinalitetsestimator estimerer en værdi, der ikke antager total uafhængighed eller total korrelation. Skift til den nye kardinalitetsestimator ved at bruge følgende sætning:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
At køre den samme sætning igen vil give et estimat på 19.3931 rækker, som du kan se er en værdi mellem at antage total uafhængighed og total korrelation (rundet op til 19 rækker i Plan Explorer). Den anvendte formel er selektiviteten af det mest selektive filter * SQRT(selektiviteten af det næstmest selektive filter) eller (194/19614.0) * SQRT(196/19614.0) * 19614, hvilket giver 19.393:

Hvis du har aktiveret den nye kardinalitetsestimator på databaseniveau, vil du gerne deaktivere den for en specifik forespørgsel for at undgå en planregression, kan du bruge sporingsflag 9481 som forklaret tidligere:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Bemærk:QUERYTRACEON-forespørgselstippet bruges til at anvende et sporingsflag på forespørgselsniveauet, og i øjeblikket understøttes det kun i et begrænset antal scenarier. For mere information om QUERYTRACEON-forespørgselstip kan du se https://support.microsoft.com/kb/2801413.
Lad os nu se på det stigende nøgleproblem, et emne, jeg har forklaret mere detaljeret i dette indlæg. Den traditionelle anbefaling fra Microsoft for at løse dette problem er manuelt at opdatere statistik efter indlæsning af data, som forklaret her – hvilket beskriver problemet på følgende måde:
Statistik over stigende eller faldende nøglekolonner, såsom IDENTITY eller tidsstempelkolonner i realtid, kræver muligvis hyppigere statistikopdateringer, end forespørgselsoptimeringsværktøjet udfører. Indsæt-handlinger føjer nye værdier til stigende eller faldende kolonner. Antallet af tilføjede rækker kan være for lille til at udløse en statistikopdatering. Hvis statistikken ikke er opdateret, og forespørgsler vælges fra de senest tilføjede rækker, vil den aktuelle statistik ikke have kardinalitetsestimater for disse nye værdier. Dette kan resultere i unøjagtige kardinalitetsestimater og langsom forespørgselsydeevne. For eksempel vil en forespørgsel, der vælger fra de seneste salgsordredatoer, have unøjagtige kardinalitetsestimater, hvis statistikken ikke opdateres til at inkludere kardinalitetsestimater for de seneste salgsordredatoer.
Anbefalingen i min artikel var at bruge sporingsflag 2389 og 2390, som først blev udgivet af Ian Jose i hans artikel Ascending Keys and Auto Quick Corrected Statistics. Du kan læse min artikel for en forklaring og et eksempel på, hvordan du bruger disse sporingsflag for at undgå dette problem. Disse sporingsflag fungerer stadig på SQL Server 2014 CTP2. Men endnu bedre, de er ikke længere nødvendige, hvis du bruger den nye kardinalitetsestimator.
Bruger det samme eksempel i mit indlæg:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Indsæt nogle data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Siden vi har oprettet et indeks, har vi netop fået ny statistik. Kørsel af følgende forespørgsel vil skabe et godt estimat på 35 rækker:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Hvis vi indsætter nye data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Du kan se estimatet med den gamle kardinalitetsestimator som vist næste:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Da det lille antal indsatte poster ikke var nok til at udløse en automatisk opdatering af statistikobjektet, er det aktuelle histogram ikke bekendt med de nye tilføjede poster, og forespørgselsoptimeringsværktøjet bruger et estimeret antal 1 række. Du kan eventuelt bruge sporingsflag 2389 og 2390 for at hjælpe med at opnå et bedre skøn. Men hvis du prøver den samme forespørgsel med den nye kardinalitetsberegning, får du følgende estimat:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
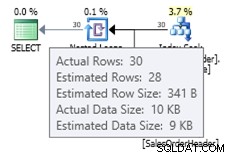
I dette tilfælde får vi en bedre estimering end den gamle kardinalitetsestimator (eller vi får samme estimering som ved at bruge sporingsflag 2389 eller 2390). Den estimerede værdi på 27,9631 (igen, afrundet til 28 af Plan Explorer) beregnes ved hjælp af tæthedsoplysningerne for statistikobjektet ganget med antallet af rækker i tabellen; det vil sige 0,0008992806 * 31095. Tæthedsværdien kan opnås ved at bruge:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Til sidst skal du huske på, at intet nævnt i denne artikel er dokumenteret, og det er den adfærd, jeg hidtil har observeret i SQL Server 2014 CTP2. Alt dette kan ændre sig i en senere CTP- eller RTM-version af produktet.