Ifølge Wikipedia er bulkinsert en proces eller metode leveret af et databasestyringssystem til at indlæse flere rækker af data i en databasetabel. Hvis vi justerer denne forklaring til BULK INSERT-sætningen, tillader bulk-indsættelsen import af eksterne datafiler til SQL Server.
Antag, at vores organisation har en CSV-fil på 1.500.000 rækker, og vi ønsker at importere den til en bestemt tabel i SQL Server for at bruge BULK INSERT-sætningen i SQL Server. Vi kan finde flere metoder til at håndtere denne opgave. Det kunne være at bruge BCP (b ulk c opy p rogram), SQL Server Import og Export Wizard eller SQL Server Integration Service-pakke. BULK INSERT-erklæringen er dog meget hurtigere og potent. En anden fordel er, at den tilbyder adskillige parametre, der hjælper med at bestemme procesindstillingerne for masseindsættelse.
Lad os starte med en grundlæggende prøve. Derefter vil vi gennemgå mere sofistikerede scenarier.
Forberedelse
Først og fremmest har vi brug for en eksempel-CSV-fil. Vi downloader en eksempel-CSV-fil fra E for Excel-webstedet (en samling af samplede CSV-filer med et andet rækkenummer). Her skal vi bruge 1.500.000 salgsposter.
Download en zip-fil, udpak den for at få en CSV-fil, og placer den på dit lokale drev.
Importér CSV-fil til SQL Server-tabel
Vi importerer vores CSV-fil til destinationstabellen i den enkleste form. Jeg placerede min eksempel-CSV-fil på C:-drevet. Nu opretter vi en tabel for at importere CSV-fildata til den:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Følgende BULK INSERT-sætning importerer CSV-filen til salgstabellen:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Du har sikkert bemærket de specifikke parametre i ovenstående masseindsættelseserklæring. Lad os præcisere dem:
- FIRSTROW angiver startpunktet for insert-sætningen. I eksemplet nedenfor vil vi springe kolonneoverskrifter over, så vi indstiller denne parameter til 2.

- FIELDTERMINATOR definerer det tegn, der adskiller felter fra hinanden. SQL Server registrerer hvert felt på denne måde.
- ROWTERMINATOR adskiller sig ikke meget fra FIELDTERMINATOR. Den definerer rækkernes adskillelseskarakter.
I eksempel-CSV-filen er FIELDTERMINATOR meget tydelig, og den er et komma (,). For at finde denne parameter skal du åbne CSV-filen i Notepad++ og navigere til Vis -> Vis symbol -> Vis alle chartre. CRLF-tegnene er i slutningen af hvert felt.
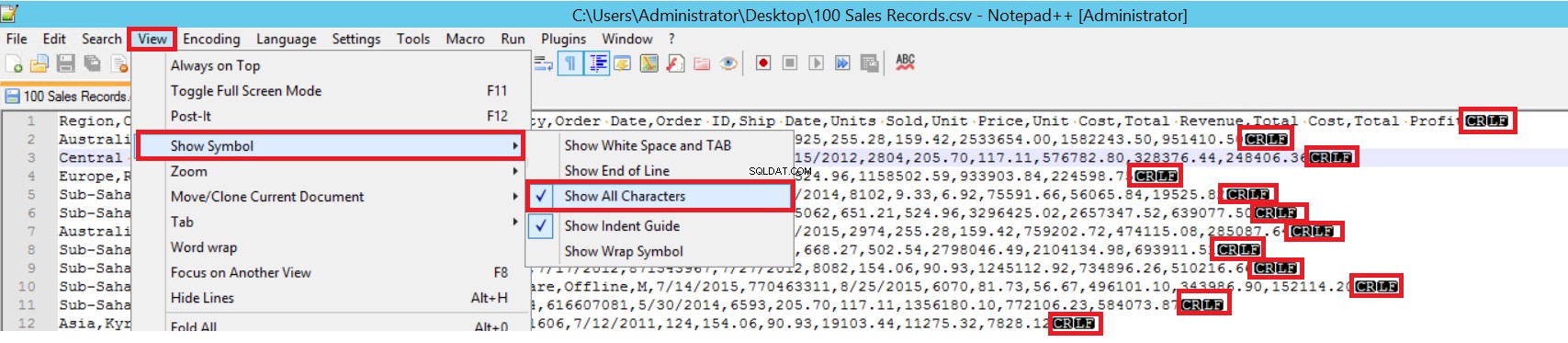
CR =Carriage Return og LF =Line Feed. De bruges til at markere et linjeskift i en tekstfil. Indikatoren er "\n" i masseindsættelseserklæringen.
En anden måde at importere en CSV-fil til en tabel med masseindsættelse er ved at bruge parameteren FORMAT. Bemærk, at denne parameter kun er tilgængelig i SQL Server 2017 og nyere versioner.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Det var det enkleste scenarie, hvor destinationstabellen og CSV-filen har lige mange kolonner. Men i tilfældet, hvor destinationstabellen har flere kolonner, er CSV-filen typisk. Lad os overveje det.
Vi tilføjer en primær nøgle til salgstabellen for at bryde lighedskolonnetilknytningerne. Vi opretter salgstabellen med en primær nøgle og importerer CSV-filen gennem kommandoen bulk insert.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Men det giver en fejl:
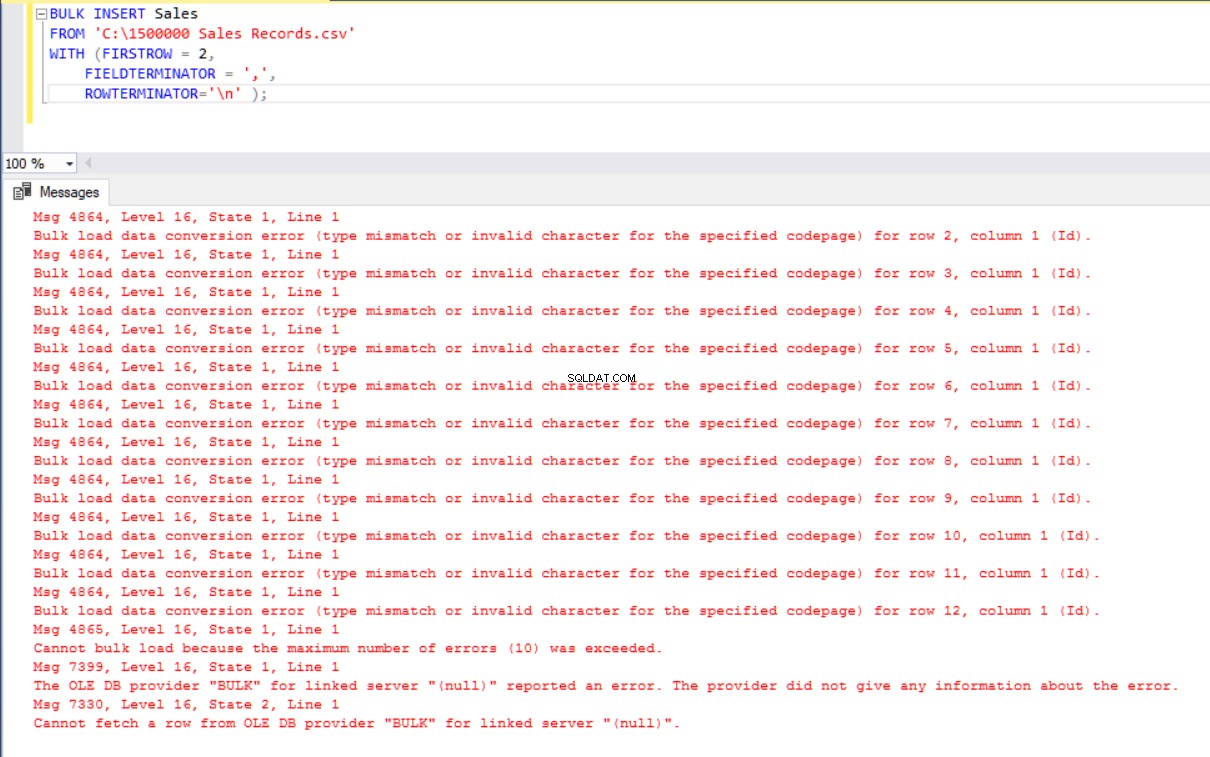
For at overvinde fejlen opretter vi en visning af salgstabellen med tilknytning af kolonner til CSV-filen. Derefter importerer vi CSV-dataene over denne visning til salgstabellen:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Adskil og indlæs en stor CSV-fil i en lille batchstørrelse
SQL Server opretter en lås til destinationstabellen under masseindsættelsesoperationen. Som standard, hvis du ikke indstiller parameteren BATCHSIZE, åbner SQL Server en transaktion og indsætter hele CSV-data i den. Med denne parameter deler SQL Server CSV-dataene i henhold til parameterværdien.
Lad os opdele hele CSV-dataene i flere sæt med hver 300.000 rækker.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Dataene vil blive importeret fem gange i dele.
- Hvis din bulk insert-sætning ikke inkluderer BATCHSIZE-parameteren, vil der opstå en fejl, og SQL-serveren vil rulle hele bulk-indsættelsesprocessen tilbage.
- Med denne parameter indstillet til bulk insert-sætning, ruller SQL Server kun den del tilbage, hvor fejlen opstod.
Der er ingen optimal eller bedste værdi for denne parameter, fordi dens værdi kan ændre sig i henhold til dine databasesystemkrav.
Indstil adfærd i tilfælde af fejl
Hvis der opstår en fejl i nogle massekopieringsscenarier, kan vi enten annullere massekopieringsprocessen eller fortsætte den. Parameteren MAXERRORS giver os mulighed for at angive det maksimale antal fejl. Hvis masseindsættelsesprocessen når denne maksimale fejlværdi, annullerer den masseimporten og ruller tilbage. Standardværdien for denne parameter er 10.
For eksempel har vi beskadigede datatyper i 3 rækker af CSV-filen. MAXERRORS-parameteren er sat til 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Hele masseindsættelsesoperationen vil blive annulleret, fordi der er flere fejl end parameterværdien MAXERRORS.
Hvis vi ændrer parameteren MAXERRORS til 4, vil bulk insert-sætningen springe over disse rækker med fejl og indsætte korrekte datastrukturerede rækker. Masseindsættelsesprocessen vil være afsluttet.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Hvis vi bruger både BATCHSIZE og MAXERRORS samtidigt, vil massekopieringsprocessen ikke annullere hele indsættelsesoperationen. Det vil kun annullere den delte del.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Tag et kig på billedet nedenfor, der viser scriptudførelsesresultatet:
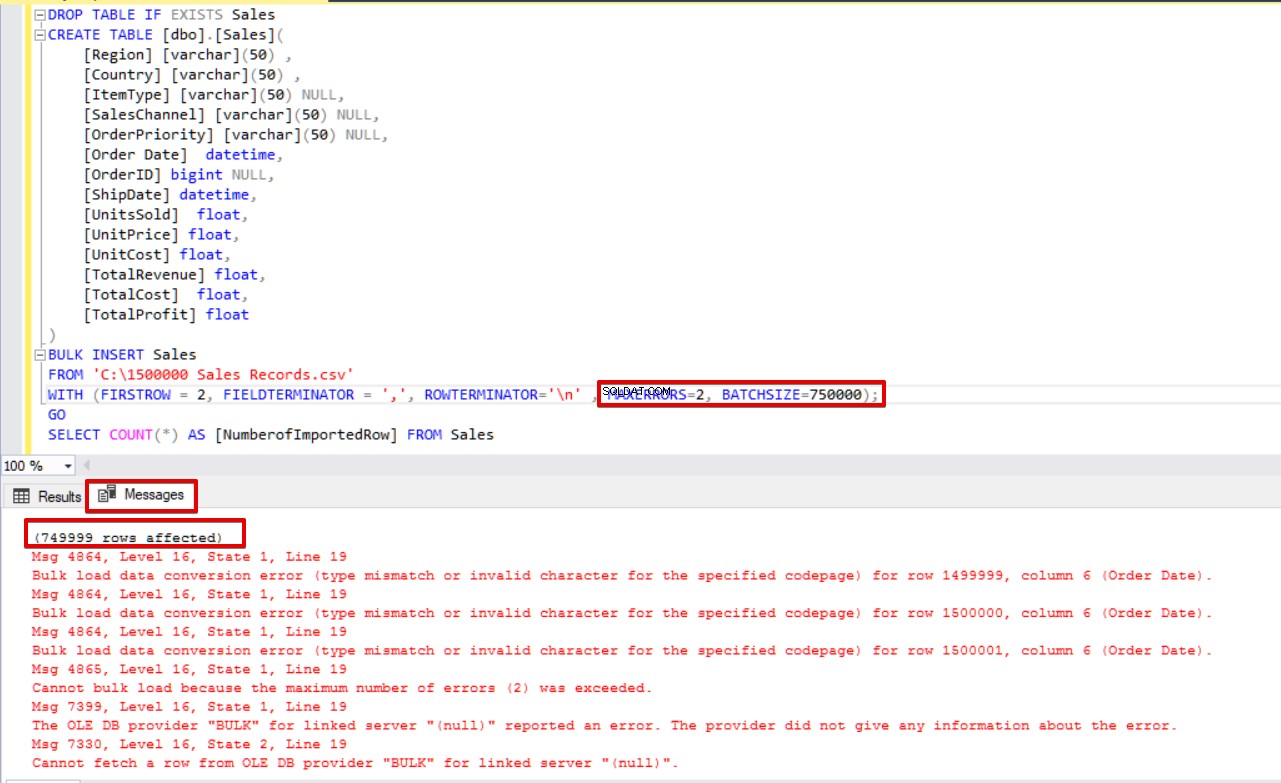
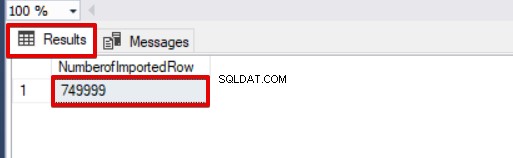
Andre muligheder for masseindsættelsesprocessen
FIRE_TRIGGERS – aktiver triggere i destinationstabellen under masseindsættelsesoperationen
Som standard udløses de indsættelsesudløsere, der er angivet i måltabellen, ikke under masseindsættelsesprocessen. Alligevel vil vi måske i nogle situationer aktivere dem.
Løsningen bruger muligheden FIRE_TRIGGERS i bulk-indsæt-sætninger. Men vær opmærksom på, at det kan påvirke og reducere bulk-indsatsens ydelse. Det er fordi trigger/triggere kan lave separate operationer i databasen.
Til at begynde med indstiller vi ikke FIRE_TRIGGERS-parameteren, og masseindsættelsesprocessen vil ikke udløse indsættelsesudløseren. Se nedenstående T-SQL-script:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogNår dette script udføres, udløses indsættelsesudløseren ikke, fordi indstillingen FIRE_TRIGGERS ikke er indstillet.
Lad os nu tilføje FIRE_TRIGGERS-indstillingen til masseindsættelseserklæringen:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 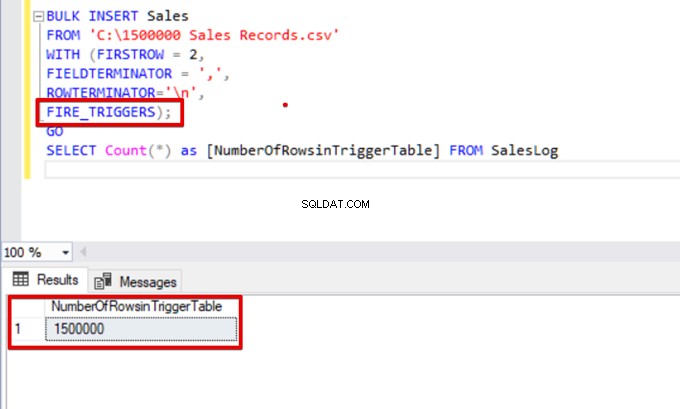
CHECK_CONSTRAINTS – aktiver en kontrolbegrænsning under bulkinsert-operationen
Check-begrænsninger giver os mulighed for at håndhæve dataintegritet i SQL Server-tabeller. Formålet med begrænsningen er at kontrollere indsatte, opdaterede eller slettede værdier i henhold til deres syntaksregulering. Som f.eks. NOT NULL-begrænsningen sørger for, at NULL-værdien ikke kan ændre en specificeret kolonne.
Her fokuserer vi på begrænsninger og bulkinsert-interaktioner. Som standard ignoreres alle kontrol- og fremmednøglebegrænsninger under masseindsættelsesprocessen. Men der er nogle undtagelser.
Ifølge Microsoft håndhævesUNIKKE og PRIMÆRE NØGLE-begrænsninger altid. Ved import til en tegnkolonne, som NOT NULL-begrænsningen er defineret for, indsætter BULK INSERT en tom streng, når der ikke er nogen værdi i tekstfilen."
I det følgende T-SQL-script tilføjer vi en kontrolbegrænsning til kolonnen OrderDate, som kontrollerer ordredatoen, der er større end 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Som et resultat springer masseindsættelsesprocessen kontrolbegrænsningskontrollen over. SQL Server angiver dog kontrolbegrænsning som ikke-tillid:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'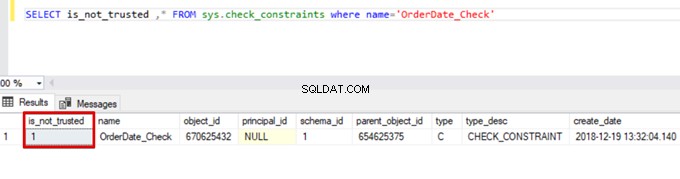
Denne værdi angiver, at nogen har indsat eller opdateret nogle data til denne kolonne ved at springe kontrolbetingelsen over. Samtidig kan denne kolonne indeholde inkonsistente data vedrørende denne begrænsning.
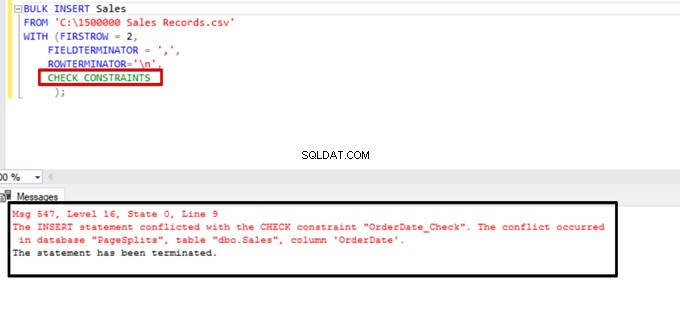
Prøv at udføre bulk insert-sætningen med CHECK_CONSTRAINTS-indstillingen. Resultatet er ligetil:check constraint returnerer en fejl på grund af ukorrekte data.
TABLOCK – øg ydeevnen i flere bulk-indsæt i én destinationstabel
Det primære formål med låsemekanismen i SQL Server er at beskytte og sikre dataintegritet. I hovedkonceptet i SQL Server-låseartiklen kan du finde detaljer om låsemekanismen.
Vi vil fokusere på bulk-indsættelsesproceslåsedetaljer.
Hvis du kører bulk insert-sætningen uden TABLELOCK-indstillingen, får den låsen af rækker eller tabeller i henhold til låsehierarki. Men i nogle tilfælde vil vi måske udføre flere bulk-indsættelsesprocesser mod én destinationstabel og dermed reducere driftstiden.
Først udfører vi to bulk insert-sætninger samtidigt og analyserer låsemekanismens opførsel. Åbn to forespørgselsvinduer i SQL Server Management Studio, og kør følgende bulk insert-sætninger samtidigt.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
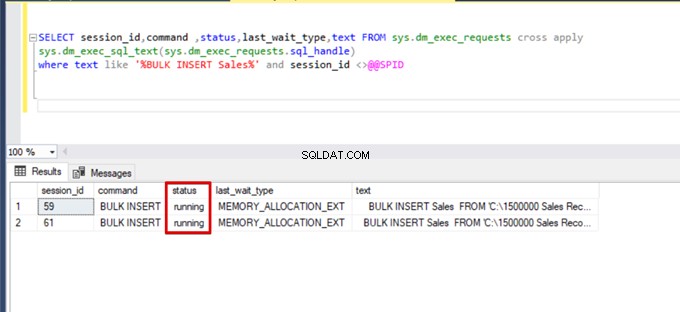
);Udfør følgende DMV (Dynamic Management View)-forespørgsel – det hjælper med at overvåge status for masseindsættelsesprocessen:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID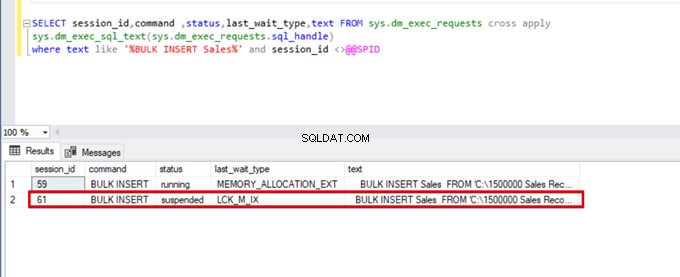
Som du kan se på ovenstående billede, session 61, er bulkinsert-processtatus suspenderet på grund af låsning. Hvis vi bekræfter problemet, låser session 59 destinationstabellen for masseindsættelse. Derefter venter session 61 på at frigive denne lås for at fortsætte masseindsættelsesprocessen.
Nu tilføjer vi TABLOCK-indstillingen til bulk-indsæt-sætningerne og udfører forespørgslerne.
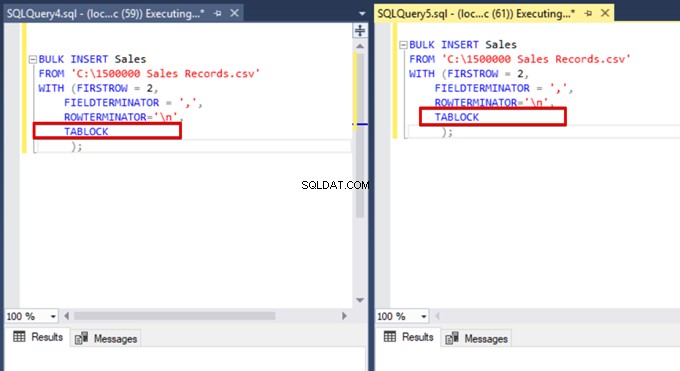
Når vi udfører DMV-overvågningsforespørgslen igen, kan vi ikke se nogen suspenderet masseindsættelsesproces, fordi SQL Server bruger en bestemt låsetype kaldet bulk update lock (BU). Denne låsetype tillader behandling af flere bulk-indsatsoperationer mod samme tabel samtidigt. Denne mulighed reducerer også den samlede tid for masseindsættelsesprocessen.
Når vi udfører følgende forespørgsel under masseindsættelsesprocessen, kan vi overvåge låsedetaljerne og låsetyperne:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()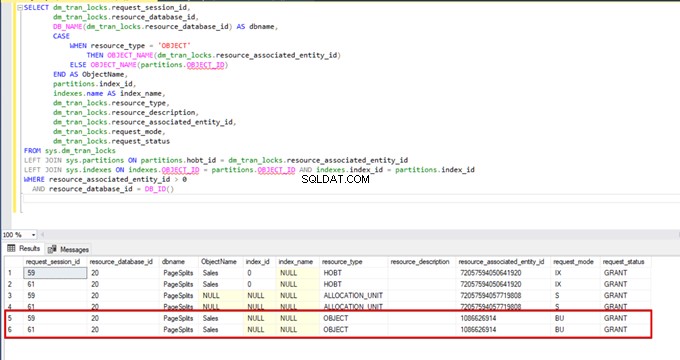
Konklusion
Den aktuelle artikel undersøgte alle detaljer om bulk insert-operation i SQL Server. Vi nævnte især kommandoen BULK INSERT og dens indstillinger og muligheder. Vi analyserede også forskellige scenarier tæt på virkelige problemer.
Nyttigt værktøj:
dbForge Data Pump – et SSMS-tilføjelsesprogram til at fylde SQL-databaser med eksterne kildedata og migrere data mellem systemer.