Med Disaster Recovery sigter vi efter at opsætte systemer til at håndtere alt, der kunne gå galt med vores database. Hvad sker der, hvis databasen går ned? Hvad hvis en udvikler ved et uheld trunkerer en tabel? Hvad hvis vi finder ud af, at nogle data blev slettet i sidste uge, men vi lagde ikke mærke til det før i dag? Disse ting sker, og at have en solid plan og et system på plads vil få DBA til at ligne en helt, når alle andres hjerter allerede er stoppet, når en katastrofe rejser sit grimme hoved.
Enhver database, der har nogen form for værdi, bør have en måde at implementere en eller flere Disaster Recovery-muligheder på. PostgreSQL har et meget solidt replikeringssystem indbygget og er fleksibelt nok til at blive sat op i mange konfigurationer for at hjælpe med Disaster Recovery, hvis noget skulle gå galt. Vi vil fokusere på scenarier som ovenfor, hvordan vi konfigurerer vores muligheder for gendannelse efter katastrofe og fordelene ved hver løsning.
Høj tilgængelighed
Med streamingreplikering i PostgreSQL er High Availability enkel at konfigurere og vedligeholde. Målet er at levere et failover-sted, der kan forfremmes til at mestre, hvis hoveddatabasen går ned af en eller anden grund, såsom hardwarefejl, softwarefejl eller endda netværkssvigt. At være vært for en replika på en anden vært er fantastisk, men at hoste den i et andet datacenter er endnu bedre.
For detaljer om opsætning af streamingreplikering har Severalnines et detaljeret dybt dyk tilgængeligt her. Den officielle PostgreSQL-streamingreplikeringsdokumentation har detaljerede oplysninger om streamingreplikeringsprotokollen, og hvordan det hele fungerer.
En standardopsætning vil se sådan ud, en masterdatabase, der accepterer læse-/skriveforbindelser, med en replikadatabase, der modtager al WAL-aktivitet i næsten realtid, og afspiller al dataændringsaktivitet lokalt.
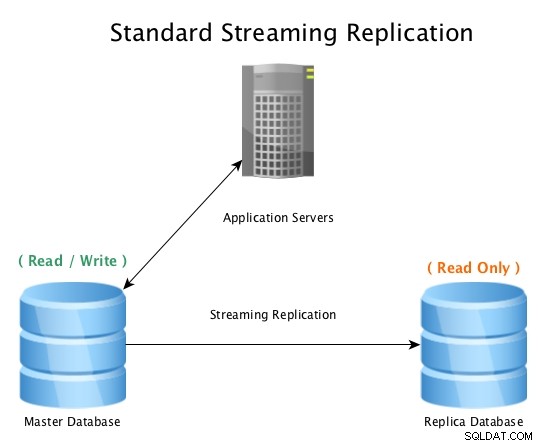 Standard streamingreplikering med PostgreSQL
Standard streamingreplikering med PostgreSQL Når masterdatabasen bliver ubrugelig, startes en failover-procedure for at bringe den offline og fremme replikadatabasen til master, hvorefter alle forbindelser peges på den nyligt forfremmede vært. Dette kan gøres ved enten at omkonfigurere en belastningsbalancer, applikationskonfiguration, IP-aliaser eller andre smarte måder at omdirigere trafikken på.
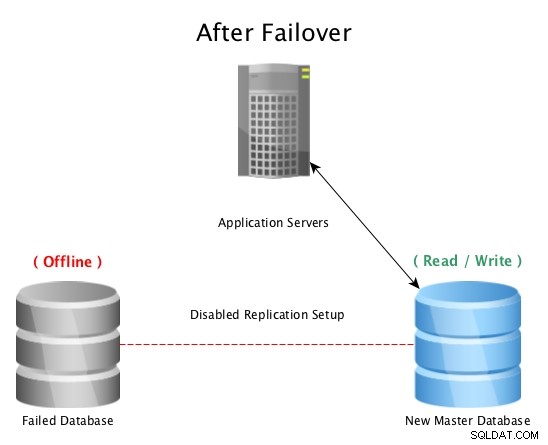 Efter en failover med PostgreSQL Streaming Replication
Efter en failover med PostgreSQL Streaming Replication Når en katastrofe rammer en masterdatabase (såsom en harddiskfejl, strømafbrydelse eller andet, der forhindrer masteren i at fungere efter hensigten), er det at svigte over til en varm standby den hurtigste måde at forblive online og sende forespørgsler til applikationer eller kunder uden alvorlige nedetid. Så er kapløbet i gang med enten at reparere den fejlbehæftede databasevært eller bringe en ny replika online for at opretholde sikkerhedsnettet med at have en standby klar til at gå. At have flere standbys vil sikre, at vinduet efter en katastrofal fejl også er klar til en sekundær fejl, hvor usandsynligt det end kan virke.
Bemærk:Når du fejler over til en streaming-replika, fortsætter den, hvor den tidligere master slap, så dette hjælper med at holde databasen online, men ikke genskabe tabte data ved et uheld.
Gendannelse af tidspunkter
En anden Disaster Recovery-mulighed er Point in TIME Recovery (PITR). Med PITR kan en kopi af databasen bringes tilbage på et hvilket som helst tidspunkt, vi ønsker, så længe vi har en basis backup fra før det tidspunkt, og alle WAL-segmenter, der var nødvendige indtil da.
En Point In Time Recovery-mulighed bringes ikke så hurtigt online som en Hot Standby, men den største fordel er at kunne gendanne et database-øjebliksbillede før en stor begivenhed, såsom en slettet tabel, dårlige data, der indsættes eller endda uforklarlig datakorruption . Alt, hvad der ville ødelægge data på en sådan måde, at vi ønsker at få en kopi før den ødelæggelse, redder PITR dagen.
Point in Time Recovery fungerer ved at skabe periodiske snapshots af databasen, normalt ved brug af programmet pg_basebackup, og opbevare arkiverede kopier af alle WAL-filer genereret af masteren
Point In Time Recovery Setup
Opsætningen kræver et par konfigurationsindstillinger indstillet på masteren, hvoraf nogle er gode at gå med standardværdier på den aktuelle seneste version, PostgreSQL 11. I dette eksempel kopierer vi 16MB-filen direkte til vores eksterne PITR-vært ved hjælp af rsync , og komprimere dem på den anden side med et cron job.
WAL-arkivering
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'BEMÆRK: Indstillingen archive_command kan være mange ting, det overordnede mål er at sende alle arkiverede WAL-filer væk til en anden vært af sikkerhedsmæssige årsager. Hvis vi mister nogen WAL-filer, bliver PITR forbi den tabte WAL-fil umulig. Lad din programmeringskreativitet gå amok, men sørg for, at den er pålidelig.
[Valgfrit] Komprimer de arkiverede WAL-filer:
Hver opsætning vil variere noget, men medmindre den pågældende database er meget let i dataopdateringer, vil opbygningen af 16 MB filer fylde drevplads ret hurtigt. Et let komprimeringsscript, opsat gennem cron, kunne se ud som nedenfor.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]BEMÆRK: Under enhver gendannelsesmetode skal alle komprimerede filer dekomprimeres senere. Nogle administratorer vælger kun at komprimere filer, når de er X antal dage gamle, hvilket holder den samlede plads lav, men holder også nyere WAL-filer klar til gendannelse uden ekstra arbejde. Vælg den bedste mulighed for de pågældende databaser for at maksimere din gendannelseshastighed.
Basissikkerhedskopier
En af nøglekomponenterne til en PITR-sikkerhedskopi er basissikkerhedskopieringen og hyppigheden af basissikkerhedskopiering. Disse kan være hver time, daglig, ugentlig, månedlig, men valgte den bedste mulighed baseret på genoprettelsesbehov såvel som trafikken i databasens dataafgang. Hvis vi har ugentlige sikkerhedskopier hver søndag, og vi skal gendanne hele vejen til lørdag eftermiddag, så bringer vi den foregående søndags basis backup online med alle WAL-filerne mellem den backup og lørdag eftermiddag. Hvis denne gendannelsesproces tager 10 timer at behandle, er denne sandsynligvis uønsket for lang. Daglige basissikkerhedskopieringer vil reducere gendannelsestiden, da basissikkerhedskopieringen ville være fra den morgen, men også øge mængden af arbejde på værten for basissikkerhedskopieringen sig selv.
Hvis en uge lang gendannelse af WAL-filer kun tager et par minutter, fordi databasen ser lav churn, så er ugentlige sikkerhedskopier fint. De samme data vil eksistere i sidste ende, men hvor hurtigt du kan få adgang til dem er nøglen.
I vores eksempel opretter vi en ugentlig basissikkerhedskopiering, og da vi bruger Streaming Replication for High Availability, såvel som at reducere belastningen på masteren, vil vi oprette basisbackup fra replikadatabasen.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zBEMÆRK: Kommandoen pg_basebackup antager, at denne vært er sat op til adgangskodeløs adgang til bruger-'replikering' på masteren, hvilket kan gøres enten ved at 'truste' i pg_hba for denne PITR-sikkerhedskopivært, adgangskode i .pgpass-filen eller andre mere sikre måder . Husk på sikkerheden, når du opsætter sikkerhedskopier.
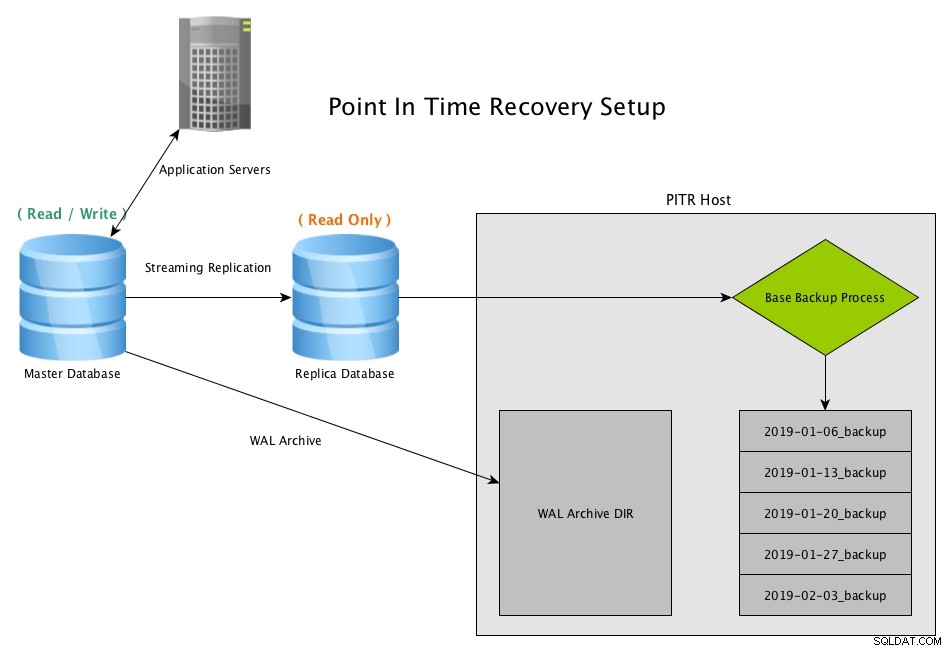 Point In Time Recovery (PITR) fra en streaming-replika med PostgreSQLDownload Whitepaper Today PostgreSQL Management &Control med Cluster Automation hvad du behøver at vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload hvidbogen
Point In Time Recovery (PITR) fra en streaming-replika med PostgreSQLDownload Whitepaper Today PostgreSQL Management &Control med Cluster Automation hvad du behøver at vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload hvidbogen PITR-gendannelsesscenarie
Opsætning af Point In Time Recovery er kun en del af jobbet, at skulle gendanne data er den anden del. Med held og lykke behøver dette måske aldrig ske, men det anbefales på det kraftigste at foretage en gendannelse af en PITR-sikkerhedskopi med jævne mellemrum for at validere, at systemet virker, og for at sikre, at processen er kendt/scriptet korrekt.
I vores testscenarie vælger vi et tidspunkt at gendanne til og påbegynde gendannelsesprocessen. For eksempel:Fredag morgen skubber en udvikler en ny kodeændring til produktion uden at gennemgå en kodegennemgang, og det ødelægger en masse vigtige kundedata. Da vores Hot Standby altid er synkroniseret med masteren, ville det ikke løse noget, da det ville være de samme data. PITR-sikkerhedskopier er det, der vil redde os.
Kode-pushet gik ind kl 11, så vi skal gendanne databasen til lige før det tidspunkt, 10:59 beslutter vi os, og heldigvis laver vi daglige backups, så vi har en backup fra midnat i morges. Da vi ikke ved, hvad det hele blev ødelagt, beslutter vi også at lave en fuldstændig gendannelse af denne database på vores PITR-vært og bringe den online som masteren, da den har de samme hardwarespecifikationer som masteren, i tilfælde af at dette scenariet skete.
Luk Mesteren
Da vi besluttede at gendanne fuldt ud fra en sikkerhedskopi og fremme den til master, er der ingen grund til at holde dette online. Vi lukker den ned, men beholder den, hvis vi skal have fat i noget fra den senere, for en sikkerheds skyld.
Konfigurer basebackup til gendannelse
Dernæst henter vi på vores PITR-vært vores seneste basisbackup fra før begivenheden, som er backup '2018-12-21_backup'.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Hermed er basissikkerhedskopieringen, såvel som WAL-filerne leveret af pg_basebackup, klar til at gå, hvis vi bringer den online nu, vil den gendanne til det punkt, hvor sikkerhedskopieringen fandt sted, men vi ønsker at gendanne alle WAL-transaktionerne mellem kl. midnat og 11:59, så vi konfigurerer vores recovery.conf-fil.
Opret recovery.conf
Da denne backup faktisk kom fra en streaming-replika, er der sandsynligvis allerede en recovery.conf-fil med replika-indstillinger. Vi vil overskrive det med nye indstillinger. En detaljeret informationsliste for alle forskellige muligheder er tilgængelig i PostgreSQLs dokumentation her.
Når du er forsigtig med WAL-filerne, vil gendannelseskommandoen kopiere de komprimerede filer, den skal bruge, til gendannelsesmappen, komprimere dem og derefter flytte til det sted, hvor PostgreSQL har brug for dem til gendannelse. De originale WAL-filer forbliver, hvor de er, hvis de er nødvendige af andre årsager.
Ny recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Start gendannelsesprocessen
Nu hvor alt er sat op, vil vi starte processen til gendannelse. Når dette sker, er det en god idé at hale databaseloggen for at sikre, at den gendannes efter hensigten.
Start DB:
pg_ctl -D /var/lib/pgsql/11/data startTilslut logfilerne:
Der vil være mange logindtastninger, der viser, at databasen er ved at genoprette fra arkivfiler, og på et bestemt tidspunkt vil den vise en linje, der siger "gendannelse stopper før begåelse af transaktion ..."
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07På dette tidspunkt har gendannelsesprocessen indtaget alle WAL-filer, men har også brug for gennemgang, før den kommer online som en master. I dette eksempel bemærker loggen, at den næste transaktion efter gendannelsesmåltiden 11:59:00 var 11:59:01, og den blev ikke gendannet. For at bekræfte, skal du logge ind på databasen og tage et kig, den kørende database skal være et øjebliksbillede pr. 11:59 nøjagtigt.
Når alt ser godt ud, tid til at fremme restitutionen som en mester.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Nu er databasen online, gendannet til det punkt, vi besluttede, og accepterer læse/skrive-forbindelser som en masterknude. Sørg for, at alle konfigurationsparametre er korrekte og klar til produktion.
Databasen er online, men gendannelsesprocessen er ikke færdig endnu! Nu hvor denne PITR-sikkerhedskopi er online som master, bør der sættes en ny standby- og PITR-opsætning op, indtil da kan denne nye master være online og betjene applikationer, men den er ikke sikker fra en anden katastrofe, før det hele er sat op igen.
Andre scenarier for gendannelse af tidspunkt
At bringe en PITR-sikkerhedskopi tilbage for en hel database er et ekstremt tilfælde, men der er andre scenarier, hvor kun en delmængde af data mangler, er korrupte eller dårlige. I disse tilfælde kan vi være kreative med vores muligheder for gendannelse. Uden at bringe masteren offline og erstatte den med en sikkerhedskopi, kan vi bringe en PITR-sikkerhedskopi online til det nøjagtige tidspunkt, vi ønsker på en anden vært (eller en anden port, hvis pladsen ikke er et problem), og eksportere de gendannede data fra sikkerhedskopien direkte ind i masterdatabasen. Dette kan bruges til at gendanne en håndfuld rækker, en håndfuld tabeller eller enhver konfiguration af data, der er nødvendig.
Med streaming-replikering og Point In Time Recovery giver PostgreSQL os stor fleksibilitet til at sikre, at vi kan gendanne alle data, vi har brug for, så længe vi har standby-værter klar til at gå som master eller sikkerhedskopier klar til gendannelse. En god Disaster Recovery-mulighed kan udvides yderligere med andre sikkerhedskopieringsmuligheder, flere replika-noder, flere sikkerhedskopieringssteder på tværs af forskellige datacentre og kontinenter, periodiske pg_dumps på en anden replika osv.
Disse muligheder kan lægge sammen, men det virkelige spørgsmål er 'hvor værdifulde er dataene, og hvor meget er du villig til at bruge for at få dem tilbage?'. Mange tilfælde er tabet af data enden på en virksomhed, så gode muligheder for at genoprette katastrofe bør være på plads for at forhindre det værste i at ske.