Jeg starter med det andet spørgsmål, som er nemmere. Brug af dplyr pakke, kan du bruge top_n for at få de n største rækker for en given kolonne. For eksempel:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Bemærk, at du får mere end n rækker, hvis der er uafgjort til n. pladsen. Således top_n(p_ash_r_100, 10, SMPL_CNT) returnerer hele prøvedatasættet på grund af 17-vejs bindingen for 4.
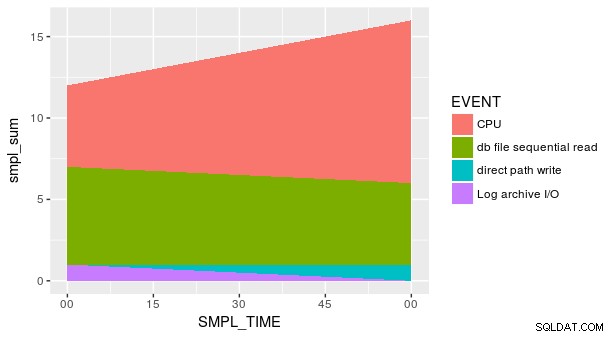
Hvad angår det første spørgsmål, dokumentationen for geom_area giver et fingerpeg:
Dette tyder på, at geom_area forventer, at kolonnen afbildet til x skal være numerisk. Baseret på fortegnelsen for p_ash_r_100 , SMPL_TIME ser ud til at være en tegnvektor. Med lubridate pakke, kan vi konvertere SMPL_TIME til en dato-tid med dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
Dette er dog ikke nok til at få det plot, du ønsker, da der er flere værdier af y for hver kombination af x og fill (hvilket er den korrekte æstetik for geom_area , ikke "col "). Vi er nødt til at opsummere dataene, før vi plotter:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
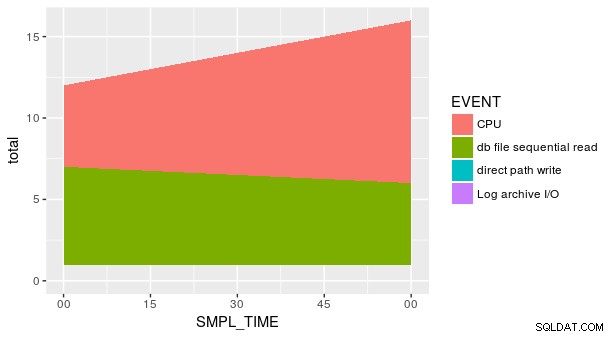
Men plottet er stadig ikke korrekt. Dette skyldes, at hver kombination af SMPL_TIME og EVENT er ikke repræsenteret i datasættet. Vi skal udtrykkeligt fortælle geom_area at y er lig med nul for de manglende rækker. En måde er at bruge den praktiske fill argument i tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()