Selv om der er forskellige måder at gendanne din PostgreSQL-database på, er en af de mest bekvemme metoder til at gendanne dine data fra en logisk sikkerhedskopi. Logiske sikkerhedskopier spiller en væsentlig rolle for Disaster and Recovery Planning (DRP). Logiske sikkerhedskopier er sikkerhedskopier taget, for eksempel ved hjælp af pg_dump eller pg_dumpall, som genererer SQL-sætninger for at få alle tabeldata, der er skrevet til en binær fil.
Det anbefales også at køre periodiske logiske sikkerhedskopier, hvis dine fysiske sikkerhedskopier fejler eller er utilgængelige. For PostgreSQL kan gendannelse være problematisk, hvis du er usikker på, hvilke værktøjer du skal bruge. Sikkerhedskopieringsværktøjet pg_dump er almindeligvis parret med gendannelsesværktøjet pg_restore.
pg_dump og pg_restore fungerer sammen, hvis en katastrofe opstår, og du skal gendanne dine data. Selvom de tjener det primære formål med dump og gendannelse, kræver det, at du udfører nogle ekstra opgaver, når du skal gendanne din klynge og lave en failover (hvis din aktive primære eller master dør på grund af hardwarefejl eller VM-systemkorruption). Du ender med at finde og bruge tredjepartsværktøjer, som kan håndtere failover eller automatisk klyngendannelse.
I denne blog tager vi et kig på, hvordan pg_restore fungerer, og sammenligner det med, hvordan ClusterControl håndterer sikkerhedskopiering og gendannelse af dine data i tilfælde af en katastrofe.
Mekanismer for pg_restore
pg_restore er nyttigt, når du opnår følgende opgaver:
- parret med pg_dump til generering af SQL-genererede filer, der indeholder data, adgangsroller, database- og tabeldefinitioner
- gendan en PostgreSQL-database fra et arkiv oprettet af pg_dump i et af de ikke-almindelige tekstformater.
- Den vil udstede de nødvendige kommandoer for at rekonstruere databasen til den tilstand, den var i på det tidspunkt, den blev gemt.
- har evnen til at være selektiv eller endda til at omarrangere elementerne, før de gendannes baseret på arkivfilen
- Arkivfilerne er designet til at være bærbare på tværs af arkitekturer.
- pg_restore kan fungere i to tilstande.
- Hvis et databasenavn er angivet, forbinder pg_restore til denne database og gendanner arkivindhold direkte i databasen.
- eller et script, der indeholder de SQL-kommandoer, der er nødvendige for at genopbygge databasen, oprettes og skrives til en fil eller standardoutput. Dets script-output svarer til formatet genereret af pg_dump
- Nogle af de muligheder, der styrer outputtet, er derfor analoge med pg_dump-indstillinger.
Når du har gendannet dataene, er det bedst og tilrådeligt at køre ANALYSE på hver gendannet tabel, så optimeringsværktøjet har nyttige statistikker. Selvom den får READ LOCK, skal du muligvis køre denne under lav trafik eller under din vedligeholdelsesperiode.
Fordele ved pg_restore
pg_dump og pg_restore i tandem har funktioner, som er praktiske for en DBA at bruge.
- pg_dump og pg_restore har mulighed for at køre parallelt ved at angive -j-indstillingen. Brug af -j/--jobs
giver dig mulighed for at specificere, hvor mange kørende job parallelt kan køre, specielt til indlæsning af data, oprettelse af indekser eller oprettelse af begrænsninger ved hjælp af flere samtidige job. - Den er rolig og praktisk at bruge, du kan selektivt dumpe eller indlæse specifik database eller tabeller
- Det tillader og giver en brugerfleksibilitet med hensyn til, hvilken database, skema eller omorganisering af procedurerne, der skal udføres baseret på listen. Du kan endda generere og indlæse SQL-sekvensen løst som at forhindre acls eller privilegier i overensstemmelse med dine behov. Der er masser af muligheder, der passer til dine behov.
- Det giver dig mulighed for at generere SQL-filer ligesom pg_dump fra et arkiv. Dette er meget praktisk, hvis du vil indlæse til en anden database eller vært for at klargøre et separat miljø.
- Det er let at forstå baseret på den genererede sekvens af SQL-procedurer.
- Det er en praktisk måde at indlæse data i et replikeringsmiljø. Du behøver ikke at genskabe din replika, da sætningerne er SQL, som blev replikeret ned til standby- og gendannelsesnoder.
Begrænsninger af pg_restore
For logiske sikkerhedskopier er de åbenlyse begrænsninger ved pg_restore sammen med pg_dump ydeevnen og hastigheden ved brug af værktøjerne. Det kan være praktisk, når du vil klargøre et test- eller udviklingsdatabasemiljø og indlæse dine data, men det er ikke anvendeligt, når dit datasæt er enormt. PostgreSQL skal dumpe dine data én efter én eller udføre og anvende dine data sekventielt af databasemotoren. Selvom du kan gøre dette løst fleksibelt til at fremskynde som at angive -j eller bruge --single-transaction for at undgå indvirkning på din database, skal indlæsning ved hjælp af SQL stadig analyseres af motoren.
Derudover angiver PostgreSQL-dokumentationen følgende begrænsninger, med vores tilføjelser, da vi observerede disse værktøjer (pg_dump og pg_restore):
- Når du gendanner data til en allerede eksisterende tabel, og muligheden --disable-triggers bruges, udsender pg_restore kommandoer for at deaktivere triggere på brugertabeller, før dataene indsættes, og udsender derefter kommandoer for at genaktivere dem efter dataene er blevet indsat. Hvis gendannelsen stoppes i midten, kan systemkatalogerne efterlades i den forkerte tilstand.
- pg_restore kan ikke gendanne store objekter selektivt; for eksempel kun dem for en bestemt tabel. Hvis et arkiv indeholder store objekter, vil alle store objekter blive gendannet, eller ingen af dem, hvis de er udelukket via -L, -t eller andre muligheder.
- Begge værktøjer forventes at generere en enorm størrelse (filer, mappe eller tar-arkiv) især for en enorm database.
- For pg_dump, når du dumper en enkelt tabel eller som almindelig tekst, håndterer pg_dump ikke store objekter. Store objekter skal dumpes med hele databasen ved hjælp af et af de ikke-tekstarkivformater.
- Hvis du har tar-arkiver genereret af disse værktøjer, skal du være opmærksom på, at tar-arkiver er begrænset til en størrelse på mindre end 8 GB. Dette er en iboende begrænsning af tar-filformatet. Derfor kan dette format ikke bruges, hvis den tekstlige repræsentation af en tabel overstiger denne størrelse. Den samlede størrelse af et tar-arkiv og nogen af de andre outputformater er ikke begrænset, undtagen muligvis af operativsystemet.
Brug af pg_restore
At bruge pg_restore er ret praktisk og let at bruge. Da det er parret i tandem med pg_dump, fungerer begge disse værktøjer tilstrækkeligt godt, så længe måloutputtet passer til det andet. For eksempel vil følgende pg_dump ikke være nyttig til pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Dette resultat vil være en psql-kompatibel, som ser ud som følger:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres; Men dette vil mislykkes for pg_restore, da der ikke er noget almindeligt format at følge:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file header Lad os nu gå til mere nyttige vilkår for pg_restore.
pg_restore:Slip og gendan
Overvej en simpel brug af pg_restore, som du har droppet en database, f.eks.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows) Gendannelse af det med pg_restore det meget enkelt,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump -C/--create here-tilstandene, der opretter databasen, når den er stødt på i overskriften. -d postgres peger på postgres databasen, men det betyder ikke, at den vil oprette tabellerne til postgres databasen. Det kræver, at databasen skal eksistere. Hvis -C ikke er angivet, gemmes tabeller og poster i den database, der refereres til med -d-argumentet.
Gendannelse selektivt efter tabel
Gendannelse af en tabel med pg_restore er nemt og enkelt. For eksempel har du to tabeller, nemlig "b" og "d" tabeller. Lad os sige, at du kører følgende pg_dump-kommando nedenfor,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password: Hvor indholdet af denne mappe vil se ud som følger,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 .. Hvis du vil gendanne en tabel (nemlig "d" i dette eksempel),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/ Skal have,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row) pg_restore:Kopiering af databasetabeller til en anden database
Du kan endda kopiere indholdet af din eksisterende database og have det på din måldatabase. For eksempel har jeg følgende databaser,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows) Paultest-databasen er en tom database, mens vi skal kopiere, hvad der er inde i maxtest-databasen,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows) For at kopiere det, skal vi dumpe dataene fra maxtest-databasen som følger,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Indlæs eller gendan den som følger,
Nu har vi data på paultest-databasen, og tabellerne er blevet gemt i overensstemmelse hermed.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows) Generer en SQL-fil med genbestilling
Jeg har set meget brug med pg_restore, men det ser ud til, at denne funktion normalt ikke vises. Jeg fandt denne tilgang meget interessant, da den giver dig mulighed for at bestille baseret på, hvad du ikke vil inkludere og derefter generere en SQL-fil fra den rækkefølge, du vil fortsætte.
For eksempel bruger vi eksemplet pgdump_data.tar, vi har genereret tidligere, og opretter en liste. For at gøre dette skal du køre følgende kommando:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.list Dette vil generere en fil som vist nedenfor:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgres Nu, lad os omarrangere det, eller skal vi sige, at jeg har fjernet skabelsen af SEQUENCE og også skabelsen af begrænsningen. Dette vil se ud som følger,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgres For at generere filen i SQL-format skal du blot gøre følgende:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Nu vil filen /tmp/selective_data.out være en SQL-genereret fil, og denne kan læses, hvis du bruger psql, men ikke pg_restore. Det gode ved dette er, at du kan generere en SQL-fil i overensstemmelse med din skabelon, hvor data kun kan gendannes fra et eksisterende arkiv eller sikkerhedskopieres ved hjælp af pg_dump ved hjælp af pg_restore.
PostgreSQL-gendannelse med ClusterControl
ClusterControl bruger ikke pg_restore eller pg_dump som en del af dets funktionssæt. Vi bruger pg_dumpall til at generere logiske sikkerhedskopier, og desværre er outputtet ikke kompatibelt med pg_restore.
Der er flere andre måder at generere en sikkerhedskopi i PostgreSQL som vist nedenfor.
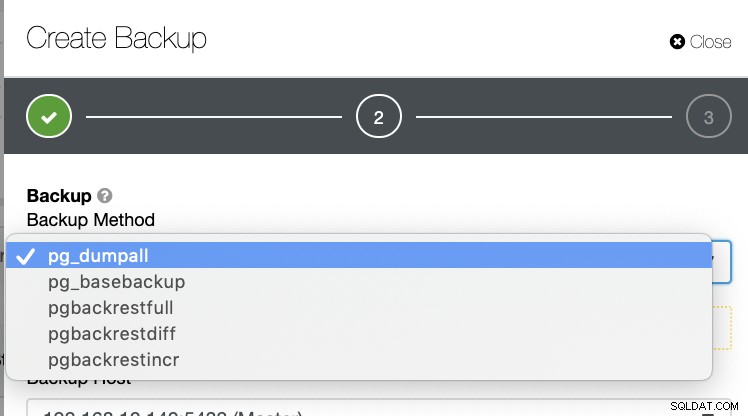
Der er ingen sådan mekanisme, hvor du selektivt kan gemme en tabel, en database, eller kopier fra en database til en anden database.
ClusterControl understøtter Point-in-Time Recovery (PITR), men dette tillader dig ikke at administrere datagendannelse så fleksibelt som med pg_restore. For alle listen over sikkerhedskopieringsmetoder er det kun pg_basebackup og pgbackrest, der er PITR-kompatible.
Hvordan ClusterControl håndterer gendannelse er, at den har evnen til at gendanne en mislykket klynge, så længe Autogendannelse er aktiveret som vist nedenfor.

Når masteren fejler, kan slaven automatisk gendanne klyngen, efterhånden som ClusterControl udfører failoveren (som sker automatisk). For datagendannelsesdelen er din eneste mulighed at have en gendannelse i hele klyngen, hvilket betyder, at den kommer fra en fuld sikkerhedskopi. Der er ingen mulighed for selektivt at gendanne den måldatabase eller -tabel, du kun ønskede at gendanne. Hvis du vil gøre det, skal du gendanne den fulde backup, det er nemt at gøre dette med ClusterControl. Du kan gå til Backup-fanerne som vist nedenfor,
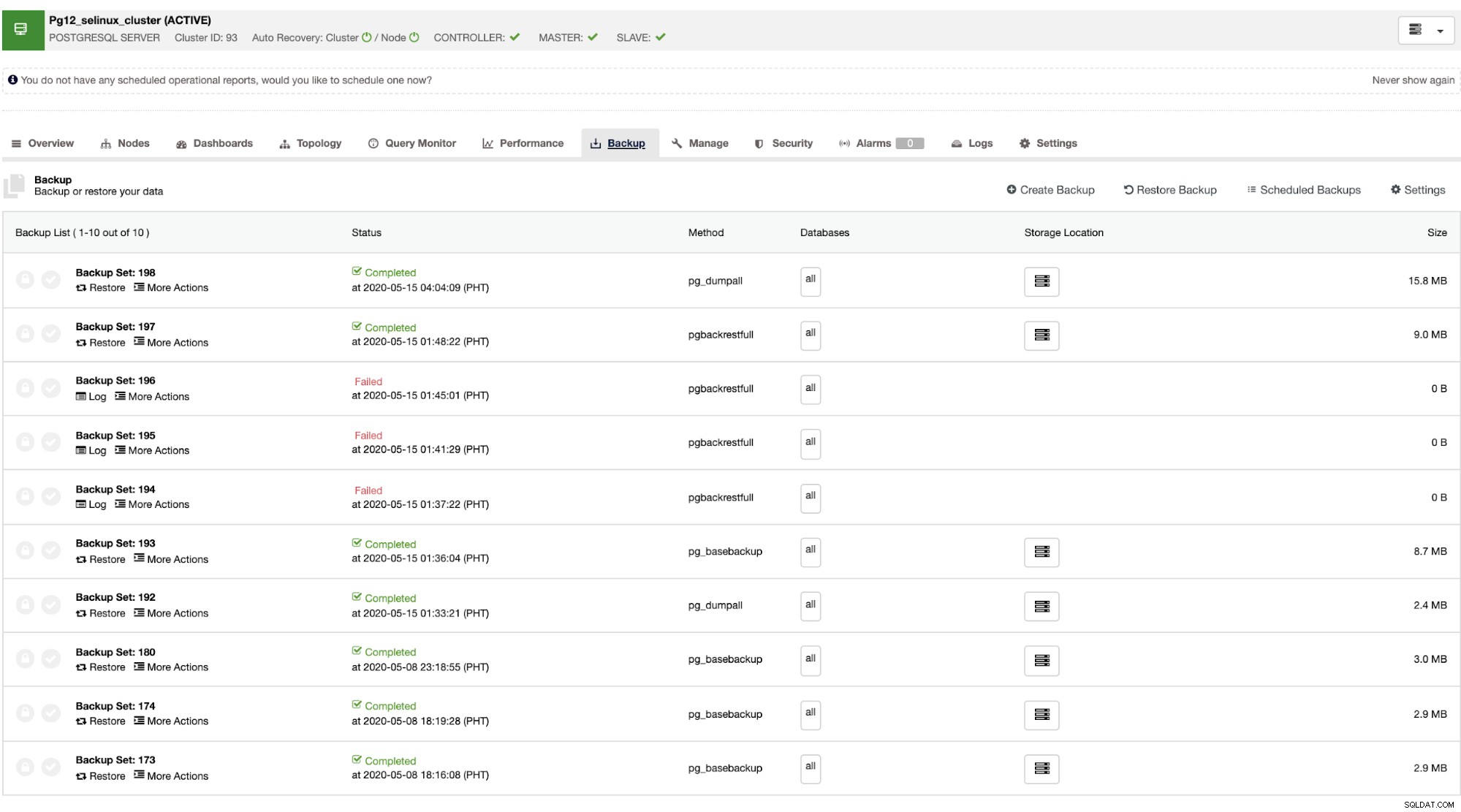
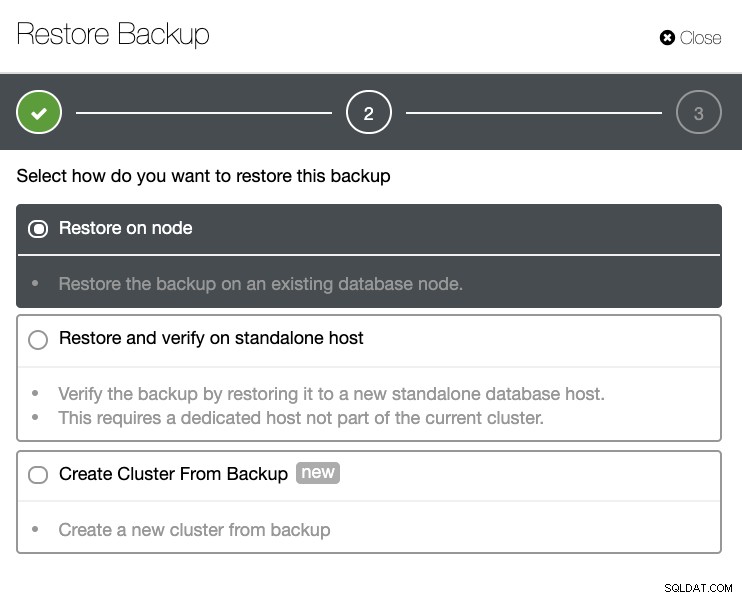
Du får en komplet liste over vellykkede og mislykkede sikkerhedskopier. Derefter kan gendannelsen ske ved at vælge målsikkerhedskopien og klikke på knappen "Gendan". Dette giver dig mulighed for at gendanne på en eksisterende node, der er registreret i ClusterControl, eller verificere på en selvstændig node eller oprette en klynge fra sikkerhedskopien.
Konklusion
Brug af pg_dump og pg_restore forenkler tilgangen til backup/dump og gendannelse. Men for et databasemiljø i stor skala er dette muligvis ikke en ideel komponent til gendannelse af katastrofer. For en minimal udvælgelses- og gendannelsesprocedure giver kombinationen af pg_dump og pg_restore dig mulighed for at dumpe og indlæse dine data i overensstemmelse med dine behov.
For produktionsmiljøer (især til virksomhedsarkitekturer) kan du bruge ClusterControl-tilgangen til at oprette en sikkerhedskopi og gendannelse med automatisk gendannelse.
En kombination af tilgange er også en god tilgang. Dette hjælper dig med at sænke din RTO og RPO og samtidig udnytte den mest fleksible måde at gendanne dine data på, når det er nødvendigt.