Selvom de fleste databaseservere (især dem, der håndterer OLTP-lignende arbejdsbelastninger) i fremtiden vil bruge et flash-baseret lager, er vi ikke der endnu – flash-lager er stadig betydeligt dyrere end traditionelle harddiske, og så mange systemer bruger en blanding af SSD- og HDD-drev. Det betyder imidlertid, at vi skal beslutte, hvordan databasen skal opdeles – hvad der skal gå til spinning rust (HDD), og hvad er en god kandidat til flash-lageret, der er dyrere, men meget bedre til at håndtere tilfældige I/O.
Der er løsninger, der forsøger at håndtere dette automatisk på lagerniveau ved automatisk at bruge SSD'er som en cache, der automatisk holder den aktive del af dataene på SSD. Storage apparater / SAN'er gør dette ofte internt, der er hybride SATA/SAS-drev med stor HDD og lille SSD i en enkelt pakke, og selvfølgelig er der løsninger til at gøre dette direkte hos værten – for eksempel er der dm-cache i Linux, LVM fik også en sådan kapacitet (bygget oven på dm-cache) i 2014, og ZFS har selvfølgelig L2ARC.
Men lad os ignorere alle disse automatiske muligheder, og lad os sige, at vi har to enheder forbundet direkte til systemet - den ene er baseret på HDD'er, den anden er flash-baseret. Hvordan bør du opdele databasen for at få mest muligt ud af det dyre flash? Et almindeligt brugt mønster er at gøre dette efter objekttype, især tabeller vs. indekser. Hvilket generelt giver mening, men vi ser ofte folk placere indekser på SSD-lageret, da indekser er forbundet med tilfældig I/O. Selvom dette kan virke rimeligt, viser det sig, at dette er præcis det modsatte af, hvad du burde gøre.
Lad mig vise dig et benchmark …
Lad mig demonstrere dette på et system med både HDD-lagring (RAID10 bygget af 4x 10k SAS-drev) og en enkelt SSD-enhed (Intel S3700). Systemet har 16 GB RAM, så lad os bruge pgbench med skalaer 300 (=4,5 GB) og 3000 (=45 GB), altså en der nemt passer ind i RAM og et multiplum af RAM. Lad os derefter placere tabeller og indekser på forskellige lagersystemer (ved at bruge tablespaces) og måle ydeevnen. Databaseklyngen var rimeligt konfigureret (delte buffere, WAL-grænser osv.) med hensyn til hardwareressourcerne. WAL'en blev placeret på en separat SSD-enhed, tilsluttet en RAID-controller delt med SAS-drevene.
På det lille (4,5 GB) datasæt ser resultaterne således ud (bemærk, at y-aksen starter ved 3000 tps):
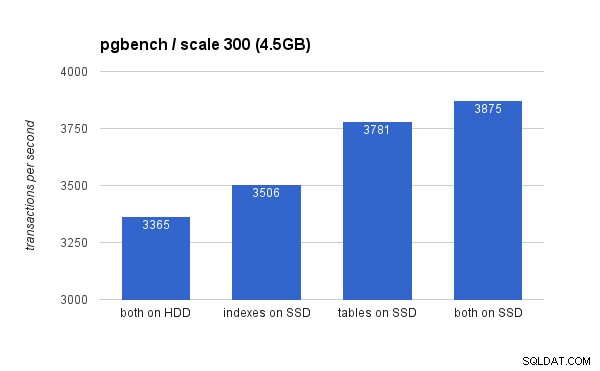
Det er klart, at placering af indekserne på SSD giver lavere fordele sammenlignet med at bruge SSD'en til tabeller. Mens datasættet nemt passer ind i RAM, skal ændringerne til sidst skrives til disken til sidst, og mens RAID-controlleren har en skrivecache, kan den ikke rigtig konkurrere med flash-lageret. Nye RAID-controllere ville nok yde en smule bedre, men det ville nye SSD-drev også.
På det store datasæt er forskellene meget mere signifikante (denne gang starter y-aksen ved 0):
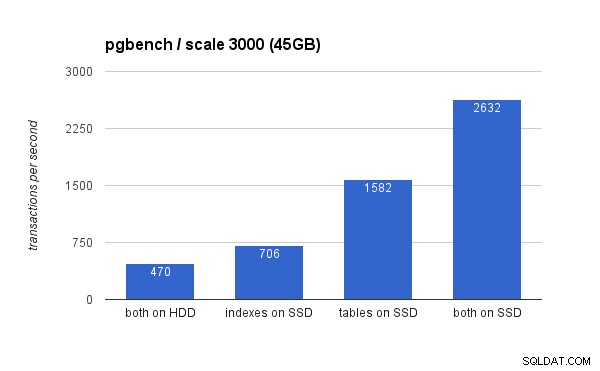
Placering af indekserne på SSD'en resulterer i en betydelig ydelsesforøgelse (næsten 50 %, hvis man tager HDD-lageret som baseline), men flytning af tabeller til SSD’en slog nemt det ved at få mere end 200 %. Selvfølgelig, hvis du placerer både tabeller og indeks på SSD'er, vil du forbedre ydeevnen yderligere - men hvis du kunne gøre det, behøver du ikke bekymre dig om de andre tilfælde.
Men hvorfor?
At få bedre ydeevne ved at placere borde på SSD'er kan virke lidt kontraintuitivt, så hvorfor opfører det sig sådan? Nå, det er sandsynligvis en kombination af flere faktorer:
- indekser er normalt meget mindre end tabeller og passer derfor lettere ind i hukommelsen
- siderne i indeksniveauer (i træet) er normalt ret varme og forbliver derfor i hukommelsen
- når der scannes og indekseres, er meget af den faktiske I/O sekventiel (især for bladsider)
Konsekvensen af dette er, at en overraskende mængde I/O mod indekser enten slet ikke sker (takket være caching) eller er sekventiel. På den anden side er indekser en god kilde til tilfældig I/O mod tabellerne.
Det er dog mere kompliceret …
Selvfølgelig var dette blot et simpelt eksempel, og konklusionerne kan være forskellige for f.eks. væsentligt forskellige arbejdsbelastninger. På samme måde, da SSD'er er dyrere, har systemer en tendens til at have mere diskplads på HDD-drev end på SSD-drev, så tabeller passer muligvis ikke på SSD'en, mens indekser ville. I disse tilfælde er en mere udførlig placering nødvendig – for eksempel i betragtning af ikke kun objektets type, men også hvor ofte det bruges (og kun flytter de meget brugte tabeller til SSD'er), eller endda undergrupper af tabeller (f.eks. ved gradvist at flytte gamle) data fra SSD til HDD).