I de sidste par måneder har vi hos 2ndQuadrant arbejdet på at fusionere PostgreSQL 9.6 til Postgres-XL, hvilket viste sig at være ret udfordrende af forskellige årsager og tog mere tid end oprindeligt planlagt på grund af flere invasive upstream-ændringer. Hvis du er interesseret, så kig på det officielle lager her (se på "master"-grenen for nu).
Der er stadig en del arbejde, der skal gøres – sammenlægning af nogle få resterende bits fra upstream, rettelse af kendte fejl og regressionsfejl, test osv. Hvis du overvejer at bidrage til Postgres-XL, er dette en ideel mulighed (send mig en e-mail, så hjælper jeg dig med de første trin).
Men samlet set er Postgres-XL 9.6 klart et stort skridt fremad på en række vigtige områder.
Nye funktioner i Postgres-XL 9.6
Så hvilke nye funktioner får Postgres-XL fra PostgreSQL 9.6-fusionen? Jeg kunne blot henvise dig til upstream-udgivelsesbemærkningerne – de fleste af forbedringerne gælder direkte for XL 9.6, med undtagelse af dem, der er relateret til funktioner, der ikke understøttes på XL.
Den vigtigste brugersynlige forbedring i PostgreSQL 9.6 var klart parallelforespørgsel, og det gælder også for Postgres-XL 9.6.
Intra-node parallelitet
Før PostgreSQL 9.6 var Postgres-XL en af måderne at få parallelle forespørgsler på (ved at placere flere Postgres-XL noder på samme maskine). Siden PostgreSQL 9.6 er det ikke længere nødvendigt, men det betyder også, at Postgres-XL får mulighed for intra-node parallelitet.
Til sammenligning er dette, hvad Postgres-XL 9.5 tillod dig at gøre – at distribuere en forespørgsel til flere dataknudepunkter, men hver dataknude var stadig underlagt grænsen for "én backend pr. forespørgsel", ligesom almindelig PostgreSQL.
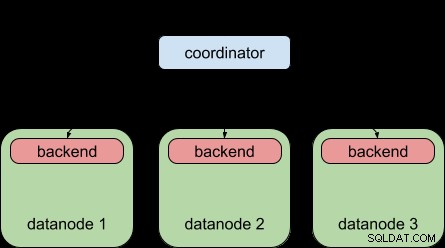
Takket være PostgreSQL 9.6 parallelle forespørgselsfunktion kan Postgres-XL 9.6 nu gøre dette:
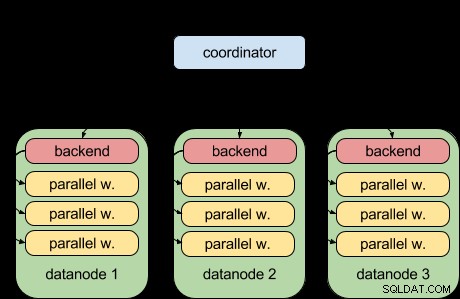
Det vil sige, at hver dataknude nu kan køre sin del af forespørgslen parallelt ved at bruge den opstrøms parallelle forespørgselsinfrastruktur. Det er fantastisk og gør Postgres-XL meget mere kraftfuldt, når det kommer til analytiske arbejdsbelastninger.
Vedligeholdelse af en gaffel
Jeg nævnte, at denne fusion viste sig at være mere udfordrende, end vi oprindeligt forventede, af en række årsager.
For det første er det generelt svært at vedligeholde gafler, især når opstrømsprojektet bevæger sig lige så hurtigt som PostgreSQL. Du skal udvikle funktioner, der er specifikke for din gaffel, hvilket er grunden til, at gafler eksisterer i første omgang. Men man vil også gerne følge med opstrøms, ellers kommer man håbløst bagud. Det er grunden til, at nogle af de eksisterende gafler stadig sidder fast på PostgreSQL 8.x og mangler alle de godbidder, der er begået siden da.
For det andet blev fusionen udført i én stor klump, ligesom alle de foregående (9.5, 9.2, …). Det vil sige, at alle upstream-commits blev slået sammen i en enkelt git merge-kommando. Det er temmelig garanteret at forårsage en masse fusionskonflikter, i det omfang koden ikke engang kompilerer, for ikke at nævne at køre regressionstests eller noget lignende.
Så den første batch af rettelser handler om at få den i en kompilerbar tilstand, den næste batch handler om at få den til faktisk at køre uden umiddelbare segfaults, og til sidst starter den "almindelige" rettelse (kør regressionstest, ret problemer, skyl og gentag) .
Disse kompleksiteter er iboende for gaffelvedligeholdelse (og en grund til, at du nok bør genoverveje at starte endnu en gaffel og i stedet bidrage direkte til enten Postgres og/eller Postgres-XL).
Men der er måder at reducere påvirkningen markant på – for eksempel planlægger vi at lave den næste fusion (med PostgreSQL 10) i mindre bidder. Det burde minimere omfanget af fusionskonflikter og give os mulighed for at løse fejlene meget hurtigere.
Tættere på PostgreSQL
Interessant nok tillod den vedtagelse af parallelisme fra opstrømssiden os også at slippe af med en masse kode fra XL-kodebasen – et godt eksempel på dette er den parallelle aggregerede kode, som nemt erstattede den XL-specifikke kode.
Et andet eksempel på en opstrømsændring, der væsentligt påvirkede XL-koden, er "pathification" for den øvre planlægger, der blev skubbet sent i 9.6-udviklingscyklussen. Dette viste sig at være en meget invasiv ændring (faktisk er en række af de åbne fejl sandsynligvis relateret til det), men i sidste ende tillod det os at forenkle planlægningskoden (i det væsentlige konstruere rigtige stier i stedet for at justere den resulterende plan).
Når jeg siger, at fusionen tillod os at forenkle XL-koden og gøre den tættere på PostgreSQL, hvad mener jeg så med det? Den enkleste måde at kvantificere ændringen på er at lave "git diff -stat" mod den matchende opstrømsgren og sammenligne tallene. For 9.5- og 9.6-grenene ser resultaterne således ud:
| version | filer ændret | tilføjelser | sletninger |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Det er klart, at 9.6-fusionen reducerer deltaet mod opstrøms betydeligt (med ~14% i alt). Hvor kommer denne forskel fra?
For det første skyldes noget af denne reduktion en ægte kodeforenkling. Et godt eksempel på dette er parallelt aggregat, som stort set er en 1:1-erstatning af den originale Postgres-XL-implementering. Så vi har lige revet det ud og brugt upstream-implementeringen i stedet for. Vi håber at finde flere sådanne steder i fremtiden og bruge upstream-implementering i stedet for at opretholde vores egen.
For det andet kommer en stor del af reduktionen fra at fjerne død kode. Ikke alene har vi reduceret nogle døde/utilgængelige stykker kode, vi har også opdaget en del kildefiler, der ikke engang var kompileret, og så videre.
Hvad er det næste?
På dette tidspunkt har vi slået ændringer sammen til b5bce6c1, som er stedet, hvor PostgreSQL 9.6 delte sig fra master. Så for at indhente PostgreSQL 9.6.2 er vi nødt til at flette de resterende ændringer i 9.6-grenen. I betragtning af at der for det meste kun skulle være fejlrettelser, burde det være et (forhåbentlig) ret simpelt arbejde sammenlignet med den fulde sammenlægning.
Selvfølgelig vil der være fejl. Faktisk er der stadig et par fejlslagne regressionstests på dette tidspunkt. Det skal rettes, før du laver en officiel udgivelse af XL 9.6. Og vi skal lave flere tests, så hvis du er interesseret i at hjælpe Postgres-XL, ville dette være yderst gavnligt.
En irritation, vi bliver ved med at høre om, er pakker eller mangel på dem. Du har måske bemærket, at de sidste tilgængelige pakker er ret gamle, og der er bare .rpm, intet andet. Vi planlægger at løse dette og begynde at tilbyde opdaterede pakker i flere varianter (f.eks. .rpm og .deb).
Vi planlægger også at lave nogle ændringer i, hvordan udviklingsprocessen er organiseret, for at gøre det nemmere at bidrage og deltage i udviklingsprocessen. Det er virkelig et separat emne, der ikke er relateret til 9.6-grenen, så jeg vil sende flere detaljer om det om et par dage.