Vi er ofte nødt til at finde og slette duplikerede rækker fra Oracle-tabellen på grund af mange årsager i databasen. Vi er nødt til at slette for at fjerne dataproblemerne ofte. Der er mange måder at slette duplikerede rækker på, men behold originalen. Jeg ville vise nogle hurtigere metoder til at opnå det i dette indlæg. Jeg vil vise metoden hvor rowid bruges og metode hvor rowid ikke bruges. Bemærk venligst, at du skal identificere alle de kolonner der gør rækken til en dublet i tabellen og angive alle disse kolonner i den relevante delete-sætning i SQL
Sådan sletter du dublerede rækker fra Oracle
Her er nogle af måderne til at slette duplikerede rækker på en nem måde
(A) Hurtig metode, men du skal genskabe alle orakelindekser, triggere
create table my_table1 as select distinct * from my_table; drop my_table; rename my_table1 to my_table;
Eksempel
SQL> select * from mytest;ID NAME------1 TST2 TST1 TSTSQL> create table mytest1 as select distinct * from mytest; Table created. SQL> select * from mytest1;ID NAME-------2 TST1 TSTSQL> drop table mytest; Table dropped. SQL> rename mytest1 to mytest; Table renamed. SQL> select * from mytest;ID NAME-------2 TST1 TST
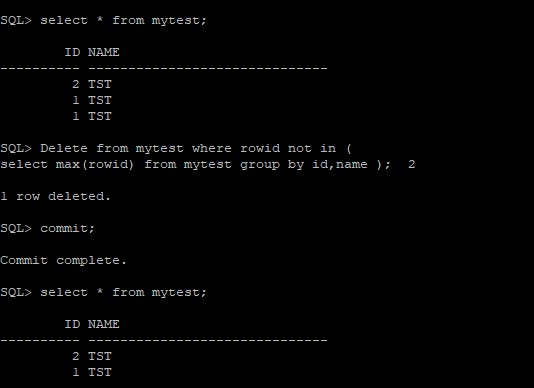
(B) Sådan finder og sletter du dublerede poster i oracle ved hjælp af rowid. Nedenstående eksempel viser en kolonne. Hvis du har slettet baseret på to kolonner, kan du angive to kolonner
Delete from my_table where rowid not in ( select max(rowid) from my_table group by my_col_name );
(C) Brug Oracle-selv-join til at slette dublerede rækker
DELETE FROM my_table A WHERE ROWID > (SELECT min(rowid) FROM my_table B WHERE A.key_values = B.key_values);
(D) Brug eksisterer klausul
delete from my_table t1 where exists (select 'x' from my_table t2 where t2.key_value1 = t1.key_value1 and t2.key_value2 = t1.key_value2 and t2.rowid > t1.rowid);
(E) slet duplikerede poster ved at bruge oracle analytiske funktioner
delete from my_table where rowid in (select rid from ( select rowid rid, row_number() over (partition by column_name order by rowid) rn from my_table) where rn <> 1 )
Så som vist er der mange måder at slette duplikerede rækker i tabellerne på. Disse kommandoer kan være nyttige i mange situationer og kan bruges afhængigt af kravet. Sørg altid for, at vi har backup tilgængelig, før du udfører nogen sætninger. Vi bør også først finde duplikatet ved hjælp af forespørgslen og derefter bekræfte det, før vi begår det
hvordan man finder duplikerede poster i Oracle ved hjælp af rowid
select * from my_table
where rowid not in
(select max(rowid) from my_table group by column_name);
Så find først duplikatet ved hjælp af ovenstående forespørgsel, slet det og sletningsantallet skal være det samme som rækkeantallet af forespørgslen ovenfor. Kør nu find dubletforespørgslen igen. Hvis der ikke er nogen dublet, er vi gode til at forpligte
Se venligst nedenstående artikel for at dykke i Sql
Oracle Sql tutorials:Indeholder listen over alle de nyttige Oracle sql artikler. Udforsk dem for at lære om Oracle SQL, selvom du kender Oracle SQL
Oracle-interviewspørgsmål :Tjek denne side for de 49 bedste Oracle-interviewspørgsmål og -svar:Grundlæggende , Oracle SQL til at hjælpe dig i interviews.Der findes også yderligere materiale
where-sætning i Oracle :Begrænsning af datasættet, where-sætning, hvad er where-sætning i sql-sætning, sammenligningsoperatørens
enkeltrække-funktioner i Oracle:Tjek dette for at finde ud af Enkeltrække-funktioner i sql, Oracle-data funktioner,Numeriske funktioner i sql,Tegnfunktion i sql
oracle sql-forespørgsler
blog.oracle.com