Introduktion
En tabel er en logisk struktur. Når du opretter en tabel, vil du typisk være ligeglad med, hvilke drev den sidder på ved lagerlaget. Men hvis du er en databaseadministrator, kan denne viden blive vigtig, hvis du skal flytte visse databasedele til alternativ lagring eller volumen. Så vil du måske have bestemte tabeller på en bestemt diskenhed eller et sæt diske.
Filgrupper i SQL Server tilbyder det abstraktionslag, der giver os mulighed for at kontrollere den fysiske placering af vores logiske strukturer – tabeller, indekser osv.
Filgrupper
En filgruppe er en logisk struktur til gruppering af datafiler i SQL Server. Hvis vi opretter en filgruppe og knytter den til et sæt datafiler, vil ethvert logisk objekt, der er oprettet på den filgruppe, være fysisk placeret på det sæt fysiske filer.
Det primære formål med en sådan fysisk filgruppering er dataallokering og dataplacering. For eksempel vil vi have vores transaktionsdata gemt på ét sæt hurtige diske. Samtidig har vi brug for de historiske data gemt på et andet sæt billigere diske. I et sådant scenarie ville vi oprette Tran tabellen på TXN-filgruppen og TranHist tabel på en anden HIST-filgruppe. Længere i denne artikel skal vi se, hvordan dette oversættes til at have data på forskellige diske.
Oprettelse af filgrupper
Syntaksen for oprettelse af filgrupper er vist i Liste 1 . Bemærk :Databasekonteksten er master database. Når vi udsteder erklæringerne, ændrer vi DB2-databasen ved at tilføje nye filgrupper til den. I det væsentlige er disse filgrupper kun logiske konstruktioner på dette tidspunkt. De indeholder ingen data.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Tilføjelse af filer til filgrupper
Det næste trin er at tilføje en fil til hver af filgrupperne. Vi kan tilføje mere end én fil, men vi holder det enkelt til demonstrationsformål. Bemærk, at hver fil er på et helt andet drev, og syntaksen giver os mulighed for at angive den tilsigtede filgruppe.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Oprettelse af tabeller til filgrupper
Her sikrer vi, at tabeller er på ønskede diske. Syntaksen til at oprette tabeller giver os mulighed for at angive den filgruppe, vi ønsker.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Tager vi et skridt tilbage, bemærker vi, at vi nu har opnået følgende:
- Oprettet to filgrupper.
- Bestemte de datafiler (og diske), der er knyttet til hver filgruppe.
- Bestemte de tabeller, der er knyttet til hver filgruppe.
I bund og grund er filgruppen abstraktionslaget .
Tjekker, hvilke filgrupper vores borde sidder på
For at kontrollere, hvilken filgruppe hver tabel tilhører, udfører vi koden i liste 4. Vi bruger to hovedsystemkatalogvisninger:sys.indexes og sys.data_spaces . sys.data_spaces katalogvisningen indeholder information om filgrupper og partitioner og de vigtigste logiske strukturer, hvor tabeller og indekser er gemt.
Bemærk:Vi brugte ikke sys.tables . SQL Serveren forbinder indekser i en tabel med datarum snarere end tabeller, som vi måske intuitivt tror.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
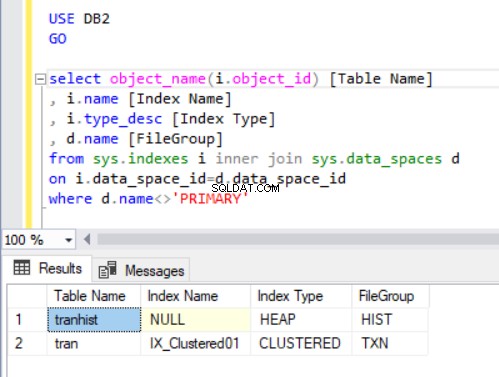
Outputtet af forespørgslen i liste 4 viser to tabeller, vi lige har oprettet. Bemærk, at tranhisten tabel har ikke et indeks. Alligevel dukker det op i resultatsættet, identificeret som en dynge .
En dynge er en tabel, der ikke har noget klynget indeks, der bestemmer de ordredata, der fysisk er lagret i en tabel. Der kan kun være ét klynget indeks i en tabel.
Population af Trans-tabellen
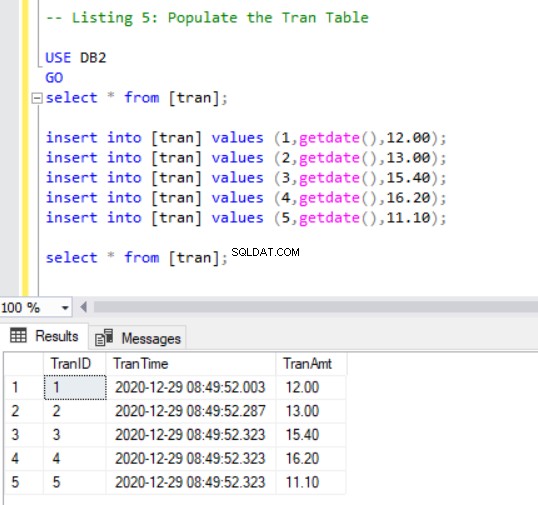
Nu skal vi tilføje et par poster til trans tabel ved hjælp af følgende kode:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Flytning af en tabel til en anden filgruppe
For at flytte tran tabel til en anden filgruppe, behøver vi kun at genopbygge det klyngede indeks og angiv den nye filgruppe, mens du udfører denne genopbygning. Liste 5 viser denne tilgang.
Vi udfører to trin:Slip først indekset, og genskab det derefter. Ind imellem kontrollerer vi for at bekræfte, at dataene og placeringen af de to tabeller, vi oprettede tidligere, forbliver intakte.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Ved at droppe det klyngede indeks fra tran tabel, har vi konverteret den til en heap :
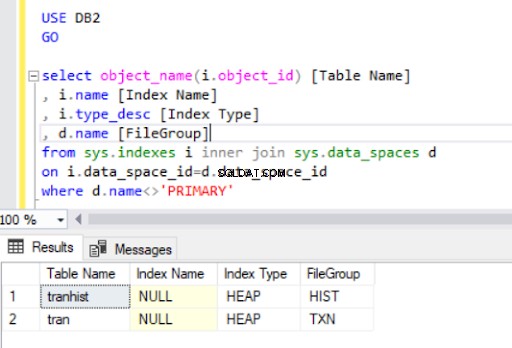
Når vi genskaber det klyngede indeks, bliver det også vist i Listing 4-outputtet.
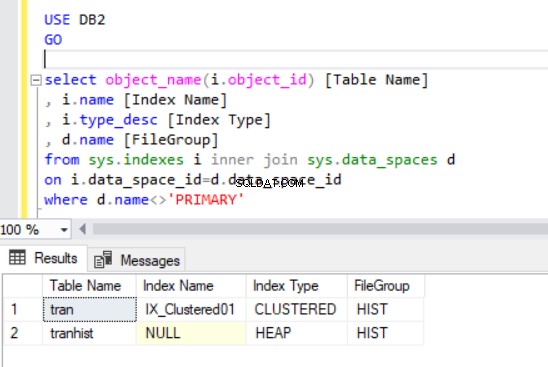
Nu har vi tran tabel på HIST-filgruppen.
Konklusion
Denne artikel demonstrerede forholdet mellem tabeller, indekser, filer og filgrupper med hensyn til vores SQL Server-datalagring. Vi har også forklaret at flytte en tabel fra en filgruppe til en anden ved at genskabe det klyngede indeks.
Denne færdighed vil være nyttig, når du skal migrere data til nyt lager (hurtigere diske eller langsommere diske til arkivering). I mere avancerede scenarier kan du bruge filgrupper til at administrere datalivscyklussen ved at implementere tabelpartitioner.
Referencer
- Databasefiler og filgrupper
- Udskiftning af bordpartitioner – en gennemgang