At have et testmiljø er et must i alle virksomheder. Det kan være nødvendigt for at teste ændringer eller nye udgivelser af applikationen, eller endda for at teste din eksisterende applikation med en ny PostgreSQL-version. Den svære del af dette er for det første, hvordan man implementerer et testmiljø, der ligner produktionsmiljøet så meget som muligt, og hvordan man vedligeholder dette miljø uden at genskabe alt fra bunden.
I denne blog vil vi se, hvordan man implementerer et testmiljø på forskellige måder ved hjælp af ClusterControl, som vil hjælpe dig med at automatisere processen og undgå manuelle tidskrævende opgaver.
Klynge-til-klynge-replikering
Siden ClusterControl 1.7.4 er der en funktion kaldet Cluster-to-Cluster Replication. Det giver dig mulighed for at have en replikering kørende mellem to autonome klynger.
Vi vil tage et kig på, hvordan man bruger denne funktion til en eksisterende PostgreSQL-klynge. Til denne opgave antager vi, at du har ClusterControl installeret, og at den primære klynge blev implementeret ved hjælp af den.
Oprettelse af en klynge-til-klynge-replikering
For at oprette en ny klynge-til-klynge-replikering fra ClusterControl-brugergrænsefladen, skal du gå til ClusterControl -> Vælg PostgreSQL-klynge -> Klyngehandlinger -> Opret slaveklynge.
Slaveklyngen vil blive oprettet ved at streame data fra den nuværende primære klynge.
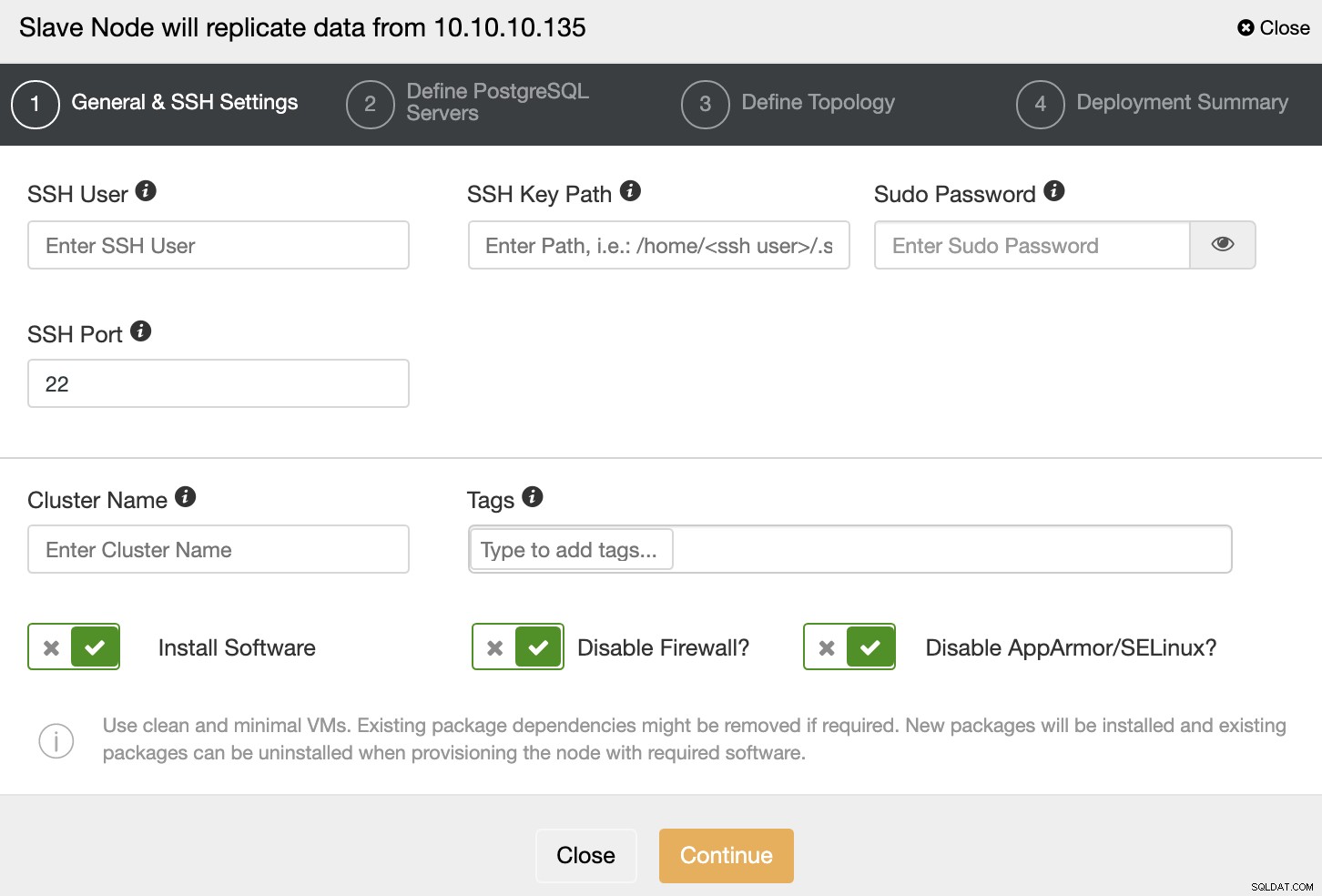
Du skal angive SSH-legitimationsoplysninger og -port, et navn til din slaveklynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
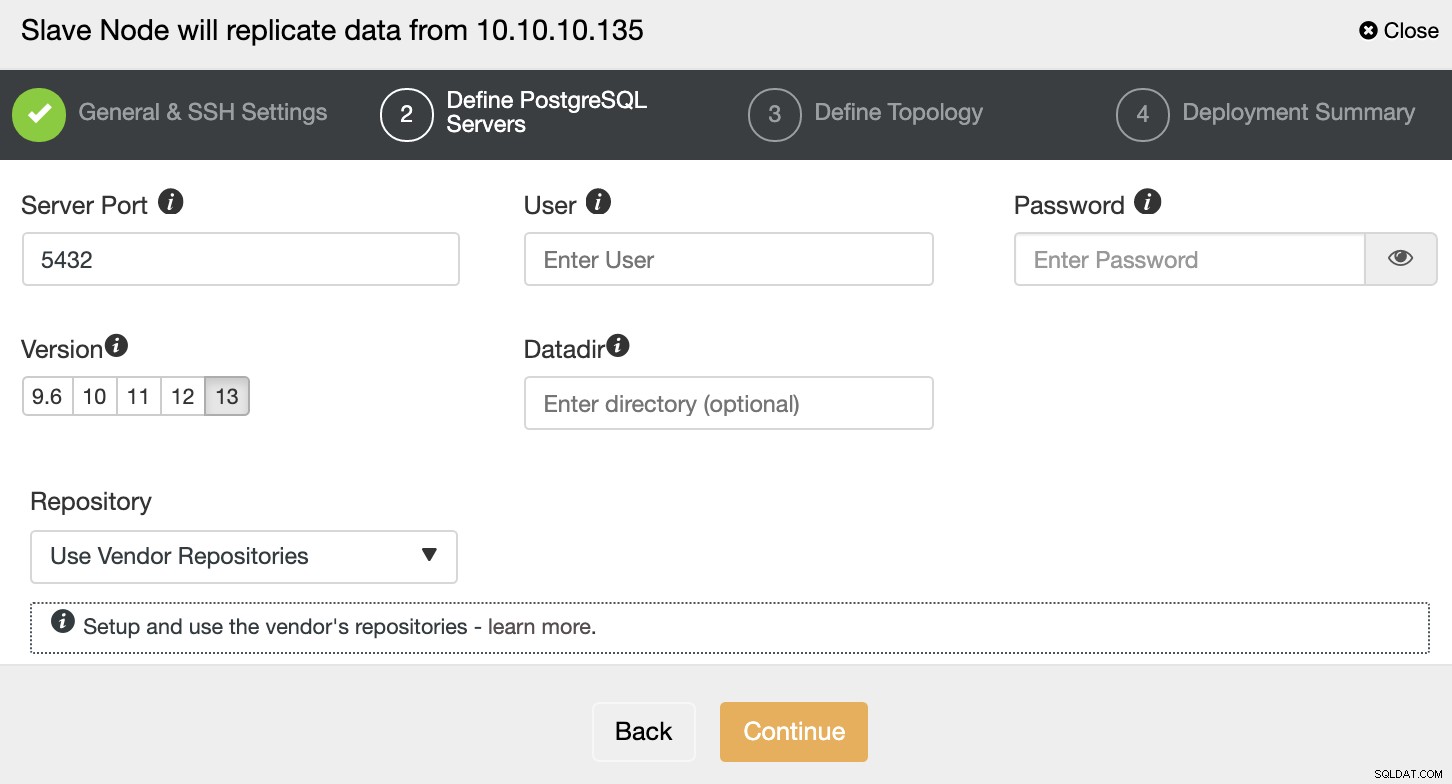
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaseversionen, datadir, port og administratorlegitimationsoplysninger. Da det vil bruge streamingreplikering, skal du sørge for at bruge den samme databaseversion, og legitimationsoplysningerne skal være de samme, som bruges af den primære klynge.
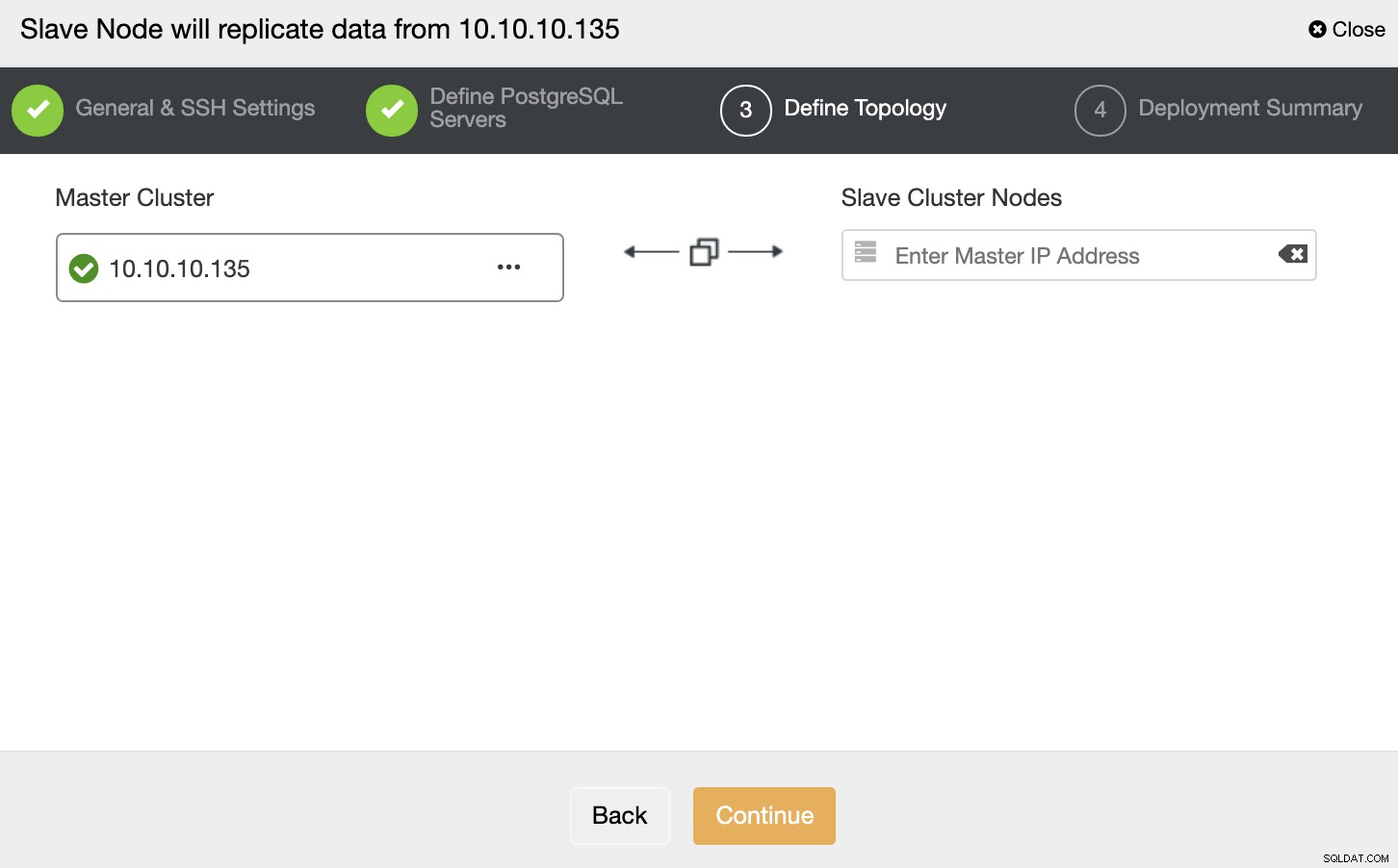
I dette trin skal du tilføje serveren til den nye slaveklynge. Til denne opgave kan du indtaste både IP-adresse eller værtsnavn for databasenoden.
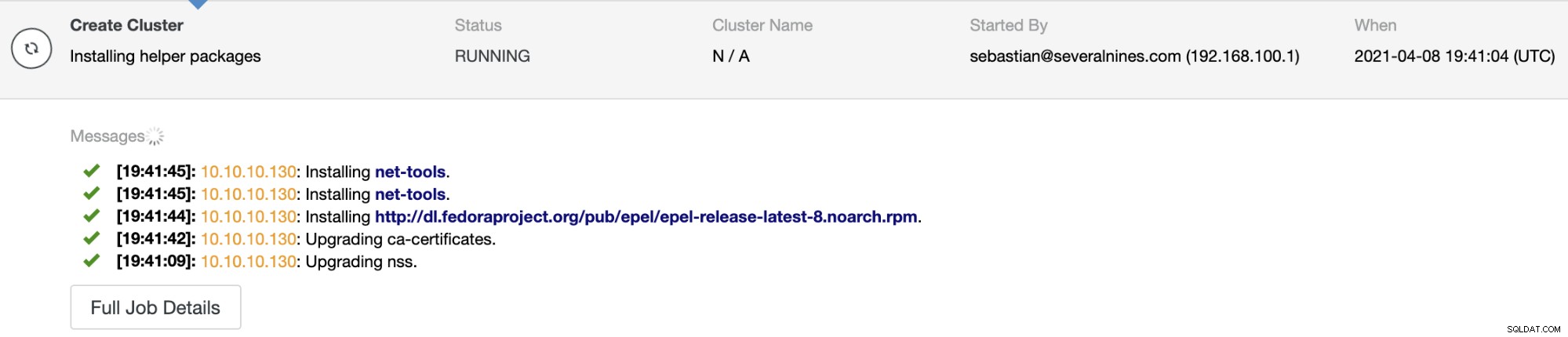
Du kan overvåge jobstatus i ClusterControl-aktivitetsmonitoren. Når opgaven er færdig, kan du se klyngen på hovedskærmen til ClusterControl.
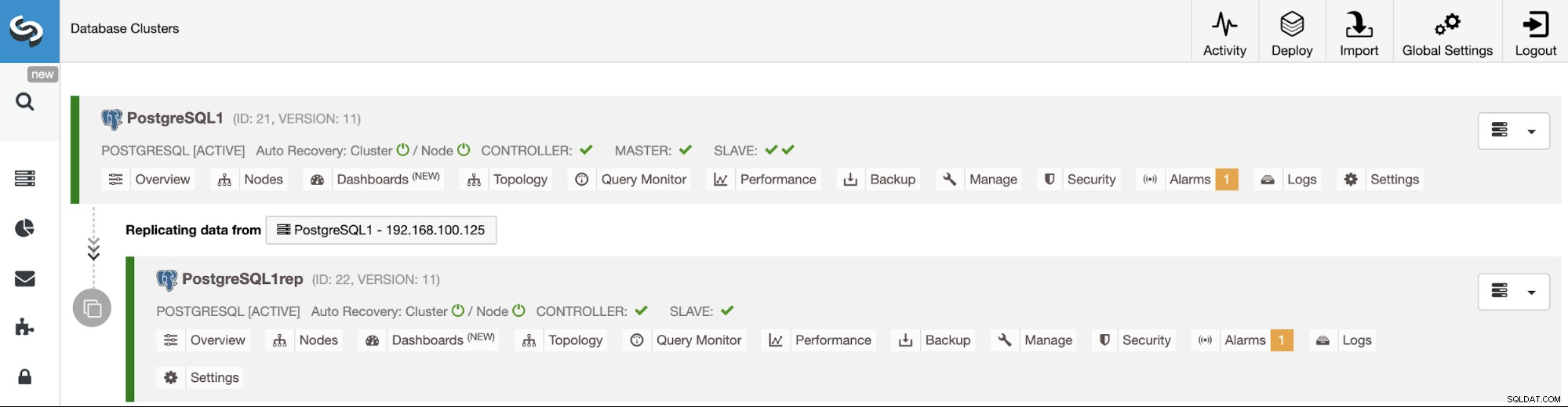
ClusterControl CLI
ClusterControl CLI, også kendt som s9s, er et kommandolinjeværktøj introduceret i ClusterControl version 1.4.1 til at interagere, kontrollere og administrere databaseklynger ved hjælp af ClusterControl-systemet. ClusterControl CLI åbner en ny dør til klyngeautomatisering, hvor du nemt kan integrere den med eksisterende implementeringsautomatiseringsværktøjer som Ansible, Puppet, Chef osv. Du kan også bruge dette ClusterControl-værktøj til at oprette en slaveklynge. Lad os se et eksempel:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=13 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=14 --logLad os nu se den brugte parameter mere detaljeret:
-
Klynge:At liste og manipulere klynger.
-
Opret:Opret og installer en ny klynge.
-
Klyngenavn:Navnet på den nye slaveklynge.
-
Klyngetype:Den type klynge, der skal installeres.
-
Udbyder-version:Softwareversionen.
-
Noder:Liste over de nye noder i slaveklyngen.
-
Os-bruger:Brugernavnet til SSH-kommandoerne.
-
Os-key-file:Nøglefilen, der skal bruges til SSH-forbindelse.
-
Db-admin:Databaseadministratorens brugernavn.
-
Db-admin-passwd:Adgangskoden til databaseadministratoren.
-
Remote-cluster-id:Master Cluster ID for Cluster-to-Cluster-replikeringen.
-
Log:Vent og overvåg jobmeddelelser.
Administration af klynge-til-klynge-replikering
Nu har du din klynge-til-klynge-replikering oppe at køre, og der er forskellige handlinger at udføre på denne topologi ved hjælp af ClusterControl fra både brugergrænseflade og CLI.
Genopbygning af en slaveklynge
For at genopbygge en slaveklynge skal du gå til ClusterControl -> Vælg slaveklynge -> Noder -> Vælg noden -> Nodehandlinger -> Genopbyg replikeringsslave.
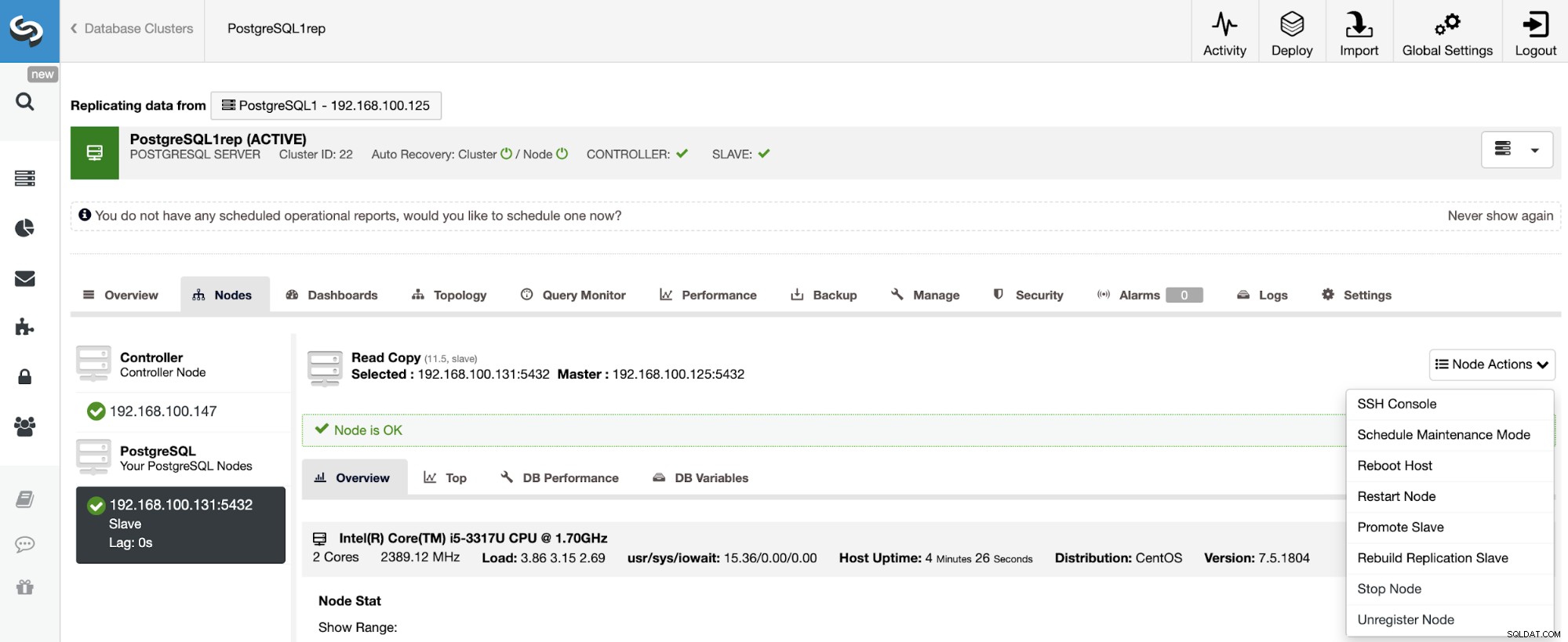
ClusterControl udfører følgende trin:
-
Stop PostgreSQL Server
-
Fjern indhold fra dets datadir
-
Stream en sikkerhedskopi fra masteren til slaven ved hjælp af pg_basebackup
-
Start slaven
Du kan også genopbygge en slaveklynge ved hjælp af følgende kommando fra ClusterControl-serveren:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=15 --remote-cluster-id=14 --logParametrene er:
-
Replikering:Til at overvåge og kontrollere datareplikering.
-
Stage:Fase/genopbygge en replikeringsslave.
-
Master:Replikeringsmasteren i masterklyngen.
-
Slave:Replikationsslaven i slaveklyngen.
-
Cluster-id:The Slave Cluster ID.
-
Remote-cluster-id:Master Cluster ID.
-
Log:Vent og overvåg jobmeddelelser.
Opret klynge fra sikkerhedskopi
En anden måde at skabe et testmiljø på er ved at oprette en ny klynge fra en sikkerhedskopi af din primære klynge. For dette skal du gå til ClusterControl -> Vælg din PostgreSQL-klynge -> Backup. Vælg der den sikkerhedskopi, der skal gendannes, fra listen.
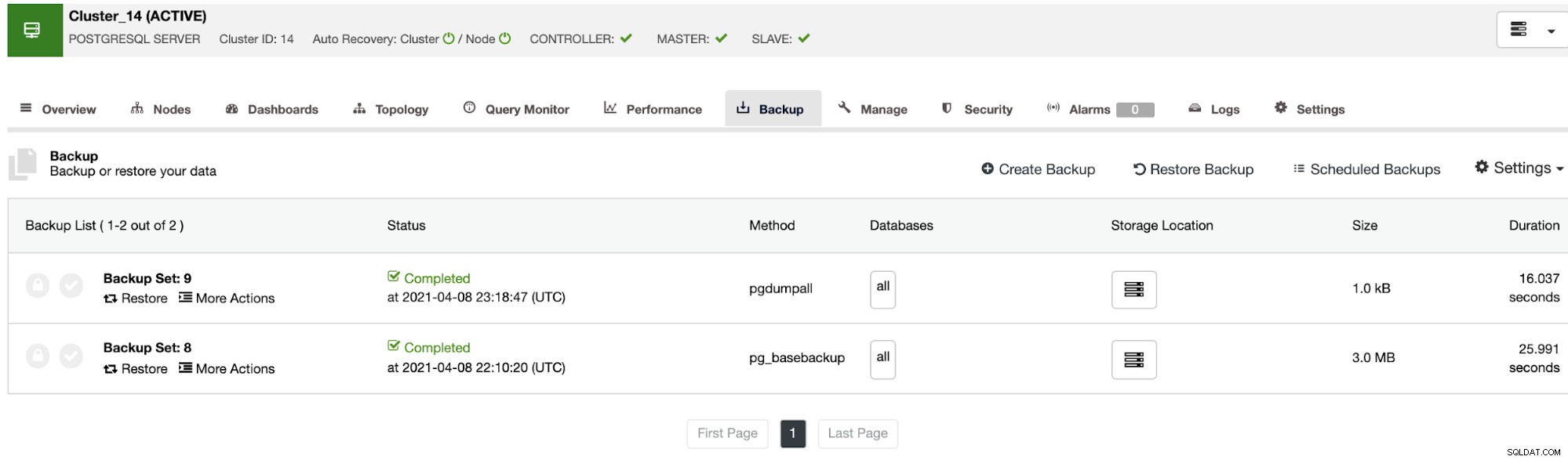
Nu kan du gendanne denne sikkerhedskopi i din nuværende database, i en separat node, eller oprette en ny klynge fra denne sikkerhedskopi.
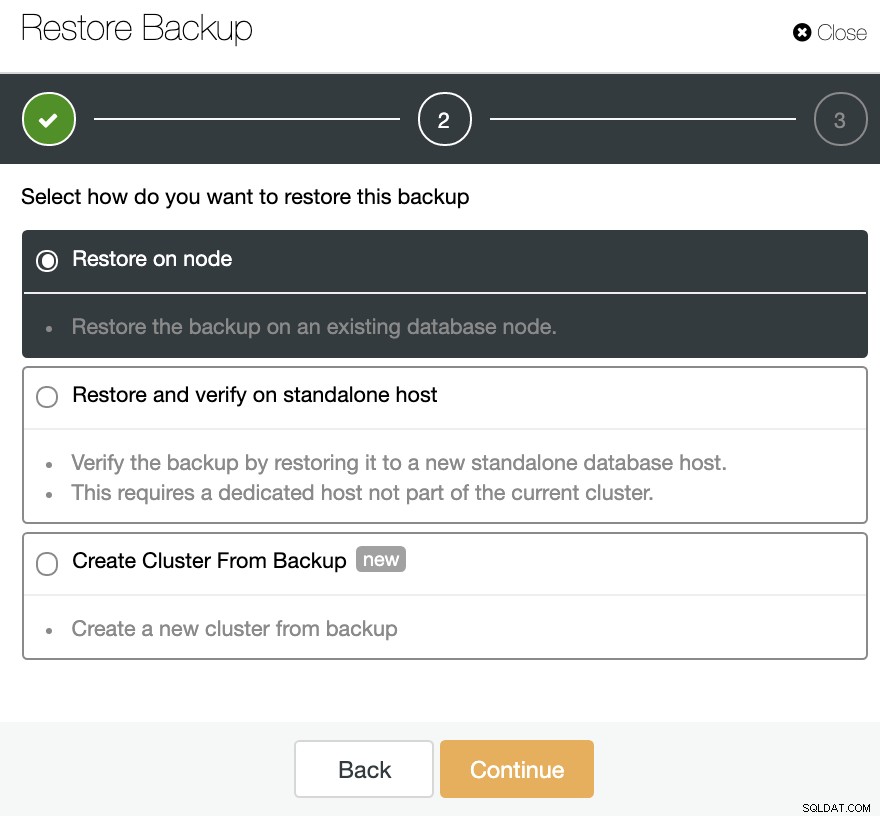
Muligheden "Opret klynge fra sikkerhedskopi" vil oprette en ny PostgreSQL-klynge fra den valgte sikkerhedskopi.
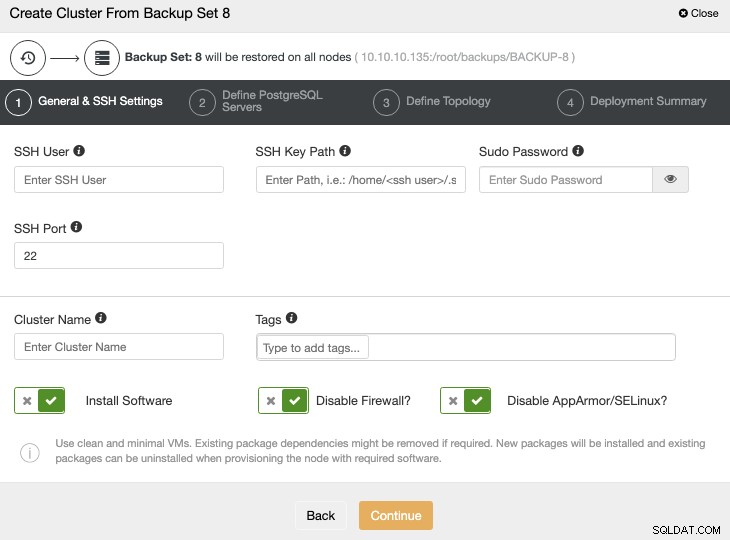
Du skal tilføje OS- og databaselegitimationsoplysningerne og oplysningerne for at implementere den nye klynge. Når dette job er færdigt, vil du se den nye klynge i ClusterControl UI.

Gendan sikkerhedskopi på Standalone Host
I samme Sikkerhedskopieringssektion kan du vælge muligheden "Gendan og verificere på selvstændig vært" for at gendanne en sikkerhedskopi i en separat node.
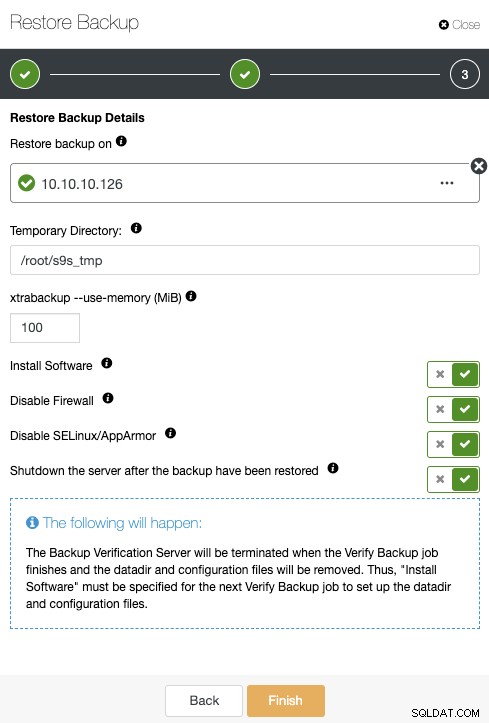
Her kan du angive, om du vil have ClusterControl til at installere softwaren i den nye node, og deaktivere firewallen eller AppArmor/SELinux (afhængigt af OS). Du kan holde noden oppe og køre, eller ClusterControl kan lukke databasetjenesten ned indtil næste gendannelsesjob. Når den er færdig, vil du se den gendannede/verificerede sikkerhedskopi på backuplisten markeret med et flueben.
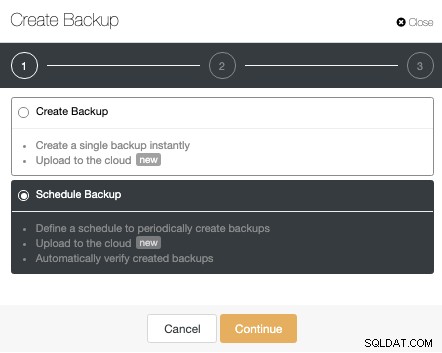
Hvis du ikke ønsker at udføre denne opgave manuelt, kan du planlægge denne proces ved hjælp af funktionen Bekræft sikkerhedskopiering for at gentage dette job med jævne mellemrum i et sikkerhedskopieringsjob.
Automatisk ClusterControl-sikkerhedskopibekræftelse
I ClusterControl -> Vælg din PostgreSQL-klynge -> Sikkerhedskopiering -> Opret sikkerhedskopi.
Den automatiske bekræftelse af sikkerhedskopiering er tilgængelig for de planlagte sikkerhedskopier. Når du planlægger en sikkerhedskopiering, skal du ud over at vælge de almindelige muligheder som metode eller lagring også angive tidsplan/hyppighed.
Ved brug af ClusterControl kan du vælge forskellige sikkerhedskopieringsmetoder, afhængigt af databaseteknologien, og i samme afsnit kan du vælge den server, som du vil tage backup fra, hvor du vil gemme sikkerhedskopien , og hvis du vil uploade sikkerhedskopien til skyen (AWS, Azure eller Google Cloud). Du kan også komprimere og kryptere din sikkerhedskopi og angive opbevaringsperioden.
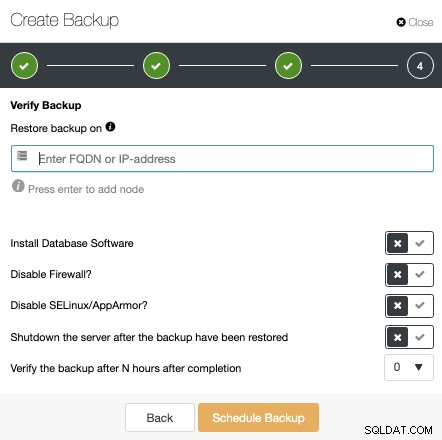
For at bruge funktionen Bekræft sikkerhedskopiering skal du bruge en dedikeret vært (eller VM), der ikke er en del af klyngen. ClusterControl installerer softwaren og gendanne sikkerhedskopien i denne vært, hver gang jobbet kører.
Efter gendannelse kan du se bekræftelsesikonet i ClusterControl Backup sektionen, det samme som du vil have ved at udføre verifikationen på den manuelle ClusterControl måde, med den forskel at du ikke behøver at bekymre dig om restaureringsopgaven. ClusterControl vil gendanne sikkerhedskopien hver gang automatisk.
Konklusion
Det kan være en tidskrævende opgave at implementere et testmiljø hver gang du har brug for det, og det er svært at holde dette opdateret. Resultatet af dette er nogle gange, at virksomheder ikke tester nye udgivelser, eller at testen ikke er korrekt, for eksempel ved at bruge et andet miljø end produktionsmiljøet.
Som du kunne se, giver ClusterControl dig mulighed for at implementere det samme miljø, som du bruger i produktionen med blot et par klik, eller endda automatisere processen for at undgå enhver manuel opgave.