Når du skal implementere et analysesystem for en virksomhed, er der ofte spørgsmålet om, hvor dataene skal opbevares. Der er ikke altid en perfekt mulighed for alle kravene, og det afhænger af budgettet, mængden af data og virksomhedens behov.
PostgreSQL, som den mest avancerede open source-database, er så fleksibel, at den kan fungere som en simpel relationsdatabase, en tidsseriedatadatabase og endda som en effektiv, billig datavarehusløsning. Du kan også integrere det med flere analyseværktøjer.
Hvis du leder efter et bredt kompatibelt, billigt og effektivt datavarehus, kunne den bedste databasemulighed være PostgreSQL, men hvorfor? I denne blog vil vi se, hvad et datavarehus er, hvorfor er det nødvendigt, og hvorfor PostgreSQL kunne være den bedste mulighed her.
Hvad er et datavarehus
Et datavarehus er et system af standardiseret, konsistent og integreret, som indeholder aktuelle eller historiske data fra en eller flere kilder, der bruges til rapportering og dataanalyse. Det betragtes som en kernekomponent i business intelligence, som er den strategi og teknologi, som en virksomhed bruger til en bedre forståelse af dens kommercielle kontekst.
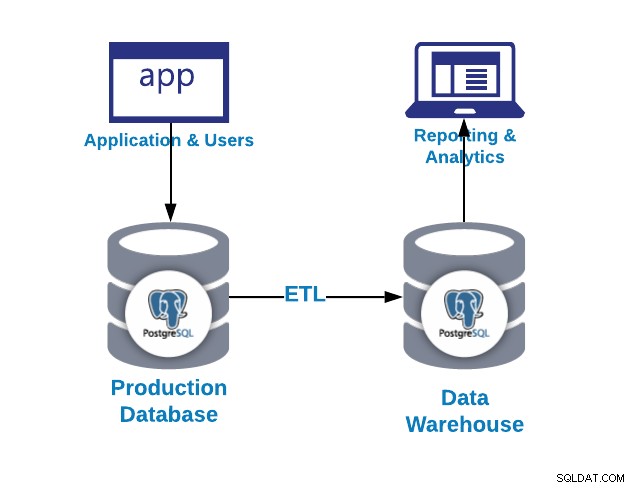
Det første spørgsmål, du kan stille, er, hvorfor har jeg brug for et datavarehus?
- Integration:Integrer/centraliser data fra flere systemer/databaser
- Standardiser:Standardiser alle data i samme format
- Analytik:Analyser data i en historisk kontekst
Nogle af fordelene ved et datavarehus kan være...
- Integrer data fra flere kilder i en enkelt database
- Undgå produktionslåsning eller belastning på grund af langvarige forespørgsler
- Gem historiske oplysninger
- Omstrukturer dataene, så de passer til analysekravene
Som vi kunne se i det forrige billede, kan vi bruge PostgreSQL til både OLAP- og OLTP-forslag. Lad os se forskellen.
- OLTP:Online transaktionsbehandling. Generelt har den et stort antal korte online-transaktioner (INSERT, UPDATE, DELETE) genereret af brugeraktivitet. Disse systemer lægger vægt på meget hurtig forespørgselsbehandling og vedligeholdelse af dataintegritet i multi-access-miljøer. Her måles effektiviteten ved antallet af transaktioner i sekundet. OLTP-databaser indeholder detaljerede og aktuelle data.
- OLAP:Online analytisk behandling. Generelt har den et lavt antal komplekse transaktioner genereret af store rapporter. Svartiden er et effektivitetsmål. Disse databaser gemmer aggregerede, historiske data i flerdimensionelle skemaer. OLAP-databaser bruges til at analysere multidimensionelle data fra flere kilder og perspektiver.
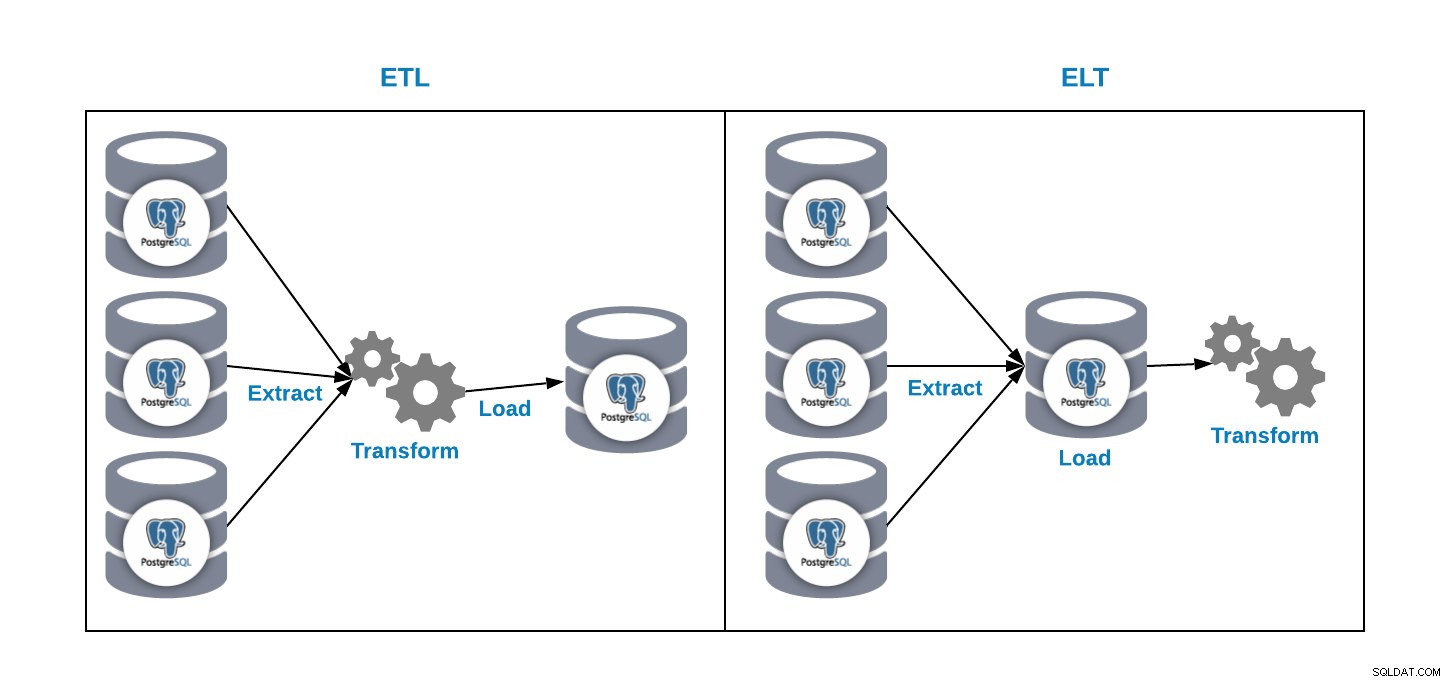
Vi har to måder at indlæse data i vores analysedatabase:
- ETL:Udpak, transformer og indlæs. Dette er måden at generere vores datavarehus på. Først skal du udtrække dataene fra produktionsdatabasen, transformere dataene i henhold til vores krav, og derefter indlæse dataene i vores datavarehus.
- ELT:Udtræk, indlæs og transformer. Først skal du udtrække dataene fra produktionsdatabasen, indlæse dem i databasen og derefter transformere dataene. Denne måde kaldes Data Lake, og det er et nyt koncept til at administrere vores store data.
Og nu, det andet spørgsmål er, hvorfor skal jeg bruge PostgreSQL til mit datavarehus?
Fordele ved PostgreSQL som et datavarehus
Lad os se på nogle af fordelene ved at bruge PostgreSQL som et datavarehus...
- Omkostninger:Hvis du bruger et lokalt miljø, vil prisen for selve produktet være 0 USD, selvom du bruger et eller andet produkt i skyen, vil prisen for et PostgreSQL-baseret produkt sandsynligvis være mindre end resten af produkterne.
- Skala:Du kan skalere læser den på en enkel måde ved at tilføje så mange replika-noder, som du vil.
- Ydeevne:Med en korrekt konfiguration har PostgreSQL en rigtig god ydeevne på forskellige scenarier.
- Kompatibilitet:Du kan integrere PostgreSQL med eksterne værktøjer eller applikationer til data mining, OLAP og rapportering.
- Udvidelsesmuligheder:PostgreSQL har brugerdefinerede datatyper og funktioner.
Der er også nogle PostgreSQL-funktioner, der kan hjælpe os med at administrere vores datavarehusoplysninger...
- Midlertidige tabeller:Det er en kortvarig tabel, der eksisterer i varigheden af en databasesession. PostgreSQL sletter automatisk de midlertidige tabeller i slutningen af en session eller en transaktion.
- Lagrede procedurer:Du kan bruge den til at oprette procedurer eller fungere på flere sprog (PL/pgSQL, PL/Perl, PL/Python osv.).
- Partitionering:Dette er virkelig nyttigt til databasevedligeholdelse, forespørgsler ved hjælp af partitionsnøgle og INSERT ydeevne.
- Materialiseret visning:Forespørgselsresultaterne vises som en tabel.
- Tablespaces:Du kan ændre dataplaceringen til en anden disk. På denne måde har du paralleliseret diskadgang.
- PITR-kompatibel:Du kan oprette sikkerhedskopier Point-in-time-gendannelseskompatibel, så i tilfælde af fejl, kan du gendanne databasetilstanden på et bestemt tidsrum.
- Enormt fællesskab:Og sidst, men ikke mindst, har PostgreSQL et kæmpe fællesskab, hvor du kan finde støtte til mange forskellige spørgsmål.
Konfiguration af PostgreSQL til datavarehusbrug
Der er ingen bedste konfiguration at bruge i alle tilfælde og i alle databaseteknologier. Det afhænger af mange faktorer såsom hardware, brug og systemkrav. Nedenfor er nogle tips til at konfigurere din PostgreSQL-database til at fungere som et datavarehus på den korrekte måde.
Hukommelsesbaseret
- max_connections:Som datavarehus-database behøver du ikke en høj mængde forbindelser, fordi dette vil blive brugt til rapportering og analysearbejde, så du kan begrænse antallet af maks. forbindelser ved hjælp af denne parameter.
- shared_buffers:Indstiller mængden af hukommelse, som databaseserveren bruger til delt hukommelsesbuffere. En rimelig værdi kan være fra 15 % til 25 % af RAM-hukommelsen.
- effective_cache_size:Denne værdi bruges af forespørgselsplanlæggeren til at tage hensyn til planer, der måske eller måske ikke passer i hukommelsen. Dette er taget i betragtning i omkostningsestimaterne ved brug af et indeks; en høj værdi gør det mere sandsynligt, at der bruges indeksscanninger, og en lav værdi gør det mere sandsynligt, at sekventielle scanninger vil blive brugt. En rimelig værdi ville være omkring 75 % af RAM-hukommelsen.
- work mem:Specificerer mængden af hukommelse, der vil blive brugt af de interne operationer af ORDER BY, DISTINCT, JOIN og hash-tabeller, før der skrives til de midlertidige filer på disken. Når vi konfigurerer denne værdi, skal vi tage højde for, at flere sessioner udfører disse operationer på samme tid, og hver operation vil få lov til at bruge så meget hukommelse som angivet af denne værdi, før den begynder at skrive data i midlertidige filer. En rimelig værdi kan være omkring 2 % af RAM-hukommelsen.
- maintenance_work_mem:Angiver den maksimale mængde hukommelse, som vedligeholdelsesoperationer vil bruge, såsom VACUUM, CREATE INDEX og ALTER TABLE ADD FOREIGN KEY. En rimelig værdi kan være omkring 15 % af RAM-hukommelsen.
CPU-baseret
- Max_worker_processes:Indstiller det maksimale antal baggrundsprocesser, som systemet kan understøtte. En rimelig værdi kan være antallet af CPU'er.
- Max_parallel_workers_per_gather:Indstiller det maksimale antal arbejdere, der kan startes af en enkelt Gather eller Gather Merge node. En rimelig værdi kan være 50 % af antallet af CPU'er.
- Max_parallel_workers:Indstiller det maksimale antal arbejdere, som systemet kan understøtte for parallelle forespørgsler. En rimelig værdi kan være antallet af CPU'er.
Da de data, der er indlæst i vores datavarehus, ikke bør ændre sig, kan vi også slå Autovacuum fra for at undgå en ekstra belastning på din PostgreSQL-database. Vakuum- og analyseprocesserne kan være en del af batch-indlæsningsprocessen.
Konklusion
Hvis du leder efter bredt kompatibel, lavpris og højtydende datavarehus, bør du helt sikkert overveje PostgreSQL som en mulighed for din datavarehusdatabase. PostgreSQL har mange fordele og funktioner, der er nyttige til at administrere vores datavarehus såsom partitionering eller lagrede procedurer og endnu mere.