I det forrige blogindlæg forklarede jeg kort, hvordan vi fik publiceret præstationstallene i den pglogiske meddelelse. I dette blogindlæg vil jeg gerne diskutere ydeevnegrænserne for logiske replikeringsløsninger generelt, og også hvordan de gælder for pglogical.
fysisk replikation
Lad os først se, hvordan fysisk replikering (indbygget i PostgreSQL siden version 9.0) fungerer. En noget forenklet figur med to kun to noder ser sådan ud:
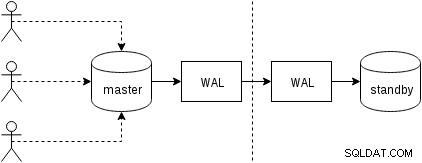
Klienter udfører forespørgsler på masternoden, ændringerne skrives til en transaktionslog (WAL) og kopieres over netværket til WAL på standby-knuden. Gendannelsen på standby-processen på standby læser derefter ændringerne fra WAL og anvender dem på datafilerne ligesom under gendannelse. Hvis standbyen er i "hot_standby"-tilstand, kan klienter udstede skrivebeskyttede forespørgsler på noden, mens dette sker.
Dette er meget effektivt, fordi der er meget lidt ekstra behandling - ændringer overføres og skrives til standby som en uigennemsigtig binær klat. Selvfølgelig er gendannelsen ikke gratis (både med hensyn til CPU og I/O), men det er svært at blive mere effektiv end dette.
De åbenlyse potentielle flaskehalse med fysisk replikering er netværksbåndbredden (overførsel af WAL fra master til standby) og også I/O på standby, som kan være mættet af gendannelsesprocessen, som ofte udsteder en masse tilfældige I/O-anmodninger ( i nogle tilfælde mere end mesteren, men lad os ikke komme ind på det).
logisk replikering
Logisk replikering er lidt mere kompliceret, da den ikke beskæftiger sig med uigennemsigtig binær WAL-strøm, men en strøm af "logiske" ændringer (forestil dig INSERT-, UPDATE- eller DELETE-udsagn, selvom det ikke er helt korrekt, da vi har at gøre med struktureret repræsentation af dataene). At have de logiske ændringer gør det muligt at udføre interessante ting som konfliktløsning, replikere kun udvalgte tabeller, til et andet skema eller mellem forskellige versioner (eller endda forskellige databaser).
Der er forskellige måder at få ændringerne på – den traditionelle tilgang er ved at bruge triggere, der registrerer ændringerne i en tabel, og lade en tilpasset proces løbende læse disse ændringer og anvende dem på standby ved at køre SQL-forespørgsler. Og alt dette er drevet af en ekstern dæmonproces (eller muligvis flere processer, der kører på begge noder), som illustreret på næste figur

Det er det, som slony eller londiste gør, og selvom det fungerede ret godt, betyder det en del overhead - det kræver for eksempel at fange dataændringerne og skrive dataene flere gange (til den originale tabel og til en "log"-tabel, og også til WAL for begge disse borde). Vi vil diskutere andre kilder til overhead senere. Mens pglogical skal nå de samme mål, opnår den dem anderledes, takket være adskillige funktioner tilføjet til de seneste PostgreSQL-versioner (således ikke tilgængelig, da de andre værktøjer blev implementeret):

Det vil sige, i stedet for at vedligeholde en separat log over ændringer, er pglogical afhængig af WAL - dette er muligt takket være en logisk afkodning tilgængelig i PostgreSQL 9.4, som gør det muligt at udtrække logiske ændringer fra WAL-log. Takket være dette behøver pglogical ikke nogen dyre triggere og kan normalt undgå at skrive data to gange på masteren (bortset fra store transaktioner, der kan spildes til disken).
Efter afkodning af hver transaktion, bliver den overført til standby, og anvendelsesprocessen anvender sine ændringer til standby-databasen. pglogical anvender ikke ændringerne ved at køre almindelige SQL-forespørgsler, men på et lavere niveau, og omgår de overhead, der er forbundet med at analysere og planlægge SQL-forespørgsler. Dette giver pglogical en betydelig fordel i forhold til de eksisterende løsninger, der alle går gennem SQL-laget (og dermed betaler for parsing og planlægning).
potentielle flaskehalse
Det er klart, at logisk replikering er modtagelig for de samme flaskehalse som fysisk replikering, dvs. det er muligt at mætte netværket, når ændringerne overføres, og I/O på standby, når de anvendes på standby. Der er også en del overhead på grund af yderligere trin, der ikke er til stede i en fysisk replikering.
Vi skal på en eller anden måde indsamle de logiske ændringer, mens fysisk replikering blot sender WAL'en som strøm af bytes. Som allerede nævnt er eksisterende løsninger normalt afhængige af triggere, der skriver ændringerne til en "log"-tabel. pglogical er i stedet afhængig af Write-ahead log (WAL) og logisk afkodning for at opnå det samme, hvilket er billigere end triggere og heller ikke behøver at skrive data to gange i de fleste tilfælde (med den ekstra bonus, at vi automatisk anvender ændringerne i commit rækkefølge).
Dermed ikke sagt, at der ikke er muligheder for yderligere forbedringer - for eksempel sker afkodningen i øjeblikket først, når transaktionen er forpligtet, så med store transaktioner kan dette øge replikationsforsinkelsen. Fysisk replikation streamer simpelthen WAL-ændringerne til den anden node og har således ikke denne begrænsning. Store transaktioner kan også spildes til disken, hvilket forårsager duplikatskrivninger, fordi upstream skal gemme dem, indtil de forpligter sig, og de kan sendes til downstream.
Fremtidigt arbejde er planlagt for at give pglogical mulighed for at begynde at streame store transaktioner, mens de stadig er i gang på upstream, hvilket reducerer latensen mellem upstream commit og downstream commit og reducerer upstream skriveforstærkning.
Efter ændringerne er overført til standby, skal anvendelsesprocessen faktisk anvende dem på en eller anden måde. Som nævnt i det foregående afsnit gjorde de eksisterende løsninger det ved at konstruere og udføre SQL-kommandoer, mens pglogical helt omgår SQL-laget og den tilhørende overhead.
Alligevel gør det ikke applikationen helt gratis, da den stadig skal udføre ting som primære nøgleopslag, opdatere indekser, udføre triggere og udføre forskellige andre kontroller. Men det er væsentligt billigere end den SQL-baserede tilgang. På en måde fungerer det meget som COPY og er især hurtigt på simple borde uden triggere, fremmednøgler osv.
I alle de logiske replikeringsløsninger sker hvert af disse trin (afkodning og anvendelse) i en enkelt proces, så der er ret begrænset CPU-tid. Dette er sandsynligvis den mest presserende flaskehals i alle de eksisterende løsninger, fordi du måske har en ret kraftig maskine med titusvis eller endda hundredvis af klienter, der kører forespørgsler parallelt, men alt det skal gennemgå en enkelt proces, der afkoder disse ændringer (på master) og én proces, der anvender disse ændringer (på standby).
Begrænsningen "en enkelt proces" kan lempes noget ved at bruge separate databaser, da hver database håndteres af en separat proces. Når det kommer til en enkelt database, er fremtidigt arbejde planlagt til at parallelisere anvendelse via en pulje af baggrundsarbejdere for at afhjælpe denne flaskehals.