Vi undersøger migrering af en Oracle-database fra en EC2-instans til en administreret RDS-tjeneste. I den første af fire artikler, "Migrering af en Oracle-database fra AWS EC2 til AWS RDS, del 1", oprettede vi databaseforekomster på EC2 og RDS. I den anden artikel, "Migrering af en Oracle-database fra AWS EC2 til AWS RDS, del 2", oprettede vi en IAM-bruger til databasemigrering og oprettede også en databasetabel til at migrere. Kun i den anden artikel oprettede vi en replikeringsinstans og replikeringsslutpunkter. I den tredje artikel, "Migrering af en Oracle-database fra AWS EC2 til AWS RDS, del 3", oprettede vi en migreringsopgave for at migrere eksisterende ændringer. I denne fortsættelsesartikel migrerer vi løbende ændringer af data. Denne artikel har følgende sektioner:
- Oprettelse og kørsel af en replikeringsopgave for at migrere igangværende ændringer
- Tilføjelse af supplerende logning
- Tilføjelse af en tabel til en Oracle-databaseinstans på EC2
- Tilføjelse af tabeldata
- Udforsker den replikerede databasetabel
- Slip og genindlæsning af data
- Stop og start af en opgave
- Sletning af databaser
- Konklusion
Oprettelse og kørsel af en replikeringsopgave for at migrere igangværende ændringer
I de følgende underafsnit skal vi oprette en opgave for at replikere igangværende ændringer. For at demonstrere igangværende replikering skal vi først starte opgaven og efterfølgende oprette en tabel og tilføje data. Slip tabellen DVOHRA.WLSLOG som vist i figur 1; vi skal skabe den samme tabel for at demonstrere igangværende replikering.

Figur 1: Sliptabel DVOHRA.WLSLOG
Tilføjelse af supplerende logning
Databasemigrationstjeneste kræver, at supplerende logning aktiveres for at aktivere ændringsdatafangst (CDC), der bruges til at replikere igangværende ændringer. Supplerende logning er processen med at gemme information om, hvilke rækker af data i en tabel, der er ændret. Supplerende logning tilføjer supplerende eller ekstra kolonnedata i redologfiler, når der udføres en opdatering af en tabel. De kolonner, der har ændret sig, registreres som supplerende data i redologfiler sammen med en identificerende nøgle, som kunne være den primære nøgle eller det unikke indeks. Hvis en tabel ikke har en primær nøgle eller et unikt indeks, registreres alle skalære kolonner i redologfilerne for entydigt at identificere en række data, hvilket kan gøre gentaglogfilerne store i størrelse. Oracle Database understøtter følgende former for supplerende logning:
- Minimal supplerende logning: Kun den minimale mængde data, der kræves af LogMiner til DML-ændringerne, registreres i logfiler for omdanning.
- Nøglelogning for identifikation af databaseniveau: Forskellige former for identifikationsnøglelogning på databaseniveau er understøttet - ALLE, PRIMÆR NØGLE, UNIK og UDENLANDSKE NØGLE. Med ALL-niveauet registreres alle kolonner (undtagen LOB'er, Longs og ADT'er) i redologfiler. For PRIMÆR NØGLE er det kun primærnøglekolonner, der gemmes i gentag-logfiler, når en række, der indeholder en primærnøgle, opdateres; det er ikke påkrævet, at en primær nøglekolonne opdateres. FOREIGN KEY-typen gemmer kun fremmednøglerne i en række i redologfiler, når nogen af de røde logfiler opdateres. Den UNIQUE-type gemmer kun kolonnerne i en unik sammensat nøgle eller bitmapindeks, når en kolonne i den unikke sammensatte nøgle eller bitmapindeks er ændret.
- Supplerende logning på tabelniveau: Angiver på tabelniveau, hvilke kolonner der er gemt i redologfiler. Logning af identifikationsnøgler på tabelniveau understøtter de samme niveauer som ved logning af identifikationsnøgle på databaseniveau; ALLE, PRIMÆR NØGLE, UNIK og UDENLANDSKE NØGLE. På tabelniveau understøttes også brugerdefinerede supplerende loggrupper, som lader en bruger definere, hvilke kolonner der skal logges supplerende. De brugerdefinerede supplerende loggrupper kan være betingede eller ubetingede.
For løbende replikering skal vi indstille minimal supplerende logning og supplerende logning på tabelniveau for ALLE kolonner.
I SQL*Plus skal du køre følgende sætning for at indstille minimal supplerende logning:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Outputtet er som følger:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; Database altered.
Kør følgende sætning for at finde status for den minimale supplerende logning. Og hvis output har en SUPPLEME-kolonneværdi som JA, er minimal supplerende logning aktiveret.
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- YES
Indstilling af minimal supplerende logning og verifikation af statusoutput er vist i figur 2.
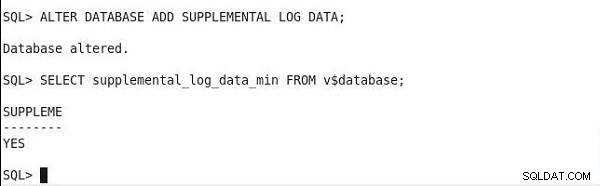
Figur 2: Indstilling og verifikation af minimal supplerende logning
Vi vil også indstille identifikationsnøglelogning på tabelniveau, når vi tilføjer tabel- og tabeldata for at demonstrere igangværende replikering efter opgaven er startet. Hvis vi tilføjer tabel- og tabeldata, før vi opretter og starter en opgave, vil vi ikke være i stand til at demonstrere igangværende replikering.
For at oprette en opgave til løbende replikering skal du klikke på Opret opgave , som vist i figur 3.

Figur 3: Opgaver>Opret opgave
I Opret opgave guiden, angiv et opgavenavn og en beskrivelse, og vælg replikeringsforekomsten, kildeslutpunktet og målslutpunktet, som vist i figur 4. Vælg Migreringstype som Migrer eksisterende data og repliker igangværende ændringer .
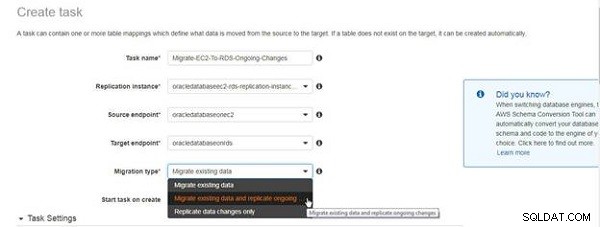
Figur 4: Valg af migreringstype til løbende replikering
En meddelelse vist i figur 5 indikerer, at supplerende logning er påkrævet for at blive aktiveret for løbende replikering. Meddelelsen skal ikke angive, at supplerende logning ikke er blevet aktiveret, men kun som en påmindelse. Vi har allerede aktiveret supplerende logning. Marker afkrydsningsfeltet Start opgave ved oprettelse .
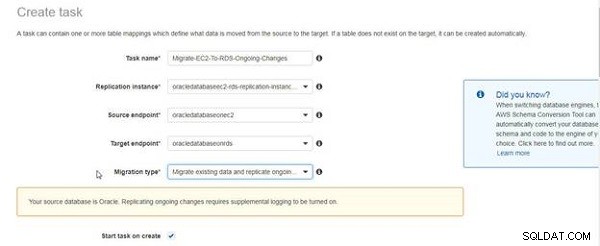
Figur 5: Besked om supplerende logføringskrav til replikering af igangværende ændringer
Opgaveindstillinger er de samme som kun for migrering af eksisterende data (se figur 6).
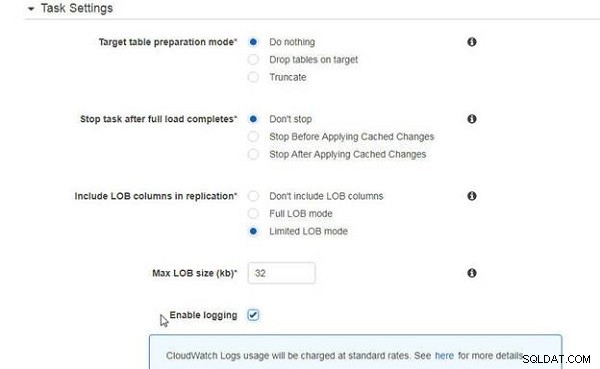
Figur 6: Opgaveindstillinger
Til tabelkortlægninger kræves mindst én udvælgelsesregel. Tilføj en udvælgelsesregel for at inkludere alle tabeller i DVOHRA tabel, som vist i figur 7.
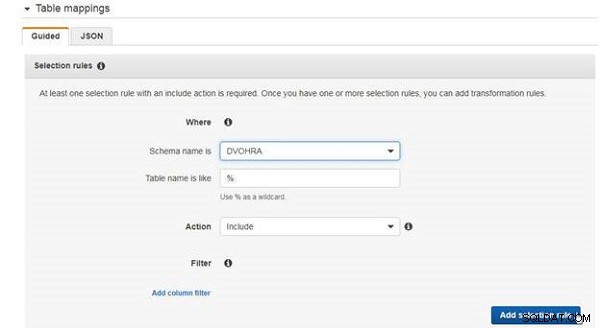
Figur 7: Tilføjelse af en udvælgelsesregel
Den tilføjede valgregel er vist i figur 8.
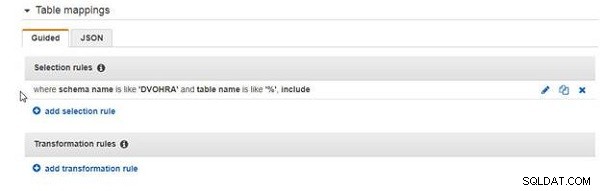
Figur 8: Udvælgelsesregel
Klik på Opret opgave for at oprette opgaven, som vist i figur 9.
Figur 9: Opret opgave
En ny opgave tilføjes med status som Opretter , som vist i figur 10.

Figur 10: Opgave tilføjet med status Opretter
Når udvælgelses- og transformationsreglerne for alle eksisterende data er blevet anvendt og data migreret, bliver opgavestatus Indlæsning fuldført, replikering igangværende (se figur 11).

Figur 11: Indlæsningen er fuldført, replikering er i gang
Tabelstatistik fanen viser ingen tabeller, der er migreret eller replikeret, som vist i figur 12.
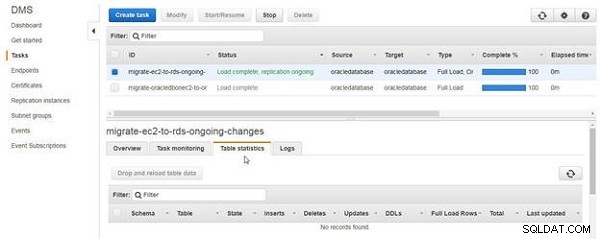
Figur 12: Tabel statistik
For at udforske CloudWatch-logfilerne skal du klikke på Logge fanen og klik på linket, som vist i figur 13.
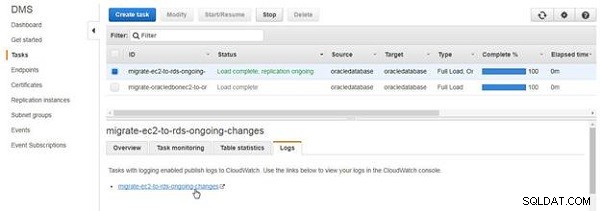
Figur 13: Logfiler
CloudWatch-loggene bliver vist, som vist i figur 14. Den sidste post i loggene handler om at starte replikering. Den igangværende replikeringsopgave afsluttes ikke efter indlæsning af eksisterende data, hvis nogen, men fortsætter med at køre.
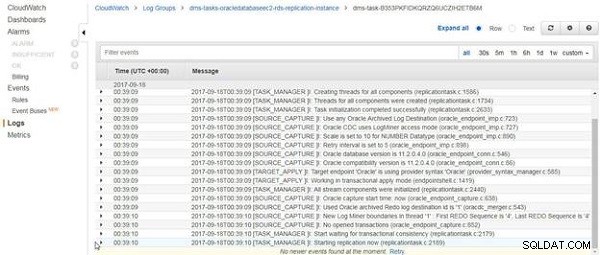
Figur 14: CloudWatch-logfiler
Tilføjelse af en tabel til en Oracle-databaseinstans på EC2
Derefter skal du oprette en tabel og tilføje tabeldata for at demonstrere igangværende replikering. Kør følgende to sætninger sammen, så supplerende logning på tabelniveau indstilles, når tabellen oprettes. Rediger scriptet for at gøre skemaet anderledes.
CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY, category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns;
Den supplerende logning på tabelniveau indstilles, når tabellen oprettes.
SQL> CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY,category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns; Table created. SQL> Table altered.
Outputtet er vist i SQL*Plus i figur 15.
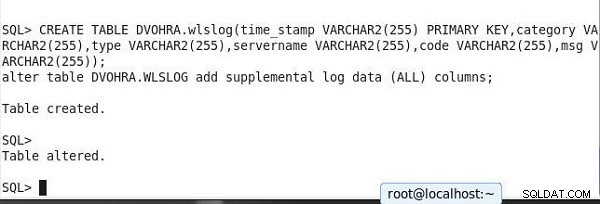
Figur 15: Oprettelse af tabel og indstilling af supplerende logning
Indtil videre har vi kun oprettet tabellen og ikke tilføjet nogen tabeldata. DDL for tabellen bliver migreret, som angivet af tabelstatistikken i figur 16.
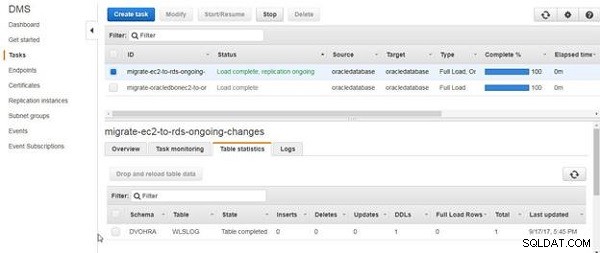
Figur 16: DDL'er til tabel migreret
Tilføjelse af tabeldata
Kør derefter følgende SQL-script for at tilføje data til den oprettede tabel. Rediger scriptet for at gøre skemaet anderledes.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:16-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000365','Server
state changed to STANDBY');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to STARTING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:18-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to ADMIN');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:19-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RESUMING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:20-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000361','Started WebLogic
AdminServer');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:21-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RUNNING');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
Kør derefter Commit-erklæringen.
SQL> COMMIT; Commit complete.
Udforsker den replikerede databasetabel
Tabelstatistikken viser indsættelser som antallet af tilføjede rækker af data, som vist i figur 17.
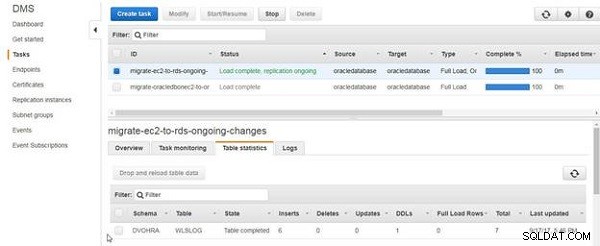
Figur 17: Tabelstatistikliste 6 Indsæt
Opgaven fortsætter med at køre efter replikering af igangværende ændringer. Tilføj endnu en række data.
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:22-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000360','Server
started in RUNNING mode');
1 row created.
SQL> COMMIT;
Commit complete.
SQL>
Klik på Opdater data fra server, som vist i figur 18.
Figur 18: Opdater data fra serveren
Det samlede antal indstik i tabelstatistikken bliver 7, som vist i figur 19.
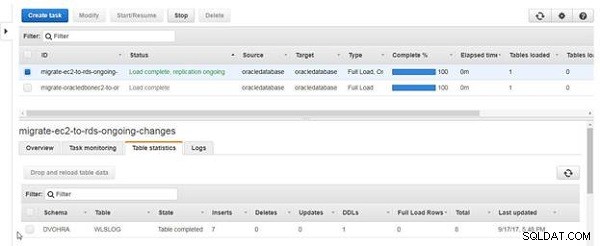
Figur 19: Tabelstatistik med Indsæt som 7
Slip og genindlæsning af data
Klik på Slip og genindlæs tabeldata for at slippe og genindlæse tabeldata , som vist i figur 20.
Figur 20: Slip og genindlæs tabeldata
Klik på Opdater data fra server (se figur 21).
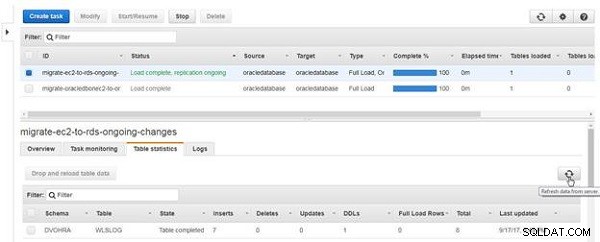
Figur 21: Opdater data fra serveren
Ikonet og State kolonne for tabellen angiver, at tabellen genindlæses, som vist i figur 22.
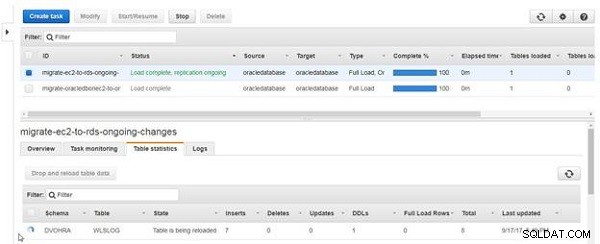
Figur 22: Tabellen genindlæses
Når tabelgenindlæsningen er fuldført, bliver tabeltilstandskolonnen Tabel gennemført , som vist i figur 23. Efter genindlæsning af tabeldata vil Fuld Load Rows viser en værdi på 7, og Inserts er 0, fordi en genindlæsning ikke er igangværende replikering, men en fuld load.
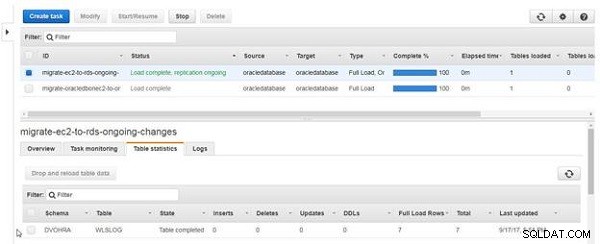
Figur 23: Genindlæsning af tabel fuldført
Fordi tabeldataene slettes og genindlæses, og kildetabeldataene ikke er ændret, indeholder CloudWatch-logfilerne en meddelelse "Nogle ændringer fra kildedatabasen havde ingen indflydelse, når de blev anvendt på måldatabasen.", som vist i figur 24.
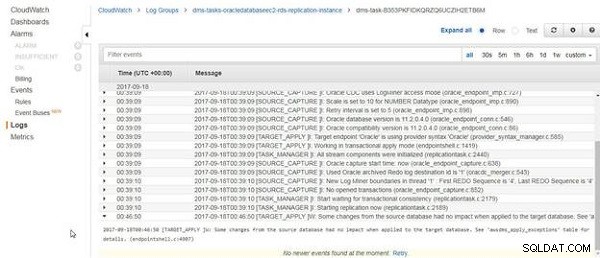
Figur 24: Nogle ændringer fra kildedatabasen havde ingen indflydelse, når de blev anvendt på måldatabasen
Når genindlæsningen af DVOHRA.wlslog tabel er afsluttet, meddelelsen "Load færdig for tabel DVOHRA.wlslog. 7 rækker modtaget" bliver vist, som vist i figur 25.
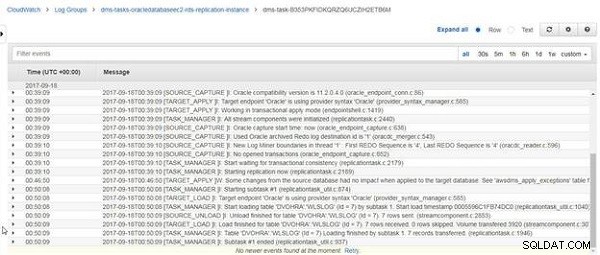
Figur 25: CloudWatch-logmeddelelse for indlæsning er afsluttet
Stop og start af en opgave
En opgave af den type, der inkluderer løbende replikering, stopper ikke af sig selv, medmindre der opstår en fejl. Klik på Stop for at stoppe opgaven (se figur 26).
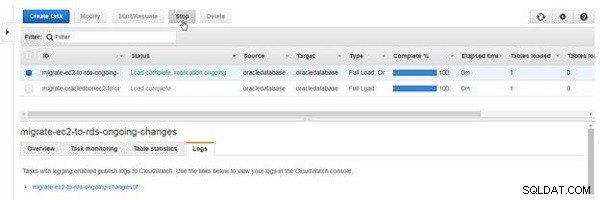
Figur 26: Stop en opgave
I Stop-opgave dialogboks skal du klikke på Stop , som vist i figur 27.
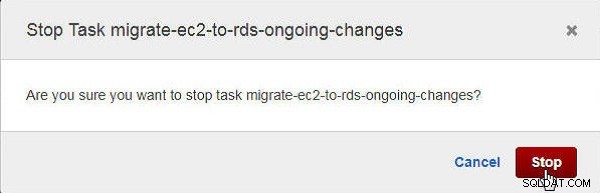
Figur 27: Bekræftelsesdialog for at stoppe en opgave
Opgavestatus bliver Stopper , som vist i figur 28.
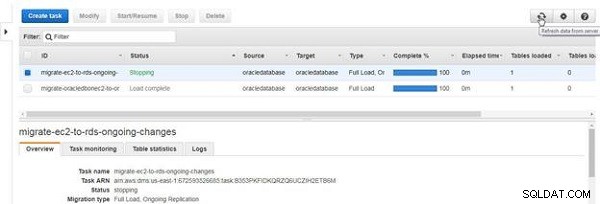
Figur 28: Stop en opgave
Når en opgave stopper, bliver status Stoppet , som vist i figur 29.
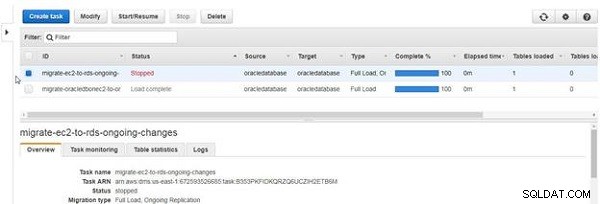
Figur 29: Opgave stoppet
For at starte en stoppet opgave skal du klikke på Start/Genoptag , som vist i figur 30.
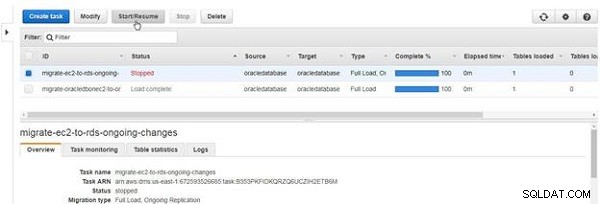
Figur 30: Start eller genoptagelse af en opgave
I Start opgave dialogboksen skal du klikke på Start for at starte opgaven fra det stoppede punkt (se figur 31). Den anden mulighed er at genstarte opgaven.
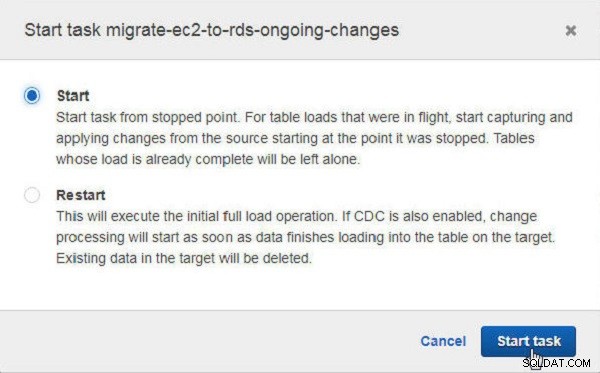
Figur 31: Startopgave efter stop
Opgavestatus bliver Starter , som vist i figur 32.

Figur 32: Start af en opgave
Når migreringen af eksisterende data er fuldført, fortsætter opgaven med at køre med status som Indlæsning fuldført, replikering igangværende , som vist i figur 33.

Figur 33: Indlæsningen er fuldført, replikering er i gang
Sletning af databaser
RDS DB-instansen kan slettes med Forekomsthandlinger>Slet kommando. Oracle-databasen på EC2-instansen kan stoppes med Actions>Instance State>Stop , som vist i figur 34.

Figur 34: Stopper EC2-instans
Konklusion
I fire artikler diskuterede vi migrering af en Oracle-database fra AWS EC2 til AWS RDS.