At gå i produktion er en meget vigtig opgave, som skal være nøje gennemtænkt og planlagt på forhånd. Nogle mindre gode beslutninger kan let rettes bagefter, men andre ikke. Så det er altid bedre at bruge den ekstra tid på at læse de officielle dokumenter, bøger og forskning lavet af andre tidligt, end at være ked af det senere. Dette gælder for de fleste computersystemer, og PostgreSQL er ingen undtagelse.
Initial planlægning af systemet
Nogle beslutninger skal tages tidligt, før systemet går live. PostgreSQL DBA'en skal besvare en række spørgsmål:Vil DB køre på bare metal, VM'er eller endda containeriseret? Vil det køre i organisationens lokaler eller i skyen? Hvilket OS vil blive brugt? Skal lageret være af typen roterende diske eller SSD'er? For hvert scenarie eller beslutning er der fordele og ulemper, og det endelige opkald vil blive foretaget i samarbejde med interessenterne i henhold til organisationens krav. Traditionelt plejede folk at køre PostgreSQL på bart metal, men dette har ændret sig dramatisk i de seneste år med flere og flere cloud-udbydere, der tilbyder PostgreSQL som en standardmulighed, hvilket er et tegn på den brede adoption og et resultat af den stigende popularitet af PostgreSQL. Uafhængigt af den konkrete løsning skal DBA sikre, at dataene er sikre, hvilket betyder, at databasen vil kunne overleve nedbrud, og det er No1-kriteriet, når der skal træffes beslutninger om hardware og opbevaring. Så dette bringer os til det første tip!
Tip 1
Uanset hvad diskcontrolleren eller diskproducenten eller cloud storage-udbyderen annoncerer, bør du altid sikre dig, at lageret ikke lyver om fsync. Når fsync vender tilbage OK, bør dataene være sikre på mediet, uanset hvad der sker bagefter (nedbrud, strømsvigt osv.). Et godt værktøj, der vil hjælpe dig med at teste pålideligheden af dine diskes tilbageskrivningscache, er diskchecker.pl.
Bare læs noterne:https://brad.livejournal.com/2116715.html og lav testen.
Brug én maskine til at lytte til begivenheder og den faktiske maskine til at teste. Du skal se:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0i slutningen af rapporten om den testede maskine.
Den anden bekymring efter pålidelighed bør handle om ydeevne. Beslutninger om system (CPU, hukommelse) plejede at være meget vigtigere, da det var ret svært at ændre dem senere. Men i nutidens, i cloud-æraen, kan vi være mere fleksible omkring de systemer, som DB'en kører på. Det samme gælder for opbevaring, især i et systems tidlige levetid, og mens størrelserne stadig er små. Når DB'en kommer forbi TB-tallet i størrelse, bliver det sværere og sværere at ændre grundlæggende lagringsparametre uden at skulle helt kopiere databasen - eller endnu værre, at udføre en pg_dump, pg_restore. Det andet tip handler om systemets ydeevne.
Tip 2
På samme måde som altid at teste producenternes løfter om pålidelighed, det samme bør du gøre med hardwareydelse. Bonnie++ er det mest populære benchmark for lagerydeevne for Unix-lignende systemer. Til overordnet systemtest (CPU, hukommelse og også lagring) er intet mere repræsentativt end DB'ens ydeevne. Så den grundlæggende præstationstest på dit nye system ville være at køre pgbench, den officielle PostgreSQL benchmark suite baseret på TCP-B.
Det er ret nemt at komme i gang med pgbench, alt du skal gøre er:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Du bør altid konsultere pgbench efter enhver vigtig ændring, som du ønsker at vurdere og sammenligne resultaterne.
Systemimplementering, automatisering og overvågning
Når du først går live, er det meget vigtigt at have dine vigtigste systemkomponenter dokumenterede og reproducerbare, at have automatiserede procedurer til at skabe tjenester og tilbagevendende opgaver og også have værktøjerne til at udføre kontinuerlig overvågning.
Tip 3
En praktisk måde at begynde at bruge PostgreSQL med alle dets avancerede virksomhedsfunktioner på er ClusterControl af Severalnines. Man kan have en PostgreSQL-klynge i virksomhedsklassen, blot ved at trykke på et par klik. ClusterControl leverer alle de førnævnte tjenester og mange flere. Opsætning af ClusterControl er ret let, følg blot instruktionerne i den officielle dokumentation. Når du har forberedt dine systemer (typisk et til at køre CC og et til PostgreSQL til en grundlæggende opsætning) og lavet SSH opsætningen, så skal du indtaste de grundlæggende parametre (IP'er, portnr. osv.), og hvis alt går vel skal du se et output som følgende:
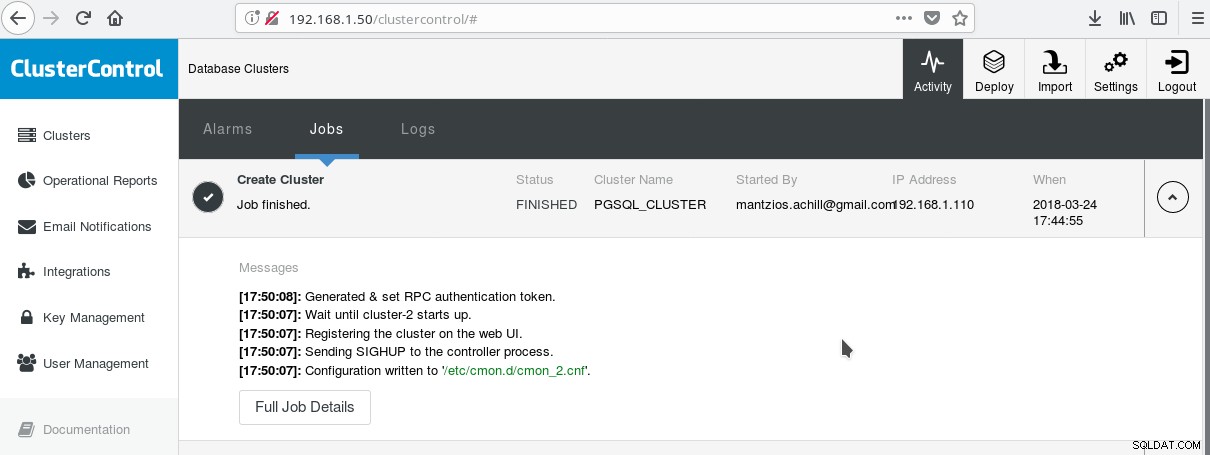
Og i hovedklyngerskærmen:
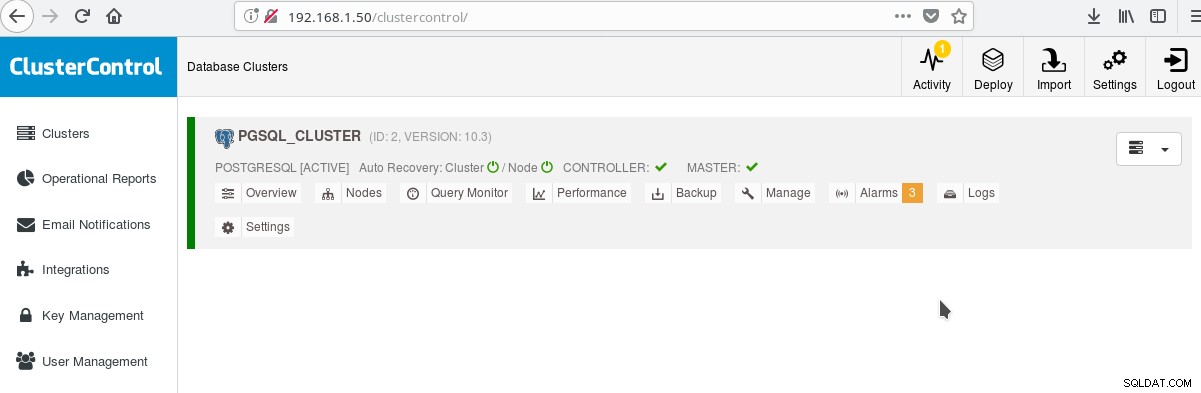
Du kan logge ind på din masterserver og begynde at oprette dit skema! Du kan selvfølgelig bruge den klynge, du lige har oprettet, som grundlag for yderligere at opbygge din infrastruktur (topologi). En generelt god idé er at have et stabilt serverfilsystemlayout og en endelig konfiguration på din PostgreSQL-server og bruger-/appdatabaser, før du begynder at oprette kloner og standbys (slaver) baseret på din netop oprettede splinternye server.
PostgreSQL-layout, parametre og indstillinger
I klyngeinitieringsfasen er den vigtigste beslutning, om der skal bruges datakontrolsummer på datasider eller ej. Hvis du ønsker maksimal datasikkerhed for dine værdifulde (fremtidige) data, så er det nu, du skal gøre det. Hvis der er en chance for, at du måske vil have denne funktion i fremtiden, og du undlader at gøre det på dette tidspunkt, vil du ikke være i stand til at ændre det senere (uden pg_dump/pg_restore altså). Dette er det næste tip:
Tip 4
For at aktivere datakontrolsummer skal du køre initdb som følger:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Bemærk, at dette skal gøres på tidspunktet for tip 3, vi beskrev ovenfor. Hvis du allerede har oprettet klyngen med ClusterControl, bliver du nødt til at køre pg_createcluster igen i hånden, da der i skrivende stund ikke er nogen måde at fortælle systemet eller CC om at inkludere denne mulighed.
Et andet meget vigtigt trin, før du går i produktion, er planlægning af serverens filsystemlayout. De fleste moderne linux distros (i det mindste de debian-baserede) monterer alt på / men med PostgreSQL vil du normalt ikke have det. Det er fordelagtigt at have din tablespace(r) på separate volumen(er), at have en volumen dedikeret til WAL-filerne og en anden til pg-log. Men det vigtigste er at flytte WAL til sin egen disk. Dette bringer os til det næste tip.
Tip 5
Med PostgreSQL 10 på Debian Stretch kan du flytte din WAL til en ny disk med følgende kommandoer (hvis den nye disk hedder /dev/sdb ):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlDet er ekstremt vigtigt at konfigurere lokaliteten og kodningen af dine databaser korrekt. Overse dette i den oprettede fase, og du vil fortryde det dybt, da din app/DB bevæger sig ind i i18n, l10n-områderne. Det næste tip viser, hvordan du gør det.
Tip 6
Du bør læse de officielle dokumenter og beslutte dig for dine COLLATE og CTYPE (createdb --locale=) indstillinger (ansvarlig for sorteringsrækkefølge og karakterklassificering) samt charset (createdb --encoding=) indstillingen. Angivelse af UTF8 som kodning vil gøre det muligt for din database at gemme flersproget tekst.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperPostgreSQL høj tilgængelighed
Siden PostgreSQL 9.0, da streaming-replikering blev en standardfunktion, blev det muligt at have en eller flere skrivebeskyttede hot-standbys, hvilket muliggjorde muligheden for at dirigere den skrivebeskyttede trafik til enhver af de tilgængelige slaver. Der eksisterer nye planer for multimaster-replikering, men på tidspunktet for denne skrivning (10.3) er det kun muligt at have én læse-skrive-master, i det mindste i det officielle open source-produkt. Til det næste tip, som omhandler netop dette.
Tip 7
Vi vil bruge vores ClusterControl PGSQL_CLUSTER oprettet i tip 3. Først opretter vi en anden maskine, som vil fungere som vores skrivebeskyttede slave (hot standby i PostgreSQL-terminologi). Derefter klikker vi på Tilføj replikeringsslave, og vælger vores master og den nye slave. Når jobbet er afsluttet, skulle du se dette output:
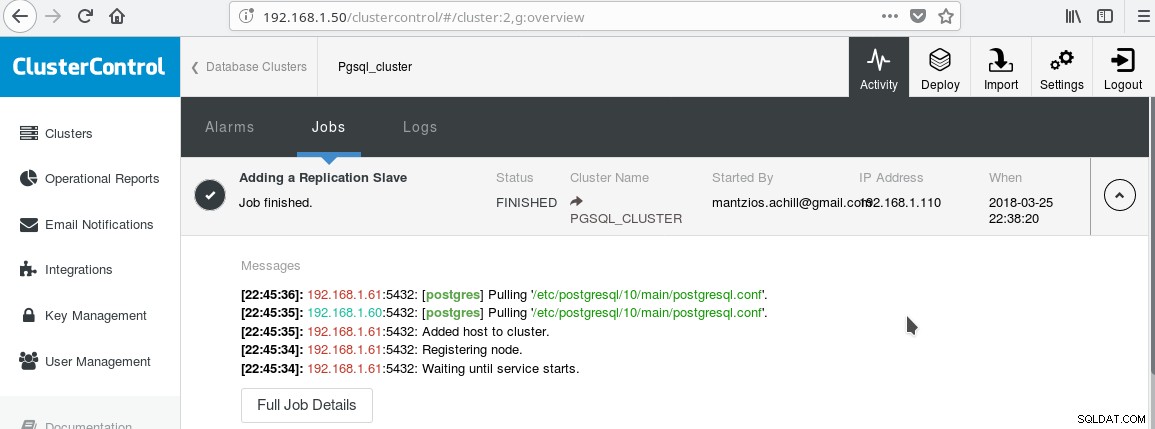
Og klyngen skulle nu se sådan ud:
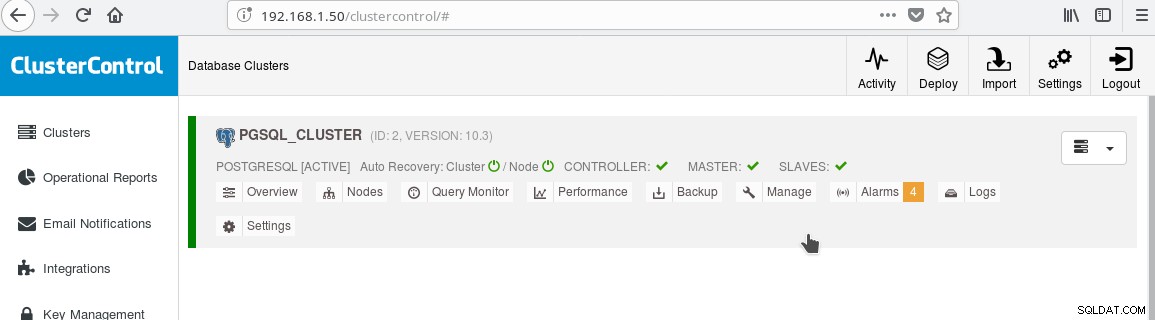
Bemærk det grønne "afkrydsede" ikon på "SLAVES" etiketten ved siden af "MASTER". Du kan kontrollere, at streaming-replikeringen fungerer, ved at oprette et databaseobjekt (database, tabel osv.) eller indsætte nogle rækker i en tabel på masteren og se ændringen på standby.
Tilstedeværelsen af skrivebeskyttet standby gør det muligt for os at udføre belastningsbalancering for klienter, der laver kun udvalgte forespørgsler mellem de to tilgængelige servere, masteren og slaven. Dette fører os til tip 8.
Tip 8
Du kan aktivere belastningsbalancering mellem de to servere ved hjælp af HAProxy. Med ClusterControl er dette ret nemt at gøre. Du klikker på Administrer->Load Balancer. Efter at have valgt din HAProxy-server, vil ClusterControl installere alt for dig:xinetd på alle forekomster, du har angivet, og HAProxy på din HAProxy-designede server. Når jobbet er afsluttet med succes, skulle du se:
Bemærk det grønne HAPROXY flueben ved siden af SLAVERNE. Nu kan du teste, at HAProxy virker:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Tip 9
Udover at konfigurere til HA og belastningsbalancering, er det altid en fordel at have en form for forbindelsespulje foran PostgreSQL-serveren. Pgpool og Pgbouncer er to projekter, der kommer fra PostgreSQL-fællesskabet. Mange virksomhedsapplikationsservere har også deres egne pools. Pgbouncer har været meget populær på grund af dens enkelhed, hastighed og "transaktionspooling"-funktionen, hvorved forbindelsen til serveren frigøres, når transaktionen slutter, hvilket gør den genbrugelig til efterfølgende transaktioner, der kan komme fra den samme session eller en anden. . Indstillingen for transaktionspooling bryder nogle sessionspoolingfunktioner, men generelt er konverteringen til en "transaktionspooling"-klar opsætning let, og ulemperne er ikke så vigtige i det generelle tilfælde. En almindelig opsætning er at konfigurere app-serverens pool med semi-vedvarende forbindelser:En temmelig større pulje af forbindelser pr. bruger eller pr. app (som forbinder til pgbouncer) med lange inaktive timeouts. På denne måde er forbindelsestiden fra appen minimal, mens pgbouncer hjælper med at holde forbindelser til serveren så få som muligt.
En ting, der sandsynligvis vil give anledning til bekymring, når du går live med PostgreSQL, er at forstå og rette langsomme forespørgsler. De overvågningsværktøjer, vi nævnte i den forrige blog som pg_stat_statements og også skærmbillederne med værktøjer som ClusterControl vil hjælpe dig med at identificere og muligvis foreslå ideer til at rette langsomme forespørgsler. Men når du først har identificeret den langsomme forespørgsel, bliver du nødt til at køre EXPLAIN eller EXPLAIN ANALYZE for at se nøjagtigt de omkostninger og tider, der er involveret i forespørgselsplanen. Det næste tip handler om et meget nyttigt værktøj til at gøre det.
Tip 10
Du skal køre din EXPLAIN ANALYZE på din database, og derefter kopiere outputtet og indsætte det på depesz's forklaringsanalyse-onlineværktøj og klik på send. Så vil du se tre faner:HTML, TEKST og STATISTIK. HTML indeholder omkostninger, tid og antal loops for hver node i planen. STATISTIK-fanen viser pr. node type statistik. Du bør observere kolonnen "% af forespørgsel", så du ved, hvor din forespørgsel præcist lider.
Efterhånden som du bliver mere fortrolig med PostgreSQL, vil du finde mange flere tips på egen hånd!