
Dette indlæg er en del af Oracle SQL tutorial, og vi vil diskutere analytiske funktioner i Oracle (Over af partition) med eksempler, detaljeret forklaring.
Vi har allerede studeret om Oracle Aggregate-funktion som avg, sum, count. Lad os tage et eksempel
Lad os først oprette prøvedataene
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Nu vil eksemplet på aggregerede funktioner blive givet som nedenfor
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Her kan vi se, at det reducerer antallet af rækker i hver af forespørgslerne. Nu kommer spørgsmålene, hvad vi skal gøre, hvis vi også skal have alle rækkerne returneret med count(*)
For det orakel har leveret et sæt analytiske funktioner. Så for at løse det sidste problem kan vi skrive som
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
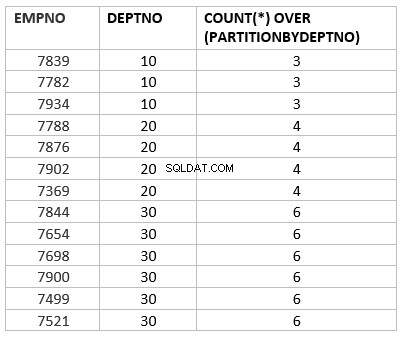
Her er count(*) over (partition af dept_no) den analytiske version af count aggregate-funktionen. Hovednøglearbejdet, som er forskelligt efter aggregeret funktion, er over partition af
Analytiske funktioner beregner en aggregeret værdi baseret på en gruppe rækker. De adskiller sig fra aggregerede funktioner ved, at de returnerer flere rækker for hver gruppe. Gruppen af rækker kaldes et vindue og er defineret af analytic_clause.
Her er den generelle syntaks
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Eksempel
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Lad os gennemgå hver del
query_partition_clause
Det definerede gruppen af rækker. Det kan lide nedenfor
partition efter deptno :gruppe af rækker af samme deptno
eller
() :Alle rækker
SQL> select empno ,deptno , count(*) over () from emp;
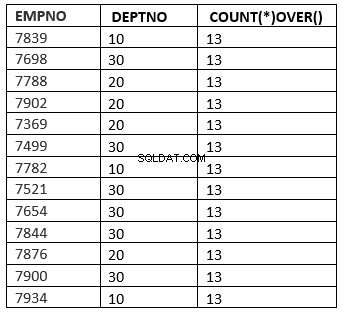
[ rækkefølge_efter_klausul [ vinduesklausul ] ]
Denne klausul bruges, når du vil bestille rækkerne i partitionen. Dette er især nyttigt, hvis du vil have analytisk funktion til at overveje rækkefølgen af rækkerne.
Eksempel vil være rækkenummer-funktionen
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
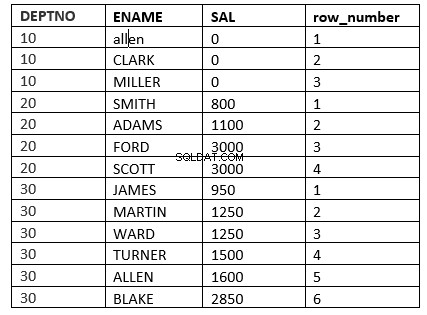
Et andet eksempel ville være
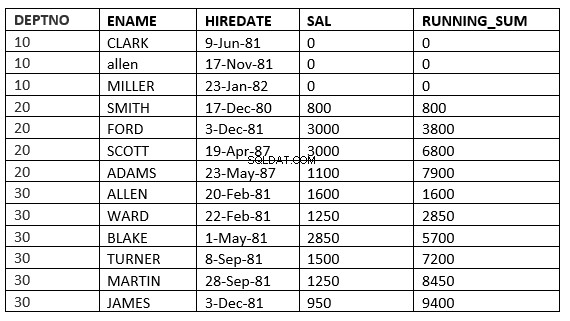
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
Dette bruges altid med orden efter klausul og giver mere kontrol over rækkerne i gruppen
Med Windowing-klausul er der defineret et glidende vindue af rækker for hver række. Vinduet bestemmer rækkevidden af rækker, der bruges til at udføre beregningerne for den aktuelle række. Vinduesstørrelser kan være baseret på enten et fysisk antal rækker eller et logisk interval såsom tid.
Når du bruger orden efter klausul, og der ikke er angivet noget for windowing_clause, tages under standardværdien af windowing_clausule
RANGE MELLEM UNBOUNDED PRECEDING OG CURRENT ROW eller RANGE UNBOUNDED PRECEDING
Det betyder "Den aktuelle og forrige række i den aktuelle partition er de rækker, der skal bruges i beregningen"
Eksemplet nedenfor viser dette tydeligt. Dette er det løbende gennemsnit i afdelingen
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Nu kan windowing_clause defineres på flere måder
Lad os først forstå terminologien
RÆKKER angiver vinduet i fysiske enheder (rækker).
RANGE angiver vinduet som en logisk offset. RANGE-vinduessætningen kan kun bruges med ORDER BY-sætninger, der indeholder kolonner eller udtryk af numeriske eller datodatatyper
PRECEDING – få rækker før den nuværende.
FØLGER – få rækker efter den nuværende.
UNGRENSEDE – når den bruges med PRECEDING eller FOLLOWING, vender den tilbage før eller efter. NUVÆRENDE RÆKKE
Så det er generelt defineret som
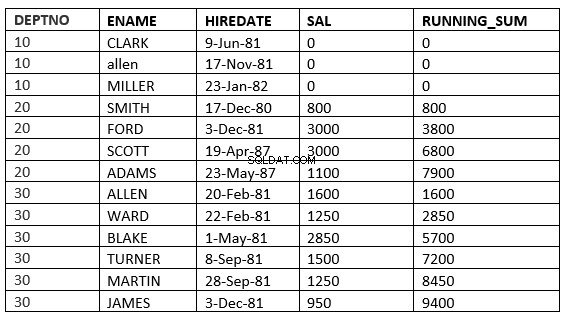
RÆKKER UBEGRÆNSET FOREGÅENDE :Den nuværende og forrige række i den aktuelle partition er de rækker, der skal bruges i beregningen
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
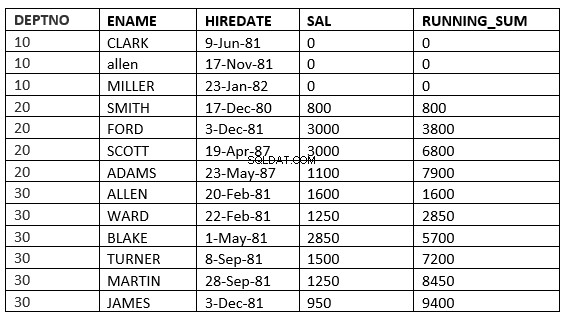
OMRÅDE UBEGRÆNSET FOREGÅENDE :Den nuværende og forrige række i den aktuelle partition er de rækker, der skal bruges i beregningen. Da området er angivet, tager det alle de værdier, der er lig med de aktuelle rækker.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
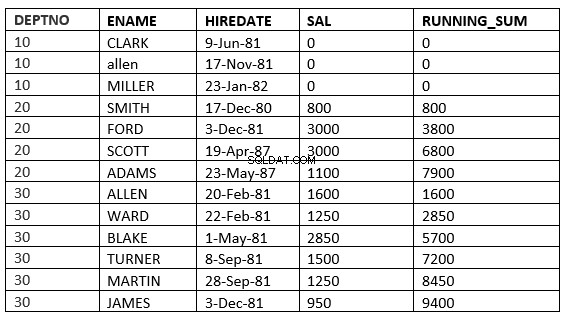
Du kan muligvis ikke se forskellen mellem interval og rækker, da leje_dato er forskellig for alle. Forskellen bliver mere tydelig, hvis vi bruger sal som orden efter klausul
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
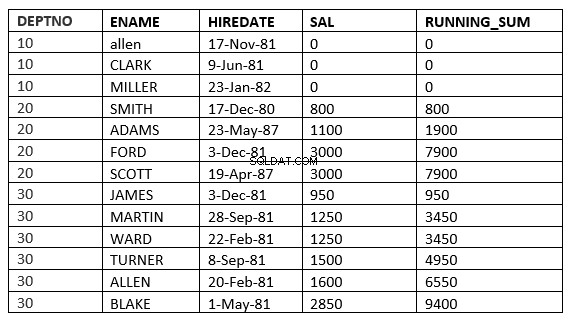
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
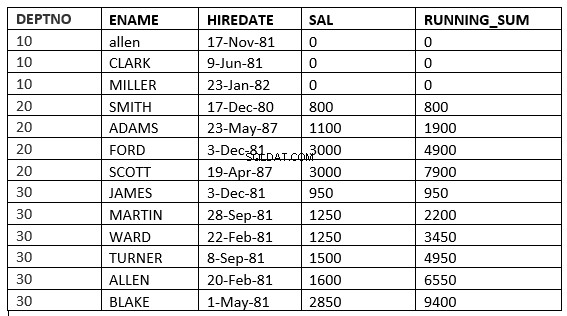
Du kan finde forskellen på linje 6
RANGE value_expr PRECEDING :Vinduet begynder med rækken, hvis ORDER BY-værdi er numeriske udtryksrækker mindre end eller foran den aktuelle række og slutter med den aktuelle række, der behandles.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
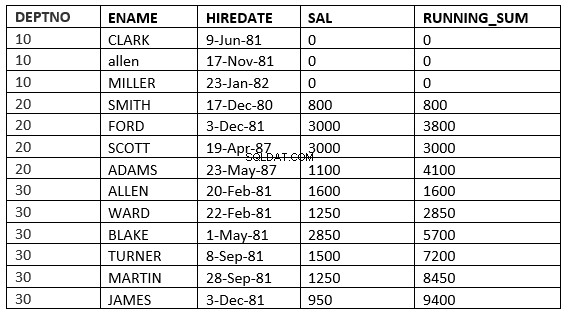
Her tager det alle de rækker, hvor lejedatoværdien falder inden for 365 dage før lejedatoværdien for den aktuelle række
ROWS value_expr PRECEDING :Vinduet begynder med den angivne række og slutter med den aktuelle række, der behandles
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
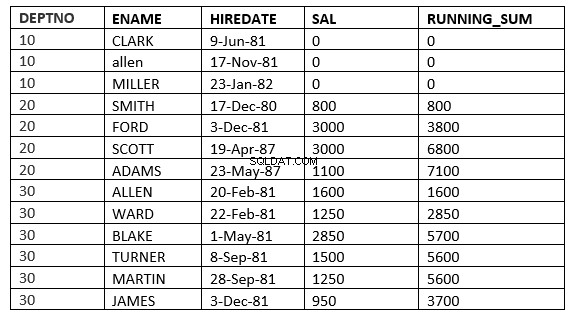
Her starter vinduet fra 2 rækker forud for den aktuelle række
OMRÅDE MELLEM AKTUEL RÆKKE og værdi_udt. FØLGENDE :Vinduet begynder med den aktuelle række og slutter med den række, hvis ORDER BY-værdi er numeriske udtryksrækker mindre end eller følgende
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
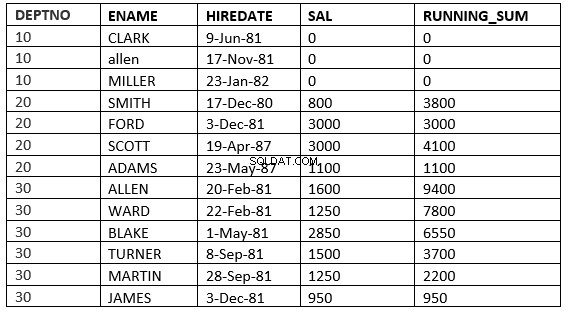
RÆKKER MELLEM AKTUELLE RÆKKE og værdi_udt. FØLGENDE :Vinduet begynder med den aktuelle række og slutter med rækkerne efter den aktuelle
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
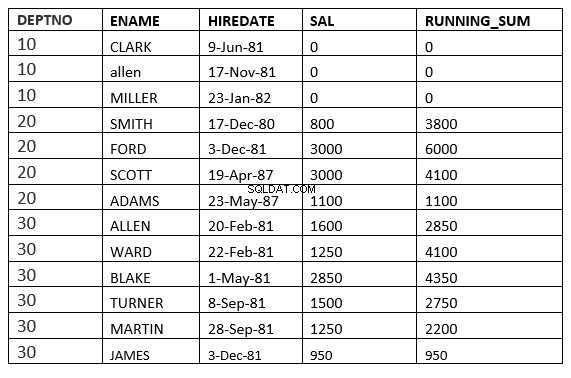
OMRÅDE MELLEM UBEGRÆNSET FOREGÅENDE og UBEGRÆNSET FØLGENDE
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
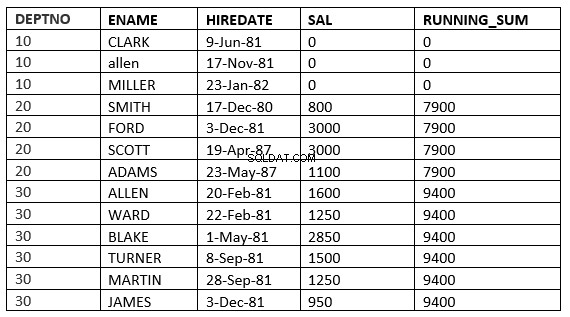
RANGE MELLEM value_expr PRECEDING og value_expr FOLLOWING
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Nogle vigtige bemærkninger
(1)Analytiske funktioner er det sidste sæt af operationer, der udføres i en forespørgsel, bortset fra den sidste ORDER BY-klausul. Alle joins og alle WHERE-, GROUP BY- og HAVING-sætninger er afsluttet, før de analytiske funktioner behandles. Derfor kan analytiske funktioner kun vises i den valgte liste eller ORDER BY-klausulen.
(2)Analytiske funktioner bruges almindeligvis til at beregne kumulative, flyttende, centrerede og rapporterende aggregater.
Jeg håber, du kan lide denne detaljerede forklaring af analytiske funktioner i oracle (over af partitionsklausul)
Relaterede artikler
LEAD-funktion i Oracle
DENSE-funktion i Oracle
Oracle LISTAGG-funktion
Aggregering af data ved hjælp af gruppefunktioner
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm