Håndtering af en PostgreSQL-installation involverer inspektion og kontrol over en lang række aspekter i den software/infrastruktur-stack, som PostgreSQL kører på. Dette skal dække:
- Applikationsjustering vedrørende databasebrug/transaktioner/forbindelser
- Databasekode (forespørgsler, funktioner)
- Databasesystem (ydeevne, HA, sikkerhedskopier)
- Hardware/infrastruktur (diske, CPU/hukommelse)
PostgreSQL-kernen giver databaselaget, som vi stoler på, at vores data bliver lagret, behandlet og serveret på. Det giver også al teknologien til at have et virkelig moderne, effektivt, pålideligt og sikkert system. Men ofte er denne teknologi ikke tilgængelig som et klar til brug, raffineret business/enterprise klasse produkt i kerne PostgreSQL distributionen. I stedet er der en masse produkter/løsninger enten fra PostgreSQL-fællesskabet eller kommercielle tilbud, der opfylder disse behov. Disse løsninger kommer enten som brugervenlige forbedringer af kerneteknologierne eller udvidelser af kerneteknologierne eller endda som integration mellem PostgreSQL-komponenter og andre komponenter i systemet. I vores tidligere blog med titlen Ti tips til at gå i produktion med PostgreSQL undersøgte vi nogle af de værktøjer, som kan hjælpe med at styre en PostgreSQL-installation i produktionen. I denne blog vil vi udforske mere detaljeret de aspekter, der skal dækkes, når man administrerer en PostgreSQL-installation i produktionen, og de mest almindeligt anvendte værktøjer til det formål. Vi vil dække følgende emner:
- Implementering
- Ledelse
- Skalering
- Overvågning
Implementering
I gamle dage plejede folk at downloade og kompilere PostgreSQL i hånden og derefter konfigurere runtime-parametrene og brugeradgangskontrol. Der er stadig nogle tilfælde, hvor dette kan være nødvendigt, men efterhånden som systemerne modnes og begyndte at vokse, opstod behovet for mere standardiserede måder at implementere og administrere Postgresql på. De fleste OS'er leverer pakker til at installere, implementere og administrere PostgreSQL-klynger. Debian har standardiseret deres eget systemlayout, der understøtter mange Postgresql-versioner og mange klynger pr. version på samme tid. postgresql-common debian-pakken indeholder de nødvendige værktøjer. For at oprette en ny klynge (kaldet i18n_cluster) til PostgreSQL version 10 i Debian kan vi for eksempel gøre det ved at give følgende kommandoer:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsOpdater derefter systemd:
$ sudo systemctl daemon-reloadog til sidst start og brug den nye klynge:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(bemærk, at Debian håndterer forskellige klynger ved at bruge forskellige porte 5432, 5433 og så videre)
Efterhånden som behovet vokser for mere automatiserede og massive implementeringer, bruger flere og flere installationer automatiseringsværktøjer som Ansible, Chef og Puppet. Udover automatisering og reproducerbarhed af implementeringer, er automatiseringsværktøjer fantastiske, fordi de er en god måde at dokumentere implementeringen og konfigurationen af en klynge. På den anden side har automatisering udviklet sig til at blive et stort felt alene, der kræver dygtige folk til at skrive, administrere og køre automatiserede scripts. Mere information om PostgreSQL-provisionering kan findes i denne blog:Bliv en PostgreSQL DBA:Provisioning and Deployment.
Ledelse
Håndtering af et live-system involverer opgaver som:planlægge sikkerhedskopier og overvåge deres status, gendannelse af katastrofer, konfigurationsstyring, styring af høj tilgængelighed og automatisk failover-håndtering. Sikkerhedskopiering af en Postgresql-klynge kan gøres på forskellige måder. Værktøjer på lavt niveau:
- traditionel pg_dump (logisk backup)
- Sikkerhedskopier på filsystemniveau (fysisk backup)
- pg_basebackup (fysisk backup)
Eller højere niveau:
- Barmand
- PgBackRest
Hver af disse måder dækker forskellige brugsscenarier og gendannelsesscenarier og varierer i kompleksitet. PostgreSQL backup er tæt forbundet med begreberne PITR, WAL arkivering og replikering. Gennem årene har proceduren med at tage, teste og endelig (kryds fingre!) brug af backups med PostgreSQL udviklet sig til at være en kompleks opgave. Man kan finde en fin oversigt over backup-løsningerne til PostgreSQL i denne blog:Top Backup Tools for PostgreSQL.
Med hensyn til høj tilgængelighed og automatisk failover er det absolutte minimum, som en installation skal have for at implementere dette:
- En fungerende primær
- En varm standby, der accepterer WAL, streamet fra den primære
- I tilfælde af mislykket primær, en metode til at fortælle den primære, at den ikke længere er den primære (nogle gange kaldet STONITH)
- En hjerteslagsmekanisme til at tjekke for forbindelse mellem de to servere og tilstanden af den primære
- En metode til at udføre failover (f.eks. via pg_ctl promote eller trigger-fil)
- En automatiseret procedure til genskabelse af den gamle primære som en ny standby:Når en afbrydelse eller fejl på den primære er opdaget, skal en standby fremmes som den nye primære. Den gamle primære er ikke længere gyldig eller brugbar. Så systemet skal have en måde at håndtere denne tilstand mellem failover og genskabelsen af den gamle primære server som den nye standby. Denne tilstand kaldes degenereret tilstand, og PostgreSQL'en leverer et værktøj kaldet pg_rewind for at fremskynde processen med at bringe den gamle primære tilbage i synkroniseret tilstand fra den nye primære.
- En metode til at foretage on-demand/planlagte overgange
Et meget brugt værktøj, der håndterer alt ovenstående, er Repmgr. Vi vil beskrive den minimale opsætning, der giver mulighed for en vellykket overgang. Vi starter med en fungerende PostgreSQL 10.4 primær, der kører på FreeBSD 11.1, manuelt bygget og installeret, og repmgr 4.0 også manuelt bygget og installeret til denne version (10.4). Vi vil bruge to værter ved navn fbsd (192.168.1.80) og fbsdclone (192.168.1.81) med identiske versioner af PostgreSQL og repmgr. På den primære (oprindeligt fbsd , 192.168.1.80) sørger vi for, at følgende PostgreSQL-parametre er indstillet:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Derefter opretter vi repmgr-brugeren (som superbruger) og databasen:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgrog opsæt værtsbaseret adgangskontrol i pg_hba.conf ved at sætte følgende linjer øverst:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustVi sørger for, at vi opsætter adgangskodefrit login til bruger repmgr i alle noder i klyngen, i vores tilfælde fbsd og fbsdclone ved at indstille authorized_keys i .ssh og derefter dele .ssh. Derefter opretter vi repmrg.conf på den primære som:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Så registrerer vi den primære:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredOg kontroller status for klyngen:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Vi arbejder nu på standby ved at indstille repmgr.conf som følger:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Vi sørger også for, at den datamappe, der er angivet i linjen ovenfor, eksisterer, er tom og har de korrekte tilladelser:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataVi skal nu klone til vores nye standby:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"Og start standby:
example@sqldat.com:~ % pg_ctl -D data startPå dette tidspunkt skulle replikering fungere som forventet. Bekræft dette ved at forespørge pg_stat_replikation (fbsd) og pg_stat_wal_receiver (fbsdclone). Næste trin er at registrere standby:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerNu kan vi få status for klyngen på enten standby eller primær og kontrollere, at standby er registreret:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Lad os nu antage, at vi ønsker at udføre en planlagt manuel overgang for f.eks. at lave noget administrationsarbejde på node fbsd. På standby-noden kører vi følgende kommando:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyOmstillingen er gennemført med succes! Lad os se, hvad klyngeshow giver:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2De to servere har byttet roller! Repmgr leverer repmgrd daemon, som giver overvågning, automatisk failover samt meddelelser/alarmer. Ved at kombinere repmgrd med pgbouncer, er det muligt at implementere automatisk opdatering af forbindelsesoplysningerne for databasen, hvilket giver hegn for den mislykkede primære (forhindrer den mislykkede node fra enhver brug af applikationen) samt giver minimal nedetid for applikationen. I mere komplekse skemaer er en anden idé at kombinere Keepalved med HAProxy oven på pgbouncer og repmgr for at opnå:
- belastningsbalancering (skalering)
- høj tilgængelighed
Bemærk, at ClusterControl også administrerer failover af PostgreSQL-replikeringsopsætninger og integrerer HAProxy og VirtualIP for automatisk at omdirigere klientforbindelser til den fungerende master. Mere information kan findes i dette hvidbog om PostgreSQL Automation.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperSkalering
Fra PostgreSQL 10 (og 11) er der stadig ingen måde at få multi-master replikering på, i hvert fald ikke fra kerne PostgreSQL. Det betyder, at kun den valgte aktivitet (skrivebeskyttet) kan skaleres op. Skalering i PostgreSQL opnås ved at tilføje flere hot standbys, hvilket giver flere ressourcer til skrivebeskyttet aktivitet. Med repmgr er det nemt at tilføje ny standby, som vi så tidligere via standby klon og standby-registrering kommandoer. Standbys tilføjet (eller fjernet) skal gøres bekendt med konfigurationen af load-balancer. HAProxy, som nævnt ovenfor i ledelsesemnet, er en populær load balancer til PostgreSQL. Normalt er det koblet med Keepalived, som giver virtuel IP via VRRP. En fin oversigt over brugen af HAProxy og Keepalived sammen med PostgreSQL kan findes i denne artikel:PostgreSQL Load Balancing Using HAProxy &Keepalived.
Overvågning
En oversigt over, hvad der skal overvåges i PostgreSQL, kan findes i denne artikel:Key Things to Monitor in PostgreSQL - Analysing Your Workload. Der er mange værktøjer, der kan give system- og postgresql-overvågning via plugins. Nogle værktøjer dækker området med at præsentere grafiske diagrammer over historiske værdier (munin), andre værktøjer dækker området for overvågning af live-data og levering af live-alarmer (nagios), mens nogle værktøjer dækker begge områder (zabbix). En liste over sådanne værktøjer til PostgreSQL kan findes her:https://wiki.postgresql.org/wiki/Monitoring. Et populært værktøj til offline (logfilbaseret) overvågning er pgBadger. pgBadger er et Perl-script, som fungerer ved at analysere PostgreSQL-loggen (som normalt dækker en dags aktivitet), udtrække information, beregne statistik og til sidst producere en fancy html-side, der præsenterer resultaterne. pgBadger er ikke begrænsende for log_line_prefix-indstillingen, den kan tilpasse sig dit allerede eksisterende format. For eksempel hvis du har sat noget i din postgresql.conf som:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'derefter kan kommandoen pgbadger til at parse logfilen og producere resultaterne se ud som:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger leverer rapporter for:
- Oversigtsstatistik (for det meste SQL-trafik)
- Forbindelser (pr. sekund, pr. database/bruger/vært)
- Sessioner (antal, sessionstider, pr. database/bruger/vært/applikation)
- Kontrolpunkter (buffere, wal-filer, aktivitet)
- Brug af midlertidige filer
- Vakuum/analysere aktivitet (pr. tabel, tupler/sider fjernet)
- Låse
- Forespørgsler (efter type/database/bruger/vært/applikation, varighed efter bruger)
- Top (Forespørgsler:langsomste, tidskrævende, hyppigere, normaliseret langsomste)
- Begivenheder (fejl, advarsler, dødsfald osv.)
Skærmbilledet, der viser sessionerne, ser sådan ud:
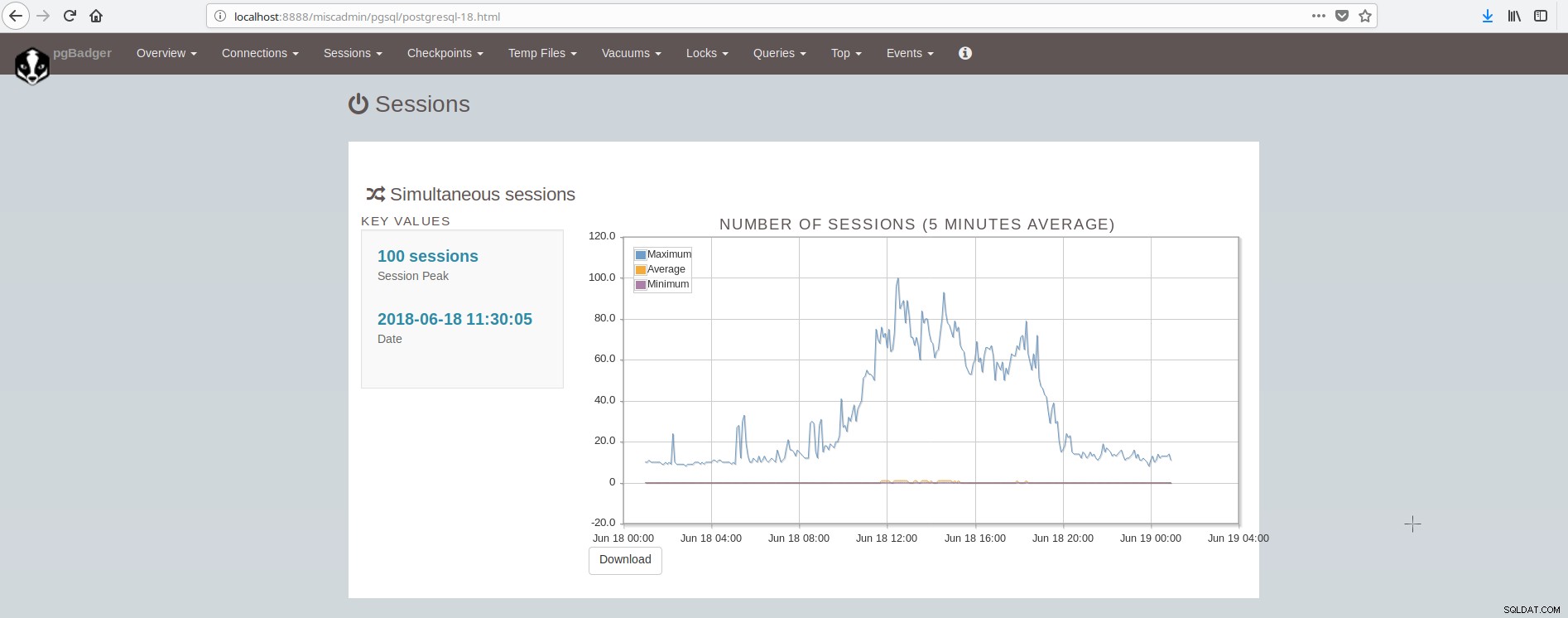
Som vi kan konkludere, skal den gennemsnitlige PostgreSQL-installation integrere og tage sig af mange værktøjer for at have en moderne pålidelig og hurtig infrastruktur, og dette er ret komplekst at opnå, medmindre der er store teams involveret i postgresql og systemadministration. En fin suite, der gør alt ovenstående og mere, er ClusterControl.