Dette er et ganske almindeligt problem.
Almindelig B-Tree indekser er ikke gode til forespørgsler som denne:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Et indeks er godt til at søge efter værdierne inden for de givne grænser, sådan her:
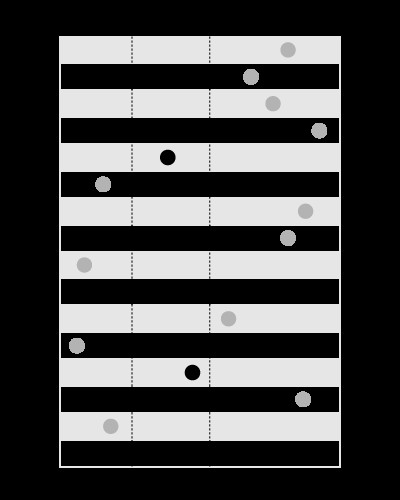
, men ikke for at søge i grænserne, der indeholder den givne værdi, som denne:
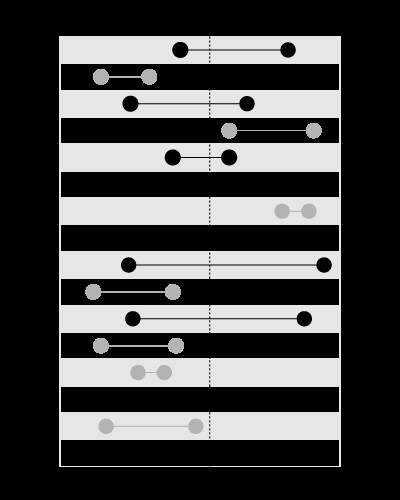
Denne artikel i min blog forklarer problemet mere detaljeret:
(den indlejrede sæt-model omhandler den lignende type prædikat).
Du kan lave indekset på time , på denne måde intervals vil være førende i sammenføjningen, vil tidsintervallet blive brugt inde i de indlejrede løkker. Dette kræver sortering på time .
Du kan oprette et rumligt indeks på intervals (tilgængelig i MySQL ved hjælp af MyISAM storage), der ville omfatte start og end i én geometrisøjle. På denne måde measures kan føre i sammenføjningen, og der vil ikke være behov for sortering.
De rumlige indekser er dog langsommere, så dette vil kun være effektivt, hvis du har få mål, men mange intervaller.
Da du har få intervaller, men mange mål, skal du bare sørge for at have et indeks på measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Opdatering:
Her er et eksempelscript, der skal testes:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Denne forespørgsel:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
bruger NESTED LOOPS og returnerer i 1.7 sekunder.
Denne forespørgsel:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
bruger MERGE JOIN og jeg var nødt til at stoppe det efter 5 minutter.
Opdatering 2:
Du bliver højst sandsynligt nødt til at tvinge motoren til at bruge den korrekte tabelrækkefølge i joinforbindelsen ved at bruge et tip som dette:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle 's optimizer er ikke smart nok til at se, at intervallerne ikke krydser hinanden. Det er derfor, det højst sandsynligt vil bruge measures som en ledende tabel (hvilket ville være en klog beslutning, hvis intervallerne krydser hinanden).
Opdatering 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Denne forespørgsel opdeler tidsaksen i intervallerne og bruger en HASH JOIN for at sammenføje målene og tidsstemplerne på områdeværdierne med finfiltrering senere.
Se denne artikel i min blog for mere detaljerede forklaringer på, hvordan det virker: