PostgreSQL, også kendt som verdens mest avancerede open source-database, har en ny udgivelsesversion siden den 24. september 2020, og nu den er moden, kan vi tjekke, hvad der er nyt der for at begynde at tænke på en migrationsplan. PostgreSQL 13 er tilgængelig med mange nye funktioner og forbedringer. I denne blog vil vi nævne nogle af disse nye funktioner og se, hvordan du implementerer eller opgraderer din nuværende PostgreSQL-version.
PostgreSQL 13 nye funktioner og forbedringer
Lad os begynde at nævne nogle af de nye funktioner og forbedringer af denne PostgreSQL 13-version, som du kan se i den officielle dokumentation.
Partitionering
-
Tillad beskæring af partitioner og partitionsvise sammenføjninger i flere tilfælde
-
Understøtter rækkeniveau FØR udløsere på partitionerede tabeller
-
Tillad at opdelte tabeller logisk replikeres via udgivelse
-
Tillad logisk replikering i partitionerede tabeller på abonnenter
-
Tillad, at variabler i hele rækken bruges i partitioneringsudtryk
Indekser
-
Gemme dubletter mere effektivt i B-træindekser
-
Tillad GiST- og SP-GiST-indekser på bokskolonner for at understøtte ORDER BY box <-> punktforespørgsler
-
Giv GIN-indekser mulighed for at håndtere mere effektivt! (NOT) klausuler i tsquery-søgninger
-
Tillad indeksoperatorklasser at tage parametre
Optimeringsværktøj
-
Forbedre optimeringsværktøjets selektivitetsestimat for indeslutnings-/match-operatører
-
Tillad at angive statistikmålet for udvidet statistik
-
Tillad brug af flere udvidede statistikobjekter i en enkelt forespørgsel
-
Tillad brug af udvidede statistikobjekter til OR-sætninger og IN/ENHVER konstant lister
-
Tillad at funktioner i FROM-sætninger trækkes op (inlinet), hvis de evalueres til konstanter
Ydeevne
-
Implementer trinvis sortering og forbedre effektiviteten af sortering af inet-værdier
-
Tillad hash-aggregering for at bruge disklager til store aggregeringsresultatsæt
-
Tillad indsættelser, ikke kun opdateringer og sletninger, for at udløse støvsugning i autovakuum
-
Tilføj parameteren maintenance_io_concurrency for at kontrollere I/O samtidighed for vedligeholdelsesoperationer
-
Tillad, at WAL-skrivninger springes over under en transaktion, der opretter eller omskriver en relation, hvis wal_level er minimal
-
Forbedre ydeevnen ved genafspilning af DROP DATABASE-kommandoer, når mange tablespaces er i brug
-
Fremskynd konvertering af heltal til tekst
-
Reducer hukommelsesforbruget til forespørgselsstrenge og udvidelsesscripts, der indeholder mange SQL-sætninger
Overvågning
-
Tillad EXPLAIN, auto_explain, autovacuum og pg_stat_statements at spore WAL-brugsstatistikker
-
Tillad at en prøve af SQL-sætninger i stedet for alle sætninger logges
-
Tilføj backend-typen til csvlog og eventuelt log_line_prefix-logoutput
-
Forbedre kontrollen over udarbejdet sætningsparameterlogning
-
Føj leder_pid til pg_stat_activity for at rapportere en parallel arbejders lederproces
-
Tilføj systemvisning pg_stat_progress_basebackup for at rapportere status for streaming af basebackups
-
Tilføj systemvisning pg_stat_progress_analyze for at rapportere ANALYSE fremskridt
-
Tilføj systemvisning pg_shmem_allocations for at vise brugen af delt hukommelse
replikering og gendannelse
-
Tillad at konfigurationsindstillinger for streamingreplikering ændres ved genindlæsning
-
Tillad WAL-modtagere at bruge en midlertidig replikeringsplads, når en permanent ikke er angivet
-
Tillad, at WAL-lagerplads til replikeringspladser begrænses af max_slot_wal_keep_size
-
Tillad standby-promovering for at annullere enhver anmodet pause
-
Generer en fejl, hvis gendannelse ikke når det angivne gendannelsesmål
-
Tillad kontrol over, hvor meget hukommelse der bruges ved logisk afkodning, før den spildes til disken
-
Tillad gendannelsen at fortsætte, selvom der henvises til ugyldige sider af WAL
Hjælpekommandoer
-
Tillad VACUUM at behandle en tabels indekser parallelt
-
Rapportér brug af buffer til planlægningstid i EXPLAINs BUFFER-output
-
Få CREATE TABLE LIKE til at udbrede en CHECK-begrænsnings NO INHERIT-egenskab til den oprettede tabel
-
Tilføj ALTER TABLE ... DROP EXPRESSION for at tillade fjernelse af den GENEREDE egenskab fra en kolonne
-
Tilføj ALTER VIEW-syntaks for at omdøbe visningskolonner
-
Tilføj ALTER TYPE-indstillinger for at ændre en basistypes TOAST-egenskaber og støttefunktioner
-
Tilføj CREATE DATABASE LOCALE mulighed
-
Giv DROP DATABASE tilladelse til at afbryde forbindelsen mellem sessioner ved hjælp af måldatabasen, så nedlæggelsen lykkes
Og mange flere ændringer. Vi har lige nævnt nogle af dem for at undgå et større blogindlæg. Lad os nu se, hvordan du implementerer denne nye version.
Sådan implementeres PostgreSQL 13
Til dette antager vi, at du har ClusterControl installeret, ellers kan du følge den tilsvarende dokumentation for at installere det.
For at udføre en implementering fra ClusterControl skal du blot vælge indstillingen Deploy og følge instruktionerne, der vises.
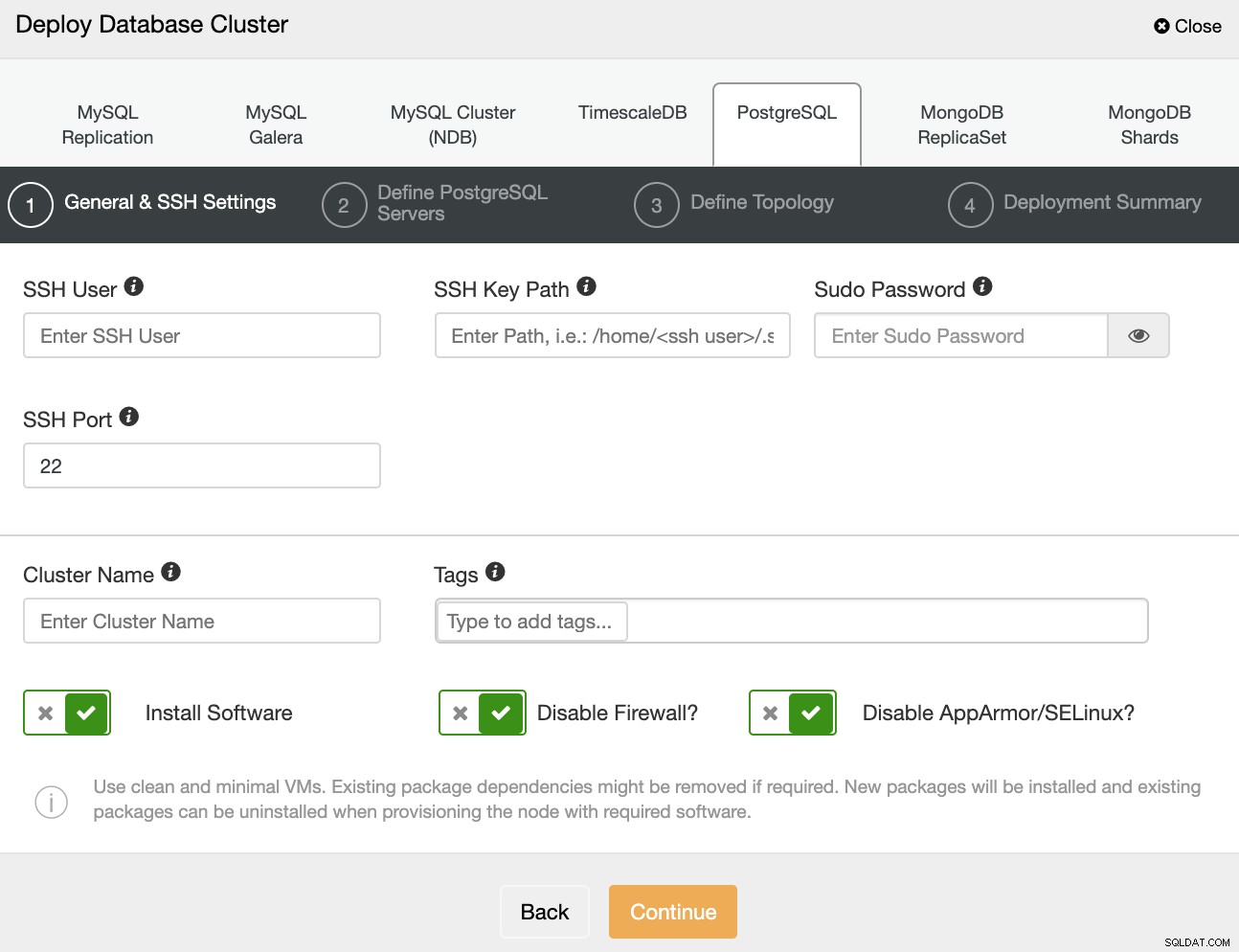
Når du vælger PostgreSQL, skal du angive bruger, nøgle eller adgangskode og port at forbinde med SSH til dine servere. Du kan også tilføje et navn til din nye klynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
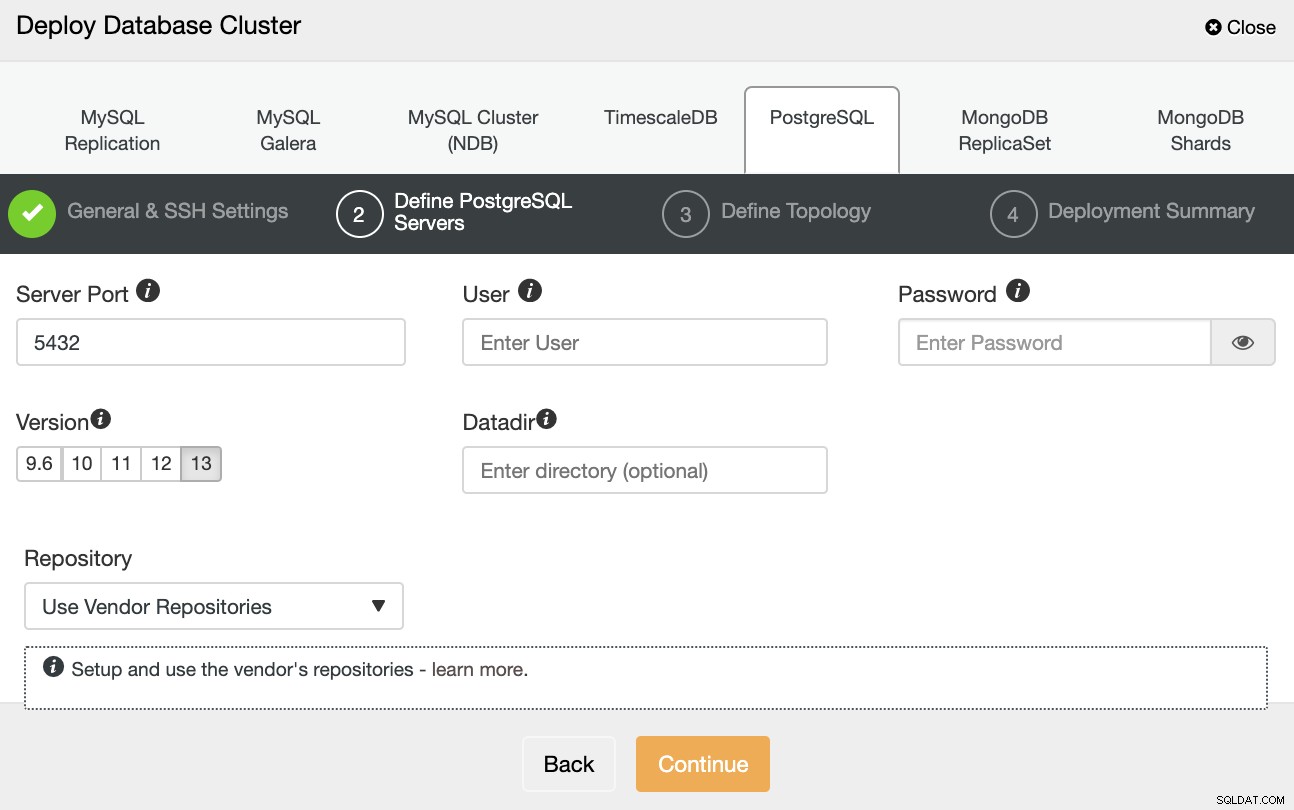
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaselegitimationsoplysningerne , version og datadir (valgfrit). Du kan også angive, hvilket lager der skal bruges.
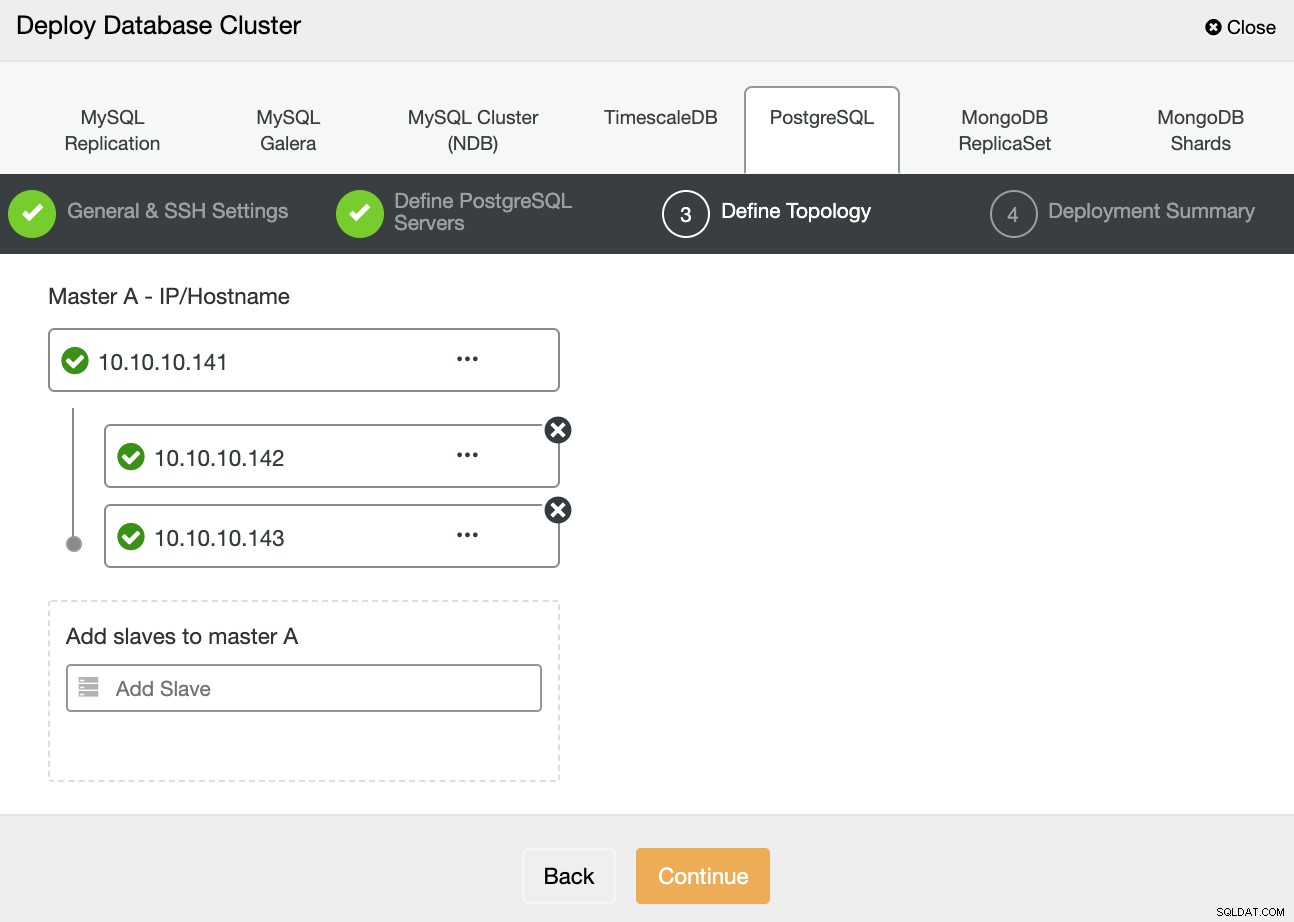
I næste trin skal du tilføje dine servere til den klynge, som du vil oprette ved hjælp af IP-adressen eller værtsnavnet.
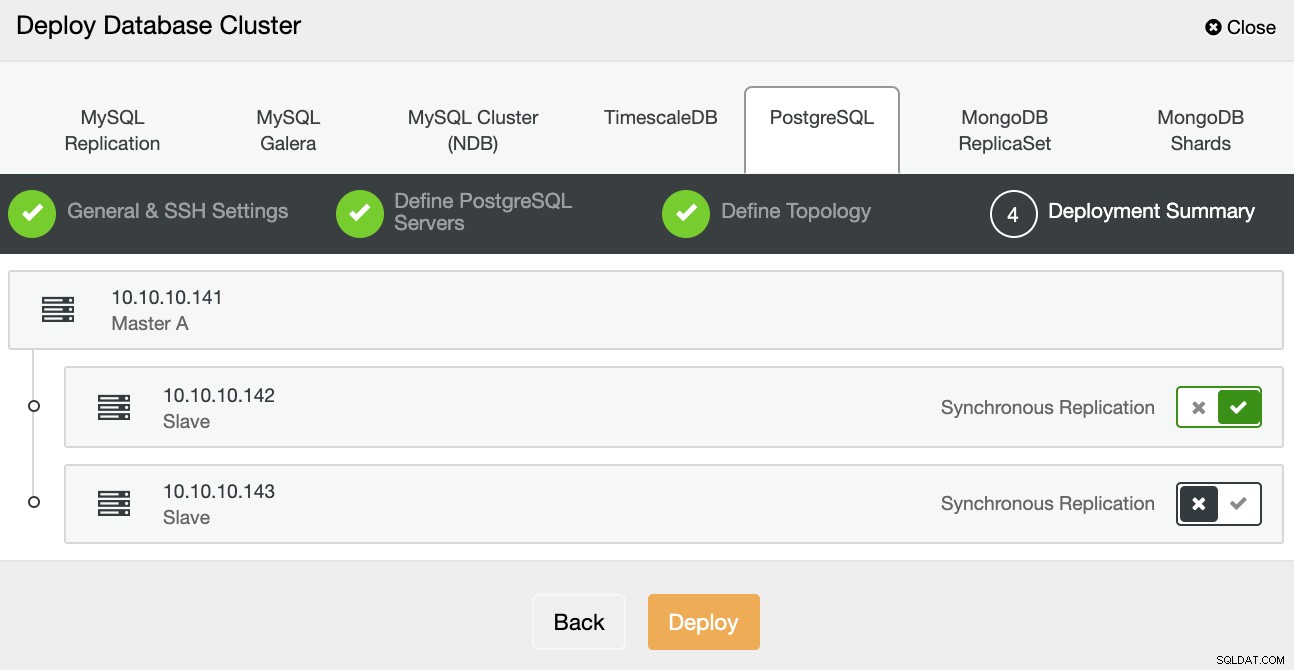
I det sidste trin kan du vælge, om din replikering skal være Synkron eller Asynkron, og tryk så bare på Deploy.
Når opgaven er færdig, kan du se din nye PostgreSQL-klynge i hovedskærmen ClusterControl.

Nu har du oprettet din klynge, du kan udføre flere opgaver på den, som at tilføje load balancere (HAProxy), forbindelsespoolere (PgBouncer) eller nye replikeringsslaver fra den samme ClusterControl UI.
Opgradering til PostgreSQL 13
Hvis du vil opgradere din nuværende PostgreSQL-version til denne nye, har du tre hovedmuligheder, som vil udføre denne opgave.
-
Pg_dump:Det er et logisk backupværktøj, der giver dig mulighed for at dumpe dine data og gendanne dem i den nye PostgreSQL version. Her vil du have en nedetidsperiode, der vil variere i henhold til din datastørrelse. Du skal stoppe systemet eller undgå nye data i den primære node, køre pg_dump, flytte det genererede dump til den nye databasenode og gendanne det. I dette tidsrum kan du ikke skrive ind i din primære PostgreSQL-database for at undgå datainkonsistens.
-
Pg_upgrade:Det er et PostgreSQL-værktøj til at opgradere din PostgreSQL-version på stedet. Det kan være farligt i et produktionsmiljø, og vi anbefaler ikke denne metode i så fald. Ved at bruge denne metode vil du også have nedetid, men sandsynligvis vil det være betydeligt mindre end ved at bruge den tidligere pg_dump-metode.
-
Logisk replikering:Siden PostgreSQL 10 kan du bruge denne replikeringsmetode, som giver dig mulighed for at udføre større versionsopgraderinger med nul (eller næsten nul) nedetid. På denne måde kan du tilføje en standby-node i den sidste PostgreSQL-version, og når replikeringen er opdateret, kan du udføre en failover-proces for at fremme den nye PostgreSQL-node.
For mere detaljeret information om de nye PostgreSQL 13-funktioner kan du se den officielle dokumentation.